By
Dec 02, 2020Antonios Chalkiopoulos

Antonios Chalkiopoulos
Several years ago when I was working on a big data project, I saw something a data engineer shouldn’t see. Curious to understand the level of detail in a new credit score dataset we’d received in our data lake, I queried it. I was surprised at how easily and suddenly my screen was flooded with the mortgage history, overdraft limits and year-end financial statements of my colleagues, and I felt deeply uneasy.
If I stumbled upon this data, how easy would it be for a malicious user to sell PII (personally identifiable information) data across the dark web? The kind of breach that has since lost trading licenses and slapped several organizations with fines for millions of dollars.
More recently, contracting at a large global financial services firm, my team encountered constant challenges getting our data projects signed off and into production. The biggest was meeting the maze of data compliance controls.
Asking for special dispensation was getting more difficult in a world of Dodd-Frank, MIFID II and post-financial crash.
Fast forward a few years, the level of regulation has increased, as has the need for engineering teams to continuously access real-time data.
We knew that helping organizations meet data compliance for Apache Kafka should be one of our priorities. This would be with the following in mind:
Responsiveness to real-time needs: The likes of Apache Kafka are powerful Open Source streaming technologies, but we need rules in place to make them useful for business outcomes.
Design for a world of DevOps and DataOps: This means introducing controls in a world of agile data management and data engineering.
Flexibility to apply constant regulation updates and change access controls to cover multiple regulatory frameworks, including SEC, GDPR, CCPA, HIPAA etc.
Identifying (and mitigating) data risk: Not all data carries the same impact and level of confidentiality.
Passing audits without manual processes: Helping speed up the reporting time of audits.
For us this has been implemented as a Data Policy framework.
The framework is designed to cover data compliance and information security best practices for real-time data.
And although we often talk about protecting PII data, the Data Policies framework helps address data compliance more broadly. For example, we give visibility over sales transactions whilst masking the order value from internal employees to meet insider trading compliance.
Here we outline the framework and the journey you can take to increase your compliance.
As your Kafka adoption across teams and projects expands, it’s easy for data sources to proliferate. And to find yourself non-compliant at any moment.
Keeping track of information flowing through Apache Kafka will be especially important when it comes to conducting audits.
But Apache Kafka as a black box doesn’t make this easy.
This usually means weeks if not months of manual reporting and interviewing teams when it comes to a compliance audit.
This is the first problem we're addressing with our Data Policies.
We do this by intelligently keeping track of metadata across your Kafka Streams, no matter the serialization (CSV, Protobuf and custom proprietary formats).
It’s the same technology that powers our SQL engine to query data on the wire as well as our data catalog.
And it's presented as a data experience UI. Having a variety of ways to interface with data policies makes it easier to zoom in or out of topics and applications to see how they are interrelated, whether in a list or in a Topology as shown here:
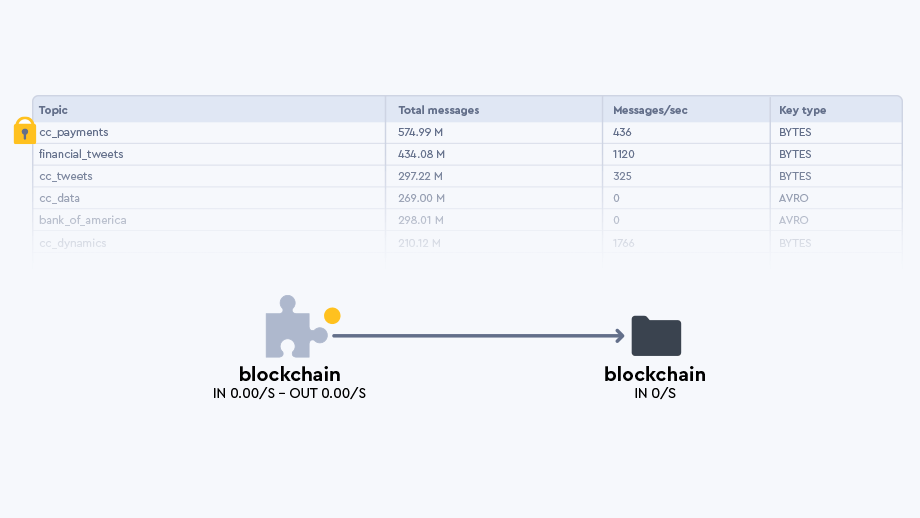
Understanding how data is related allows us to define interesting fields that represent datasets. More on this later.
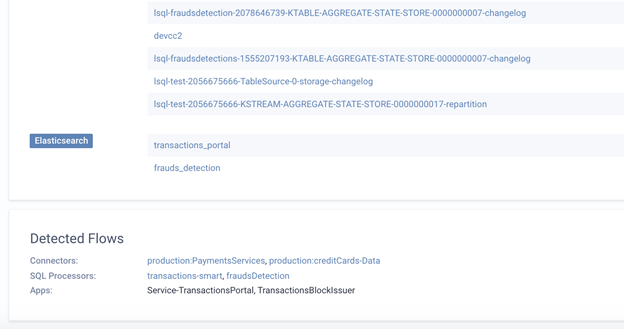
This detection covers the datasets themselves (Kafka Topics or Elasticsearch Indexes) as well as the applications (this can be anything from your custom external producer/consumer applications and microservices, Kafka Connect connectors or Lenses Streaming SQL applications).
With your streaming data discovered, the next step is to classify the data.
We used the National Institute of Standards and Technology (NIST) and their guidelines for protecting PII to help.
This Ontology can be tuned to the specific business domain or data domain such as ‘crypto-assets’, a regulatory framework such as ‘MiCA’ and a confidentiality level.
Name : Full Name, Maiden Name, Mother’s name, Alias
Personal Identification Information : SSN, Passport number, Driver’s license Number, TaxPayer identification number, Patient Identification Number, Financial Account, Credit Card Number, Login name / Username
Address Information : Street Address, Email Address, Zip Code, City, Country
Asset Information : IP Address, MAC Address
Telephone Number : Mobile, Business and Personal number
Personally owned property : Vehicle registration Number
Personal linkable Information : Data of birth, age, place of birth, religion, race, weight, height, activities, geographical indicators, employment information, medical info, educational info, financial info
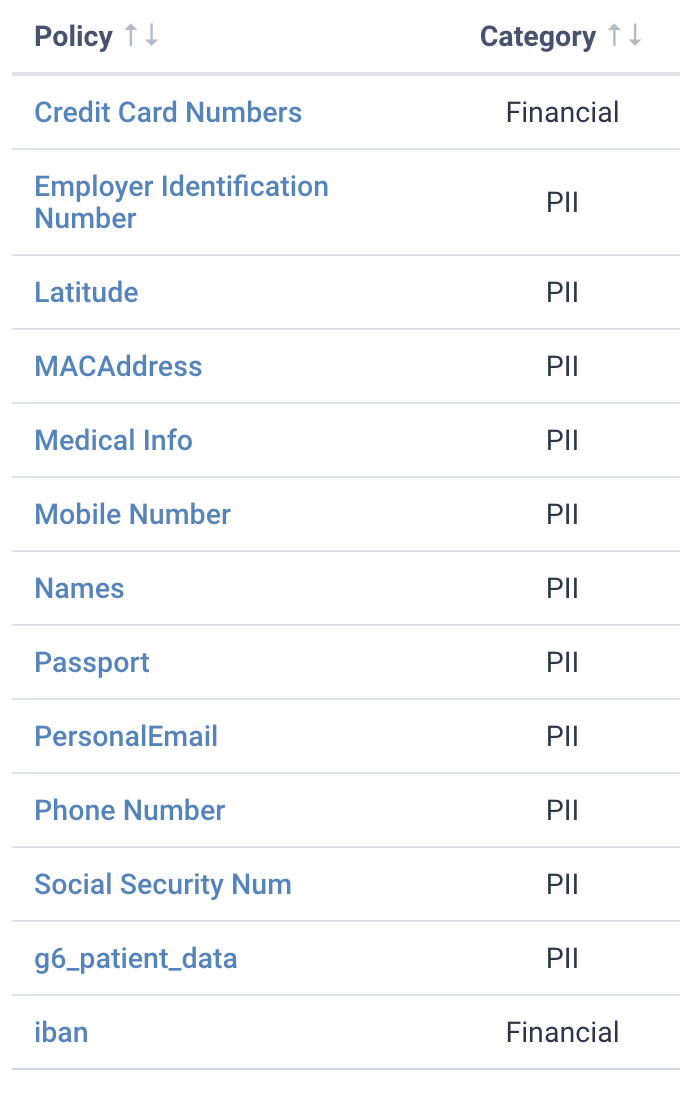
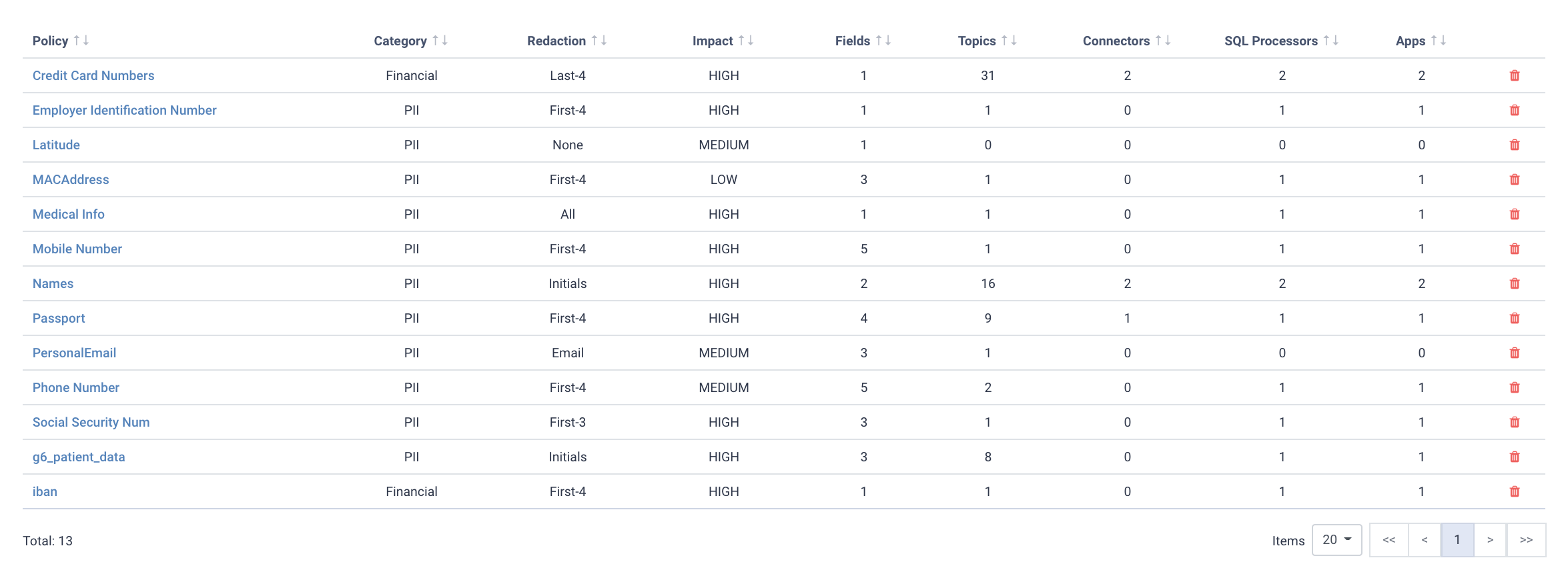
Of course, not all data have the same confidentiality impact level. Fields that can be used to fully identify a person (i.e. Passport or Social Security Number) have to be treated with additional care, whereas information like Country or Postcode can only partially reveal the identity of a subject.
Here we’ve highlighted data at different impact levels. Social Security Number is very high, whereas postcode is comparatively low.
The combination of the Data Policy impact level with the detected streams and applications helps risk managers and compliance officers ensure they apply the appropriate safeguards based on the confidentiality impact level.
With data discovered and classified, the final step is to redact or anonymize data, so that users can access it whilst meeting compliance.
For many, this can be one of the biggest compliance challenges you will encounter whilst working with Kafka.
For Lenses, this is achieved through redaction rules associated with each Policy.
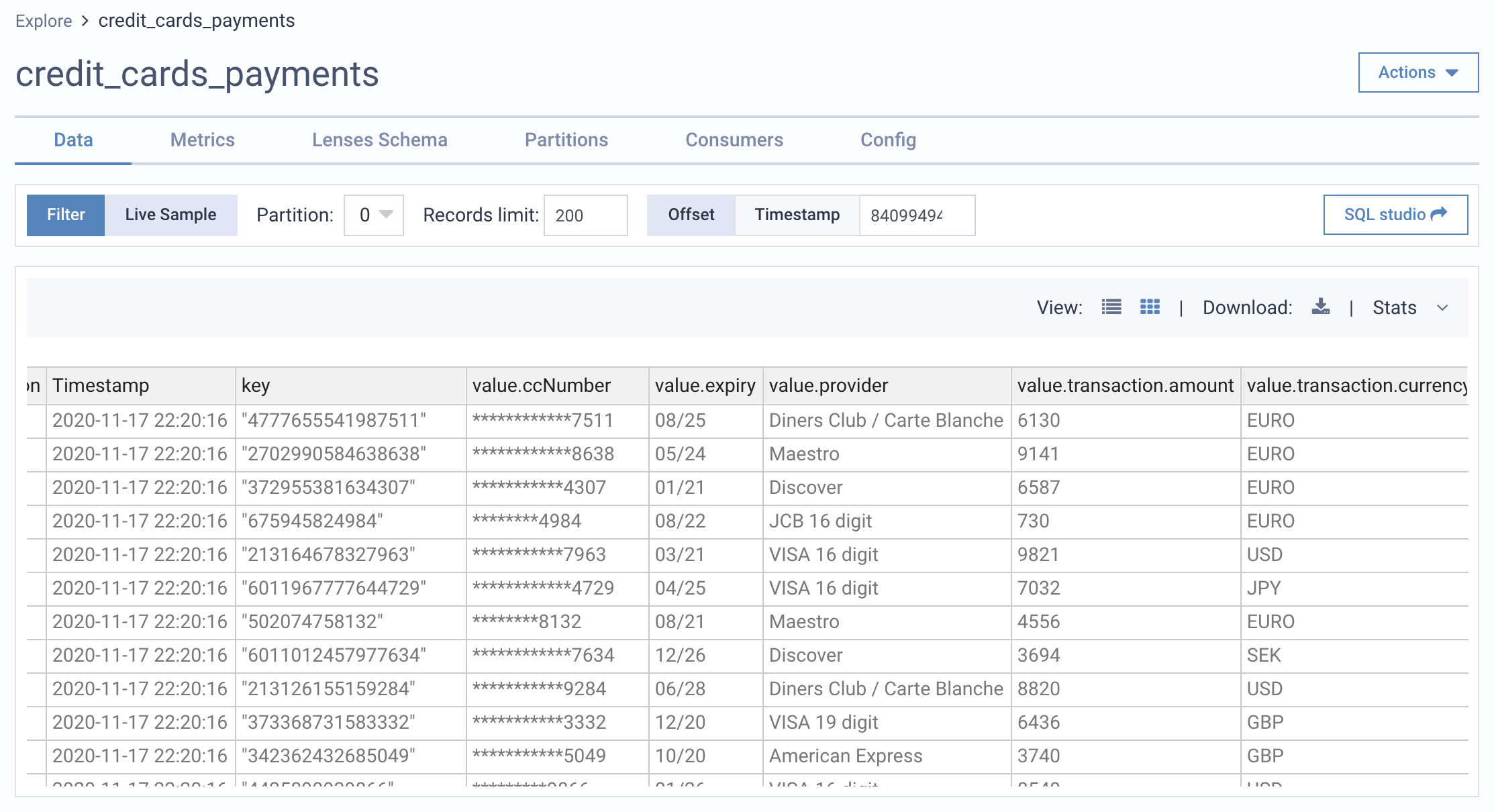
When data is accessed by a user that matches a Policy, we can automatically anonymize data.
Here are some examples of redaction policies and how they may mask fields within streaming data.
Policy Sample Data Sample Output
Initials Only Jon Smith J S
First-3 (212) 509-6995 (212) xxx-xxxx
Last-4 4111 4050 6070 8090 xxxx xxxx xxxx 8090
Redaction 123 xxx
Email Mask myEmail@org.com mxxxxx@org.com
The masking is applied on-the-fly as opposed to redacting the data at rest or on the wire. This is a means of giving users access to data to meet any number of different compliance controls, whilst avoiding having to re-architect an application.
Good data policies, rather than adding friction, actually open up data to those who can understand it and apply it.
As you can see from the rules in the examples above, data governance is not technology specific. It is not implemented - it is applied.
In fact, features like these are helping data engineers at heavily regulated firms:
Move their data projects from pilot to production
Reduce their time-to-market by 10x
Create policies that are easy to remember, and easy to apply
Move forward with a technology-agnostic governance framework
We hope they do the same for yours.
Curious to see how it works? You can watch this short example of meeting data compliance for streaming data including data masking:
You can also see Data Policies in action in an all-in-one Kafka and Lenses environment as a Docker container or Cloud instance. Start here




