By
Jul 27, 2020Andrew Stevenson

Andrew Stevenson
From warehouses to streaming applications, in this article we explain why we need a new class of Data Catalogs: this time for real-time data.
In the 2010s organizations “did big data”. Teams dumped data into a data lake and left it for others to harvest.
But data lakes soon became data swamps. There were no best practices, no visibility into service levels or quality of data, no data contracts, no naming conventions or standardizations.
Just as quickly as data had arrived, it was impossible to find or trust.
If you were forward-thinking, you may have enlisted an enterprise Data Catalog to discover data across your data stores. Otherwise, this would have been a manual documentation process.
Either way, this wouldn’t prepare you for what was to come in the world of streaming data and DataOps.
As a developer, you still struggle to answer simple questions such as: Where do I have customer data? How about personal data such as surnames, phone numbers or credit cards?
This is because the challenge to catalog data got harder. Data isn’t sitting in data warehouses any longer. It’s streaming, not at rest. And in many cases, it is data generated by your consumer-facing event-streaming applications, not your business teams.
A lot of applications.
Engineering teams don’t have time to follow traditional data governance practices when it comes to streaming.
And yet, if there is no way to know what data there is across different teams - it may as well not exist.
Much of DataOps is about removing friction from delivery. It’s about eliminating the need for pure luck in speaking to the right person at the right time. For endless back-and-forths to understand what data exists and its purpose.
This won’t work in 2021.
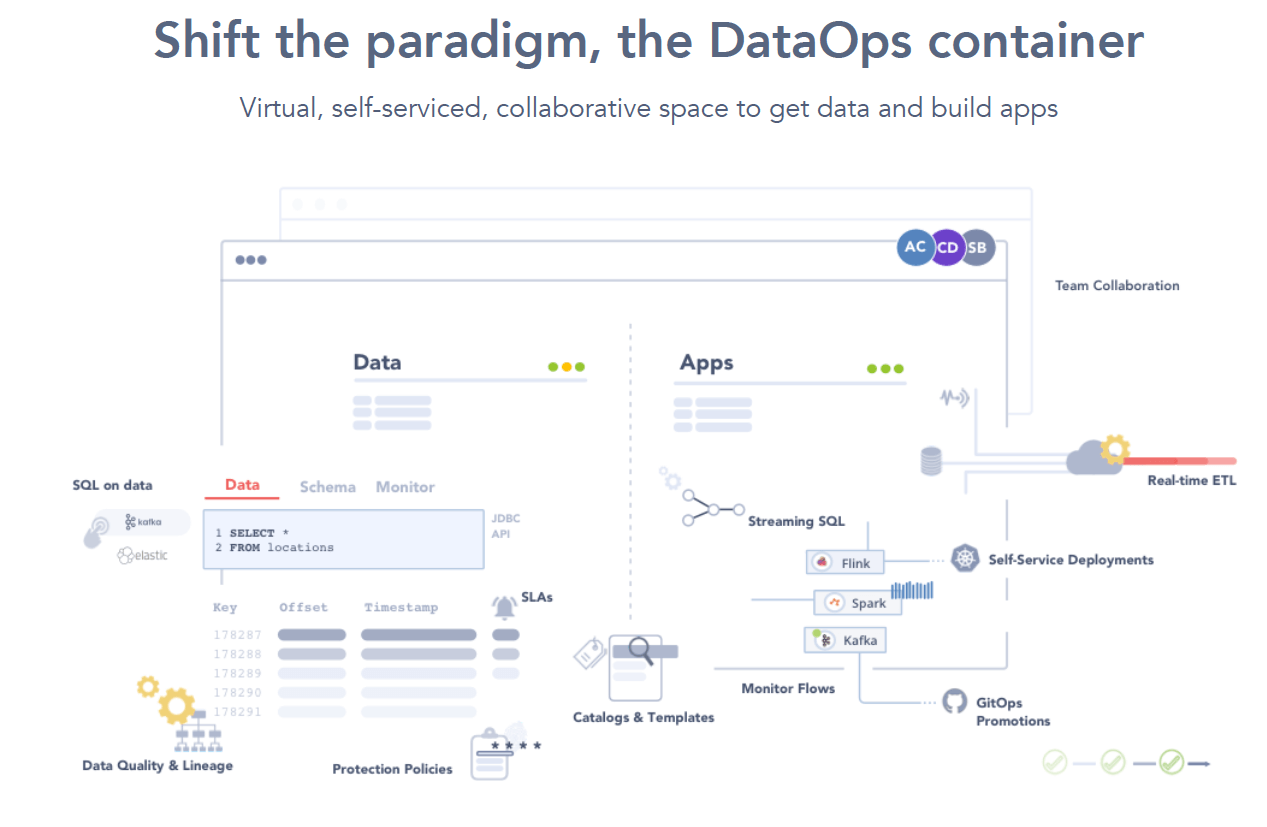
For real-time data, there is no alternative but to automate and augment data management processes. This includes the automatic discovery of data entities, data lineage, classification and quality.
Automation will mean teams are free to develop new data-intensive applications without being bogged down by manual data management practices.
What data is discovered can be immediately socialized across a business, in a data mesh architecture.
Metadata is Queen.
If you can collect it from your different data infrastructure and applications you’re on the right path. But to generate value you need to be able to answer the right questions:
What data exists and its profile?
What is its quality?
What service levels can I expect?
What is its data provenance?
How might other services be impacted?
How compliant is it?
Being able to answer these sorts of questions is fundamental to the success of real-time data projects.
Gartner agrees:
“By 2021, organizations that offer a curated catalog of internal and external data to diverse users will realize twice the business value from their data and analytics investments than those that do not”
Source: Augmented Data Catalogs: Now an Enterprise Must-Have for Data and Analytics Leaders,” Ehtisham Zaidi & Guido de Simoni, Sept.12, 2019
Lenses.io delivers the first and only Data Catalog for streaming data.
It's an easy, secure and intuitive way to identify your data:
It works in real-time
It continuously and automatically identifies all your streaming data
It works across any data serialization format
It enables your team to mask and protect all sensitive data.
It allows you to enrich with business metadata such as descriptions & tags
It allows you to act on the data
Lenses not only provides a Google Search experience over streaming metadata, but also a Google Maps experience by building a topology of your data pipelines across your different applications (Connect connectors, Flink, Spark, Akka, etc)
Next, we’ll explain the thought process and key principles behind our real-time Data Catalog.
Building a real-time Data Catalog was a natural progression for our team. We’ve been giving visibility into Apache Kafka environments and applications that run on Kafka for years.
This was mainly developed to help engineers gain insight into their Kafka streams. Very useful when it came to debugging applications and inspecting message payload with SQL, partitioning information, overseeing infrastructure health or viewing consumer lag.
Way back, we developed a SQL engine to explore topic data. And this is what has fueled the development of our catalog.
To query with SQL, we had to understand the data and its structure, so we connected to an AVRO schema registry or sampled messages in a stream to discover a schema. This included over XML, JSON, CSV, Protobuf and custom proprietary formats, meaning we already had visibility into the metadata.
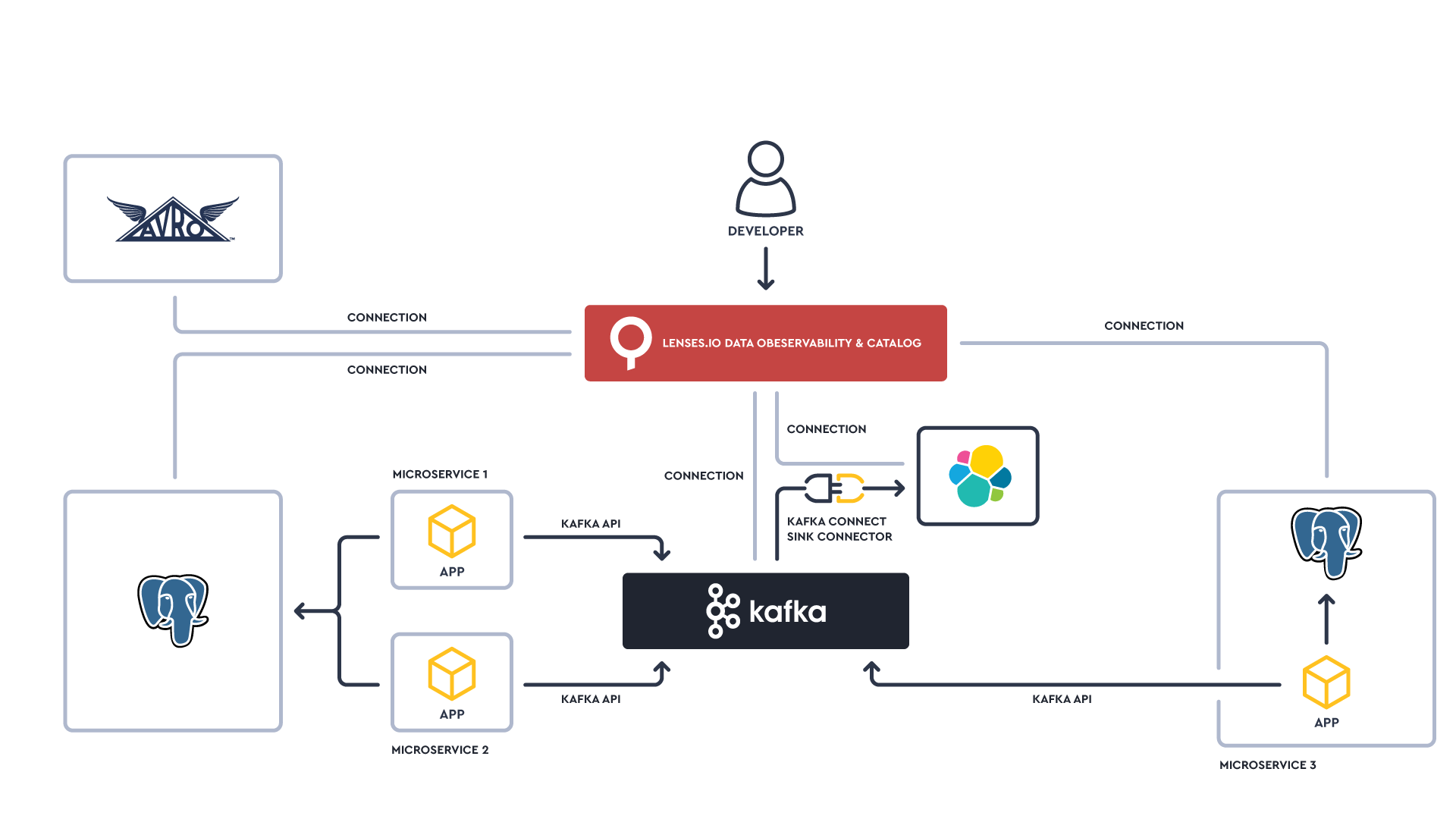
Our customers are using Kafka as one component of a larger data platform. Data is being sourced and sinked into Kafka from other technologies, particularly when it comes to building event-streaming applications based on microservices.
To deliver a great developer experience, data observability and data cataloging would need to be extended beyond just Kafka streams.
So last year we extended the capabilities to discover & explore data in Elasticsearch - and more recently we added PostgreSQL.
What we discover by inspecting streams, looking in Elasticsearch indexes or Postgres tables is primarily technical metadata.
But as a Kafka platform starts serving potentially hundreds of different teams and projects, it’s important to be able to enrich the technical metadata with business context. We do this by giving users access to add their own tags and descriptions to classify data. This may include things such as
The service owner
The service level agreement
Any compliance & regulation controls it must meet
Where the data is harboured
This information not only helps a developer by providing business context but also allows them to filter data from a view to more easily explore what data is needed or useful.
The next step is to not only understand what data you have, but associate it with the applications that process them.
We therefore allow users to register their external applications either as a REST endpoint or with a client for JVM-based applications.
For applications built and deployed within Lenses (such as Streaming SQL applications or Kafka Connect connectors) we will automatically instrument the application for you.
This builds us an App Catalog and a Topology of all the dependencies between different flows and applications, creating the data lineage trail of different data sets.
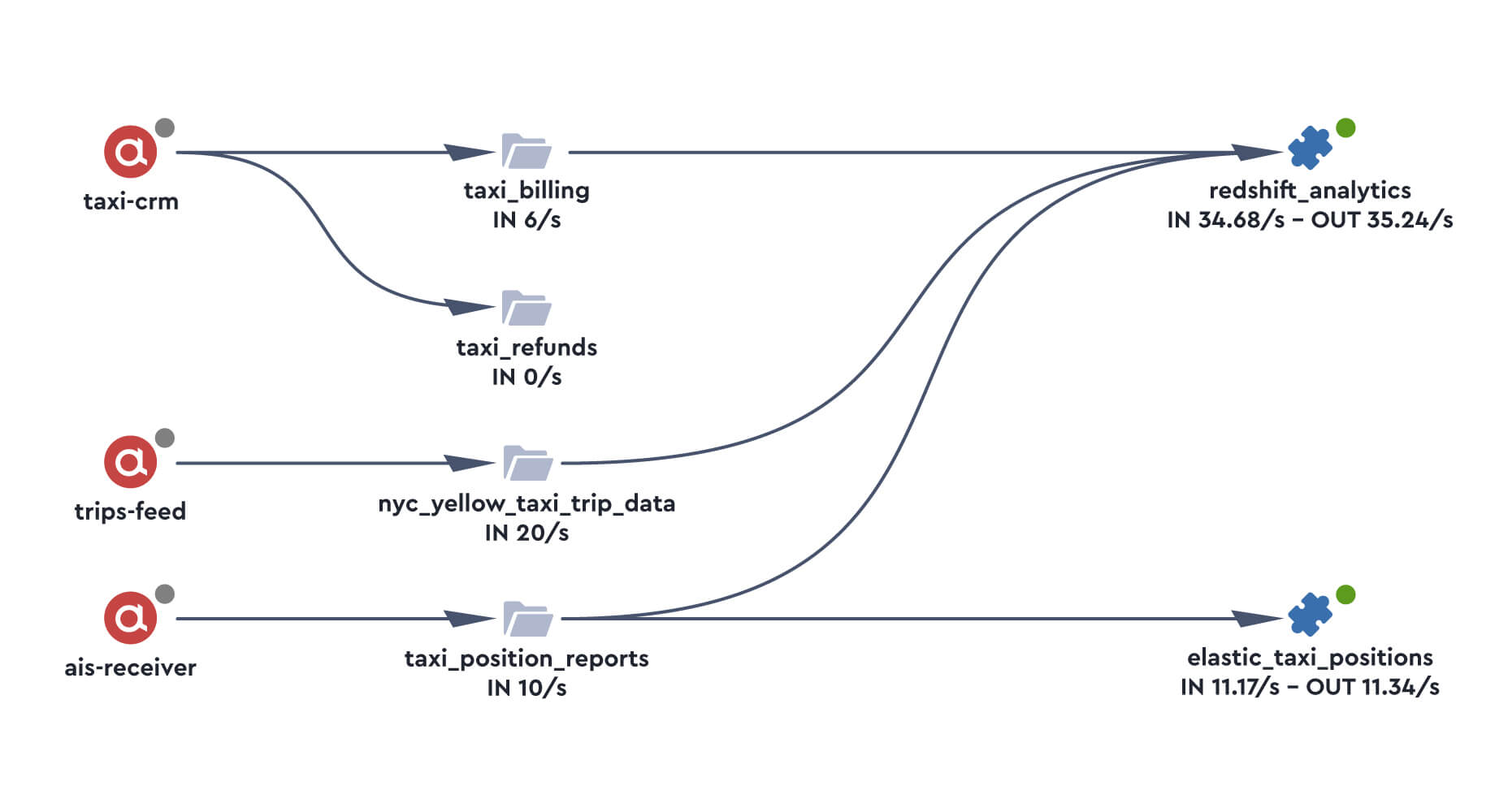
It also allows us to answer a few important questions:
What applications generated this data?
How much can I trust the quality of the data and at what service levels?
What downstream applications consume this data to understand service disruption impact?
The Topology, App Catalog and SQL Engine therefore give us the ability to maintain an understanding of data flowing across a data platform.
Most importantly, this data is updated automatically and in real-time.
As engineering teams develop a new product, whether a consumer-facing microservice application or data processing pipeline, the data and topology will be discovered automatically.
Or if an application writes to an Elasticsearch index or Postgres table, that too will automatically be picked up.
No need to manually maintain a catalog.
This information can then be presented and found in a free-text search fashion a la Google:
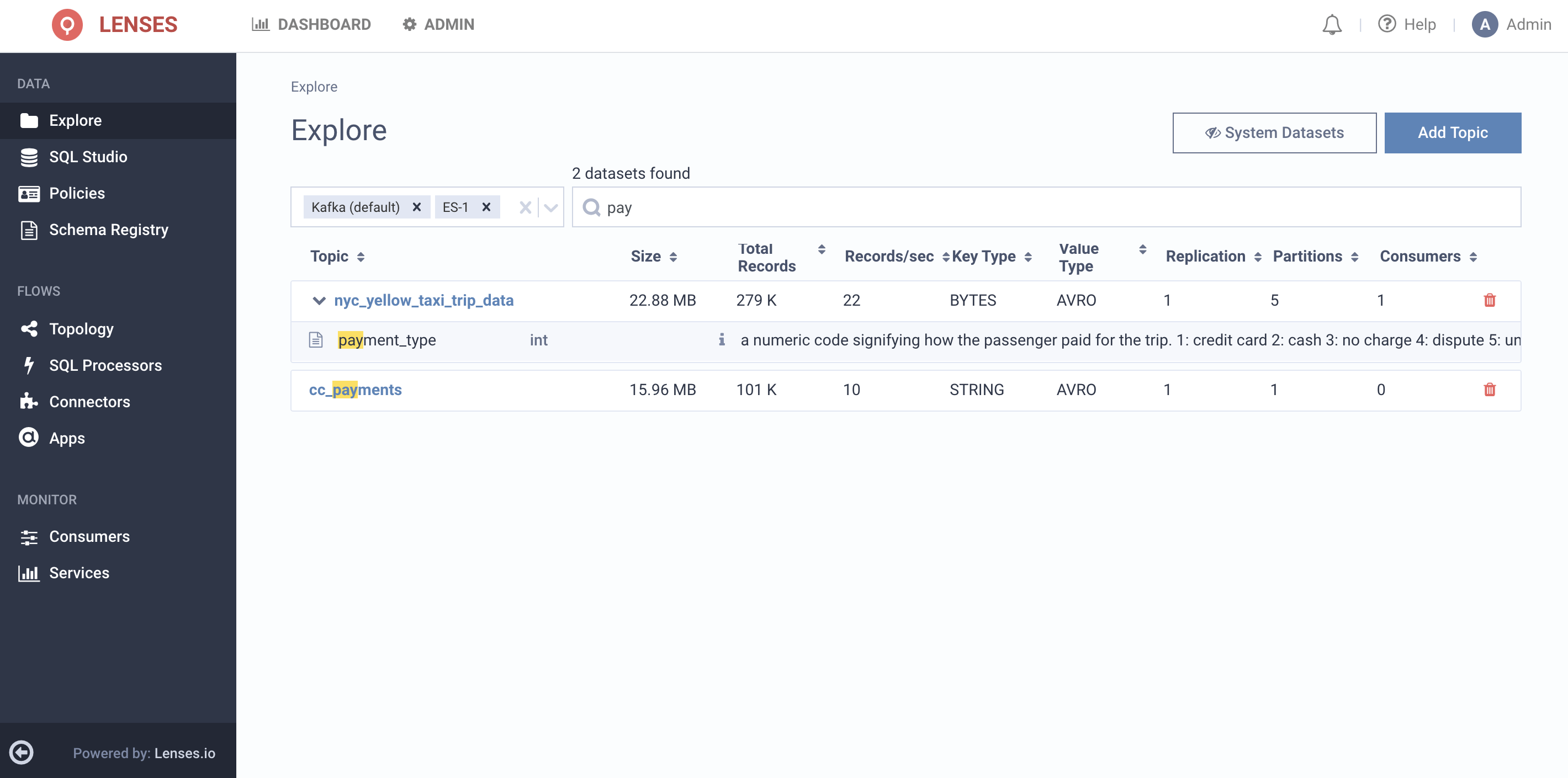
The catalog is protected with the same unified namespace-based security model that protects all data access in Lenses.
It opens up new use cases around how data can be accessed and drastically reduces the time or duplicate effort.
You can try out these use cases (or your own) by exploring our real-time data catalog for free in a sandbox environment at portal.lenses.io or see all deployment options at lenses.io/start.
The rise of hyperconnected data products....
Guillaume Aymé
Dec 20, 2024
How to write Protobuf-based Kafka producer & consumer microservices wi...
Eleftherios Davros
Mar 01, 2022





