By John Hammink
Jan 07, 2021Considerations when moving your Apache Kafka to the cloud
Migrating Kafka from on-prem to cloud isn’t just a ‘lift-and-shift’.


Are you running your organization's Apache Kafka on-premise?
If you are and you’re still reading this article, it’s more than likely that Kafka is or will be a keystone of your data infrastructure. But it’s also likely your teams are tired of the cost and complexity required to scale it, meaning your honeymoon with Kafka is coming to an end.
So what does the imminent migration mean?
Moving Kafka to the cloud gives you a chance to refresh and modernize how data is delivered to your business and adopt DataOps practices.
Wouldn't it be great to be able to free up your attention by helping business users build real-time applications themselves?
Having a managed, monitorable Kafka-based infrastructure in the cloud can eliminate many of your day-to-day concerns and vastly simplify management, for greater focus on building applications.
In this piece, we'll look at what you need to consider when moving your Apache Kafka to the cloud. This is based on experience with companies running managed Kafka services — everything from AWS MSK and Aiven to Confluent Cloud.
Firstly, it's useful to look at Kafka’s footprint in your organization.
How is your organization using Kafka to drive revenue? Where in the puzzle does Kafka fit? And what happens if Kafka isn't there? Is Kafka essential to your business or is it secondary?

If you didn't move straight to a managed Kafka service, then you've already poured time and money into it.
So what would a move to the cloud mean? What are the higher value tasks your team can focus on? Will you take the opportunity to adopt new DataOps practices? What about existing assets & tools? Would you migrate everything at once, or certain applications in increments?
One thing is certain; moving Kafka to the cloud will accelerate adoption of your real-time services.
This is no longer a POC, nor can you treat Kafka as a lift and shift - it’s a strategic commitment. How to build a roadmap determining which teams and projects to onboard for the coming years? And then implement scalable best practices that not only serve you today, but still work with 100x the number of use cases?
This will mean having foresight on future compliance requirements, user skill sets (e.g. supporting both agile and DevOps teams and legacy app teams) and budget.
As a platform engineer, your primary concerns will now be:
Managing costs
Reducing tech debt
Reducing risk and ensuring business continuity
Ensuring productivity
Delegating governance & introducing self-service
Reducing dependence on engineering
Giving self-service data access
A successful Kafka cloud migration will lead to faster adoption of real-time applications and data, resulting in more users, all needing answers to new questions:
Where did the data come from?
Who owns it?
What service level does it have?
How can I access it?
How is it structured?
For metadata management, take the opportunity to introduce a data catalog.
If you run Kafka yourself, you have full control to tune your environment. With a high level of Kafka expertise, this can work to your advantage but will cost you in time spent keeping up with Kafka best practices.
This is one of the fundamental trade-offs when moving to the cloud. Kafka providers will offer little autonomy to customize. For 95% of use cases, this isn’t a bad thing. Like an Apple Mac with no screws, you can’t open it up but it works just great.
To give a very specific example, there may be times when you'd like to have more control over your partitioning strategy than your vendor allows.
Do your topics' consumers need to aggregate by a specific data attribute?
Do your consumers need some sort of ordering guarantee?
Are there bottlenecks (network or CPU) related to sharding data?
Do you want to concentrate data for storage efficiency or indexing?
Partitioning isn't the only customized setting you might need. Here are some others:
Will you need access to Zookeeper?
Will you need JMX metrics?
Will you need to configure custom ADV_HOST or other .properties file settings?
Do you need to do OS-level tuning on your Kafka nodes?
In a lot of ways, choosing an Apache Kafka managed service is the same as choosing any other SaaS (Software as a Service). Providers can be evaluated against the following criteria: performance, total cost of ownership, application location, security, compliance, support, push toward lock-in, manageability, and usability.
This list isn’t exhaustive, but the first two are essential.
Let's dig in.
Here, we're using performance as an umbrella term for transaction speed, availability, latency, and multi-tenant support.
Throughput, in relation to Kafka, measures the number of Messages per second.
Ultimately you're interested in a high throughput/cost ratio; the highest possible throughput with lowest possible cost. This is a multivariate metric where throughput is just one of the variables measured.
Aiven's Kafka Benchmark tool provides working examples of throughput performance which you can use to compare different clouds on the spot!
Latency will depend on where your workloads are hosted. If reducing latency is a priority, you’ll want your applications to run in the same cloud and network.
Next up: what is the availability required to deliver your service level agreement (SLA) with your users? 99.99%? 99.95%? Ensure the cloud Kafka you choose meets this SLA too.
Most services support multi-tenancy. It's possible you'll get better cost efficiency from a Kafka cluster when infrastructure is shared with other tenants, but there may be compromises in terms of security and risk (especially if you fall on a “noisy neighbour”). We'll cover a few of those security aspects later.
Managed Kafka providers come via any number of different pricing models. Pricing structures include one or more of the following:
Compute & storage resource hourly pricing
Compute & storage fixed-based pricing
Cluster/Broker based pricing
Message throughput-based pricing
Topic/partition-based pricing
Whatever the pricing model, try to calculate the estimated price per MB/s of data (by testing how much throughput you get) as your unit of cost to your business.
Now let’s look back at your app migration roadmap for Kafka: bear in mind some cloud providers have a low entry point and become more expensive as you scale. Scaling may involve having to switch from a multi-tenant to a single-tenant environment.
Cost should also factor in the ingress and egress of your network throughput. Where you host your application workloads will therefore be important.
Ultimately, the cost of your cloud is likely to be a fraction of your Total Cost of Ownership (TCO) of running the service. The primary cost will be in people. Ensure maximum productivity by reducing the skills required to build applications on your data platform.
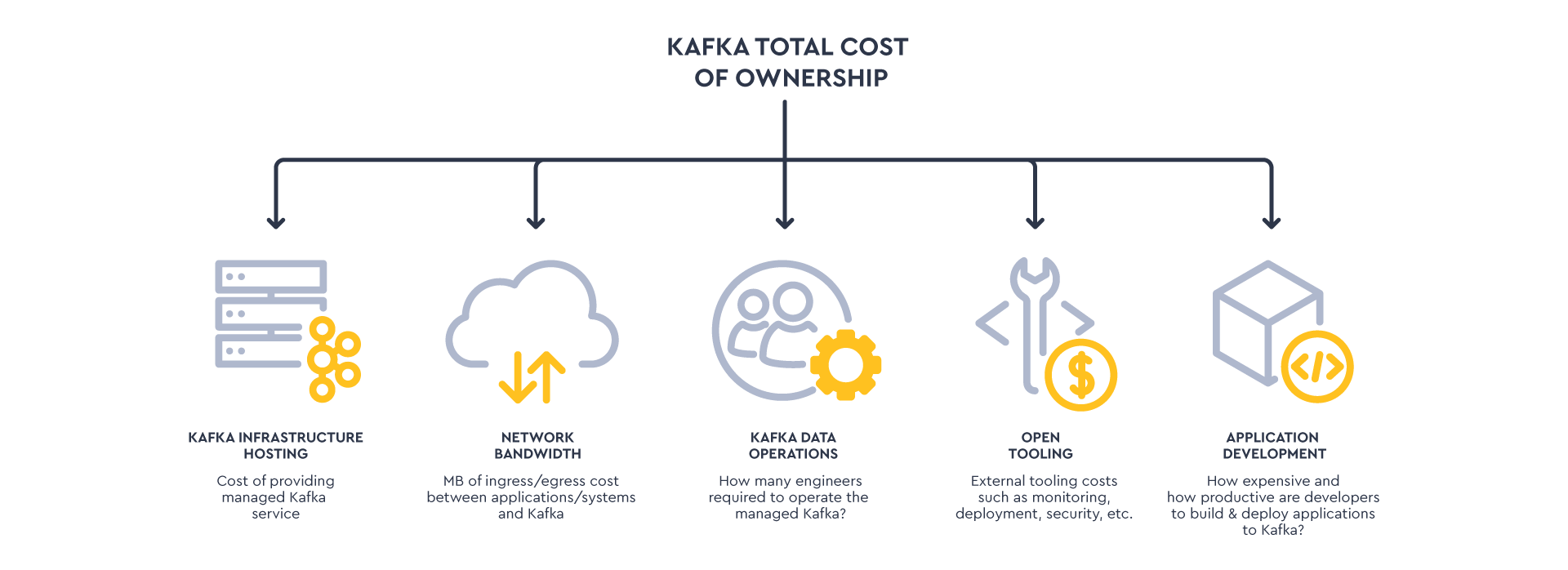
How Kafka is operated is just one piece of your overall DataOps strategy. Kafka is just the data layer. Where your real-time applications will run and how easily you can deploy them will impact costs, security, performance and the degree of Kafka adoption.
If you find a suitable compute service (such as a managed Kubernetes), Lenses can help with the deployment and data operations of the applications.
Consider defining your Kafka workloads as configuration using GitOps. This would help in your CI/CD as well as any migration from self-managed to your Cloud environment.
Most cloud Kafka providers offer multi-tenancy, which introduces security implications. The vendor should be responsive to these concerns.
You may want logs and events from the Kafka environment integrated into your security tools for your security operations team. Outside the bigger cloud vendors, infrastructure/OS logs may not be made available, especially if you’re on a multi-tenant environment. For application audits, Lenses collects logs related to all data operations and integrates them into your SIEM of choice, such as Splunk.
Some managed Kafkas provide consoles for managing resources such as ACLs and topics. For security best practices, ensure the consoles integrate with your corporate identity provider. Many operations can be performed through Lenses which supports integration with popular SSO providers such as Okta.
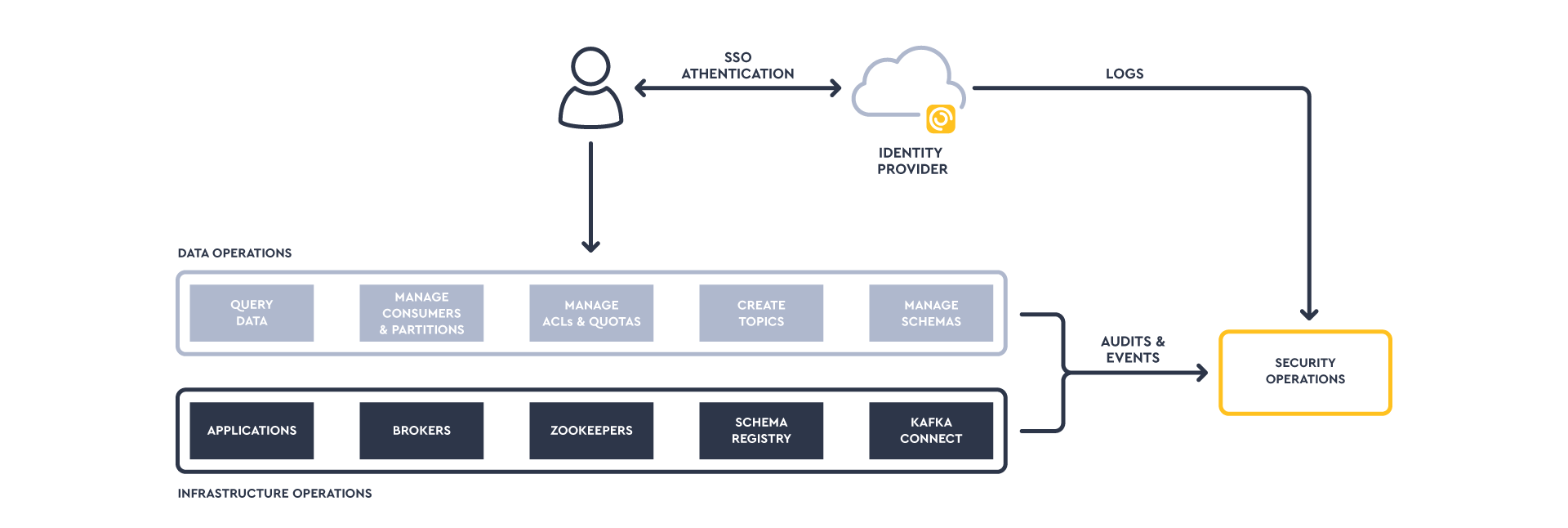
Your cloud Kafka should also have a clearly documented means to secure connections and endpoints. Some managed Kafkas will provide their own Kafka clients to standardize and secure how data is consumed and produced, but this may lock you in.
Is this clearly laid out in the user documentation or buried in a help article somewhere?
Different Kafka providers specialize in certain industries and therefore provide expertise meeting specific regulations (PCI, HIPAA, etc.).
You’ll likely need to look into the following, regardless of your industry:
SOC 2 - typically a minimal requirement when choosing a SaaS provider; assesses how well a company safeguards customer data.
ISO 27001 - a risk-based approach for developing an organisations' ISMS (Information Security Management System); a framework of policies and procedures comprising all legal, physical and technical controls.
FedRAMP - US public sector compliance.
NIST - a useful framework for cyber security. Here is NIST’s guide to protecting the confidentiality of PII, which the Lenses.io team used to build their data policies for Kafka.
The GDPR (and similar CCPA), mandates that personal data imposes various rules on how data is stored and governed. It also allows the data owner to "disappear" and, under the "Right to be Forgotten", withdraw consent to store their data, meaning it should be securely deleted. This makes securing event logs challenging. But by writing data to different partitions, each encrypted with a different key, you should be able to selectively revoke the encryption key when the data permission sunsets.
GDPR will also dictate that if you are providing services to European residents (and storing their data), you'll need to store PII in a data center within Europe. You'll need to understand the lineage of where your data is sourced, processed and stored.
Lenses addresses the shortcomings of Kafka by providing data discovery, PII data masking, as well as showing data lineage and data provenance.
Consider the level of service you require to meet your business objectives. Can you source Kafka talent internally or do you prefer to lean on a partner for strategy and operations? Do you need 24x7 availability & security monitoring, for example, or will you take this on yourself?
Tooling (such as Lenses) can reduce the need for Kafka experts.
As we move down the list, our items become more subjective, but are no less important. Take documentation, for example. How complete is the documentation? Is it well organized? Comprehensive? Easily searchable?
And in terms of agreeableness and rapport: how nice is a cloud vendor to work with and how accessible are they? Are others generally finding them helpful, friendly, and empathetic?
Apache Kafka may be open source but increasingly its ecosystem is closed source. This provides benefits but may lock you in with a particular Kafka provider and may hinder your multi-cloud strategy.
Does a specific cloud provider offer the tools and extensions (e.g. Kafka Connect, Karapace, Flink/KSQL, or Schema Registry) to do everything you need? Preferably, does it offer these tools without vendor lock-in? Even if you don’t need them straight away, this is where your roadmap will be important.
Looking ahead, what are some other points to consider?
Innovation - Does the cloud Kafka provider allow engineers to innovate with the platform - for example building new APIs or dashboards for interactions - or are workflows and interfaces fixed and immutable?
Roadmap - Kafka is relatively new to the world and many are innovating quickly with new supporting services. So make sure your provider's roadmap is in line with your strategic objectives.
Manageability - Does the vendor provide a usable management console containing the right features? To what extent is the service manageable by API so you can integrate into your CI/CD toolchain?
Usability - How easy is the vendor's specific solution to use? This is quantifiable by running brief in-house usability tests (for example, how long does it take for your individual devops staff to do X, Y, and Z? Where specifically do your people get stuck performing these operations?)
Time-to-market support - How quickly can your organization go to market with your Kafka-based service on a specific cloud?
If you decide - or legally need - to run infrastructure across a combination of clouds, you invite additional complexity.
For instance, you’ll need to standardize your monitoring, governance and data operations across multiple different Kafka cloud providers.
This is again where Lenses helps by abstracting the data operations across any Kafka.
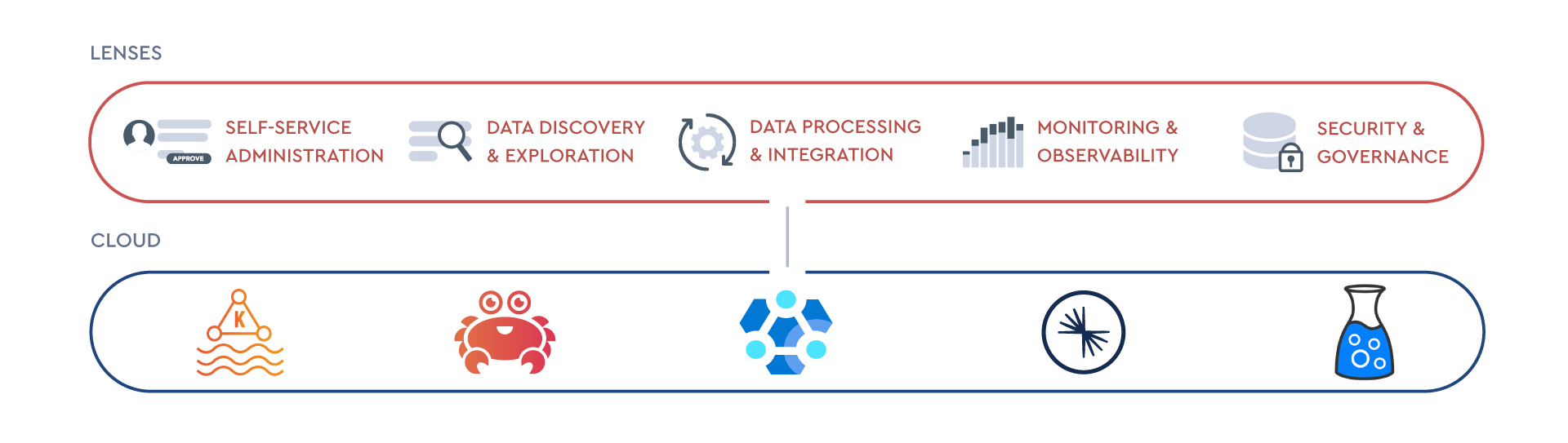
In this article, we've looked at some of the choice criteria for Apache Kafka cloud providers. After examining the special case of partitioning, we looked at performance, total cost of ownership, application location, security, compliance, support, push toward lock-in, manageability, and usability. We also discussed the special case of the multi-cloud strategy.
Can you see how moving your on-prem Kafka to the cloud isn't just about lift and shift?
Your cloud Kafka should help you take the heavy lifting out of managing infrastructure, but that still means Apache Kafka is a black box when it comes to understanding deployed flows.
You can use Lenses for Kafka monitoring, data observability and governance control for apps that run across managed Kafka services like Amazon MSK, Azure HDInsight, Aiven for Kafka and Confluent Cloud.
Stay tuned for our upcoming comparison guide, where you can check out which of these cloud providers might best suit your organization and Kafka setup!#
You can choose a way to start exploring Lenses here alongside scoping your migration requirements to a managed Kafka.
Reasons and challenges for Kafka replication between clusters, includi...
Andrew Stevenson




