By
Feb 17, 2021Andrew Stevenson

Andrew Stevenson
As data becomes an organization's most valuable commodity, it is those with the governance to confidently analyze and act on it that will develop the next big applications.
Whatever the size of your company, data governance must be considered at the very beginning of a data project rather than an afterthought only once it becomes too difficult to change.
Organizations today are required to run their business digitally and in real-time - a need that has been heightened by COVID-19, and this means accelerating the delivery of data projects. Being evangelical enough about getting data governance right (especially for engineers) and ensuring this is delivered from day one is often perceived as a slowdown, when in fact the net effect is quite the opposite. Creating the right guardrails for data means more, not less access to data. It means more POCs go to production and more apps go to market.
Whether it’s a real-time fraud prevention algorithm for a financial services organization, a real-time time service for a public transport system, or a fulfilment optimization application for a retailer, the pressure is on for you to continuously deliver new data products to market.
Failure or slowness in the delivery of such data products risks immediate loss of market share, increased risk from security threats or failure to harness new digital revenue opportunities due to a wild west of data inaccessible to the right people.
Rather than adding friction, good governance actually opens up data to those who can understand it and apply it.
Take Playtika for example, a leading social and gaming company with more than 1000 developers, product owners, analysts and scientists. They have empowered their teams to immediately access the real-time data of gamers in a self-service fashion so they can autonomously improve the gaming experience, develop new games and remain market leaders.
Consider the hundreds of analysts and engineers at Swedish digital bank Avanza who have direct access to as many different real-time data sources, and can manage them via self-service capabilities because all data is protected, masked for GDPR, access secured and audited. This access without intermediaries allows Avanza to stay ahead of the market when it comes to delivering digital banking services.
Success of such projects may have been a luxury several years ago, but now they’re mission critical for most competitive companies across the world.
But whilst governance is critical, organizations must rethink their practices to fit the changing pace of data.
Traditional data governance practices - often consisting of centralized, lengthy ticket-based processes and hinging on rigid rules, manual effort and even just human trust - no longer apply.
Since the explosion in data consumers - from data scientists and engineers to analysts and even executives - current practices no longer work. Take engineering as one example. You are responsible for building data products such as machine learning models or data processing applications and therefore you need constant access to data to build and troubleshoot it. Possibly data generated by another product team in another part of the business.
Having adopted DevOps practices for increased agility and speed, you are now faced with traditional and rigid data governance processes that as an engineer you cannot escape or workaround.
Many such products rely on open source data technologies.
Take Apache Kafka and Kubernetes as an example. As powerful as these technologies are, they provide no governance for teams. Engineers have championed such technologies without considering data governance. Yet as pilot projects have grown into strategic business initiatives, they stall through the lack of ability to access, audit and control data and its applications. Where we’ve seen success with Open Source data technologies is when it is coupled with great tooling that encourages and empowers developers to think about and orchestrate data governance across their products.
Data cataloguing has been commonly accepted as a best practice when it comes to data governance for analytics and data warehousing teams. With an explosion in data-processing apps, this is increasingly a problem. When was the last time data generated by apps in your Kubernetes environment was catalogued, even in the late stages of a project?
According to a Gartner report, through 2022, more than 85 percent of big data projects will fail to deliver value. Struggling to find, inventory and curate data will prove to be the biggest inhibitor to data project success, reports Gartner.
Even then, what do you do with that data? A passive data catalog sits and waits. An actionable data catalog provides insights and rich querying capabilities in a language its users understand.
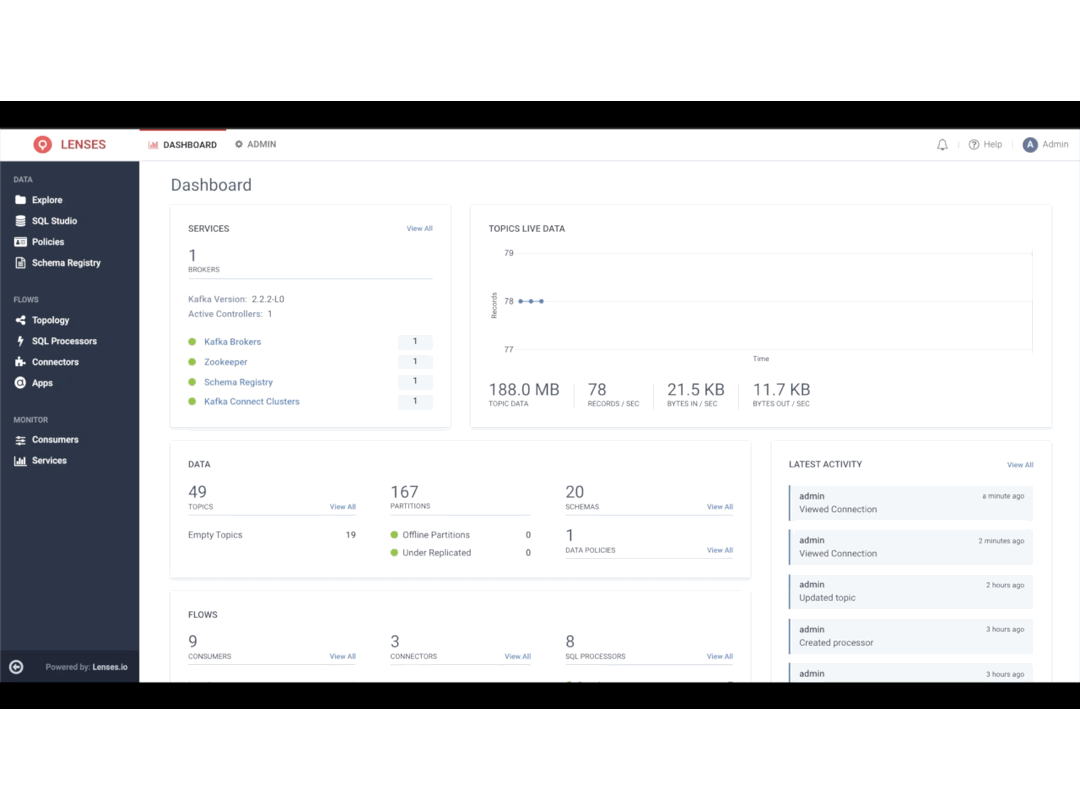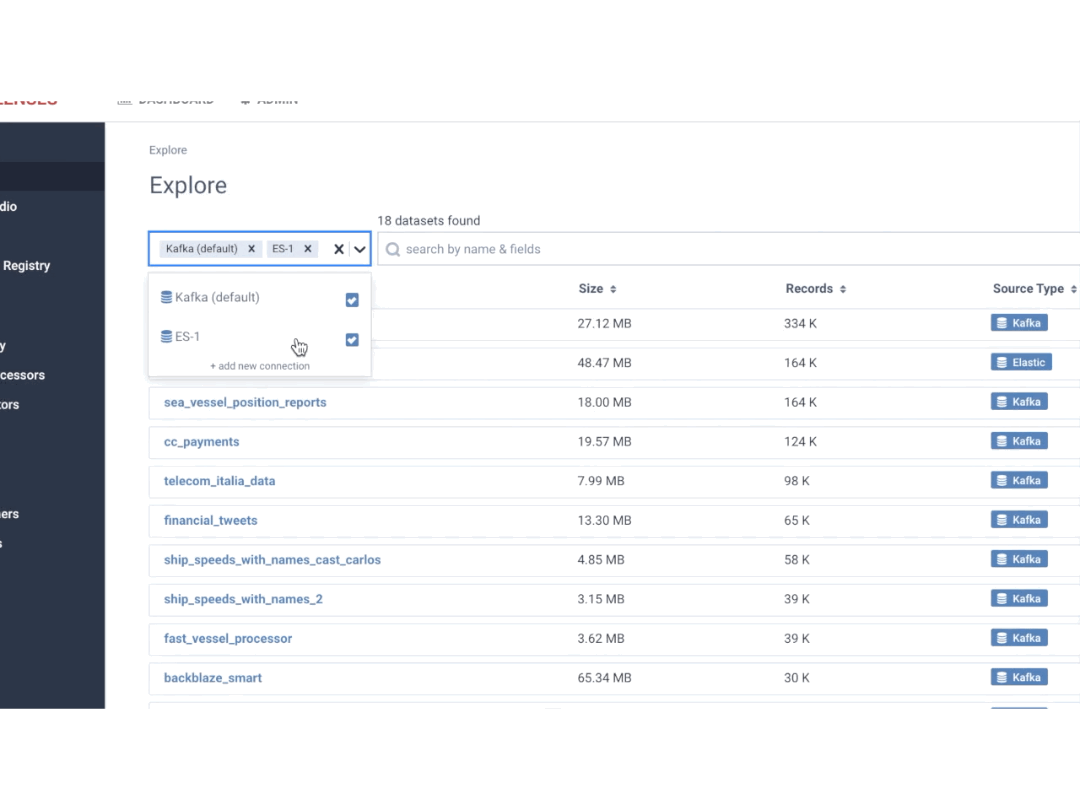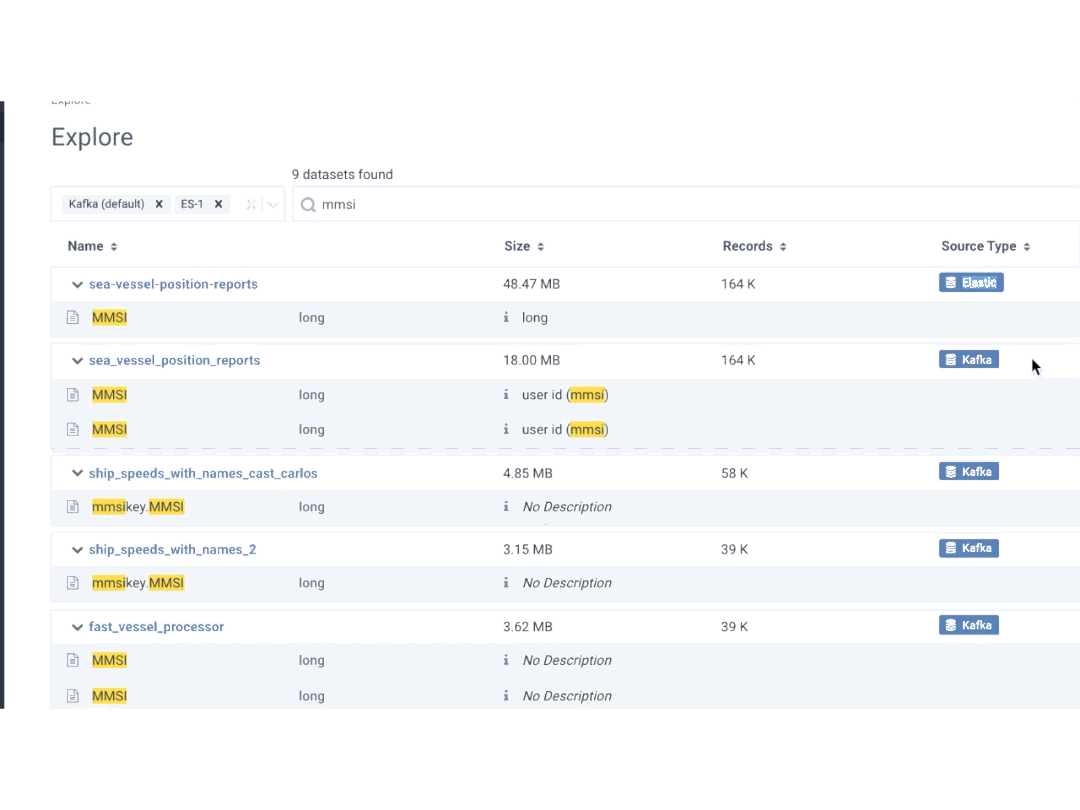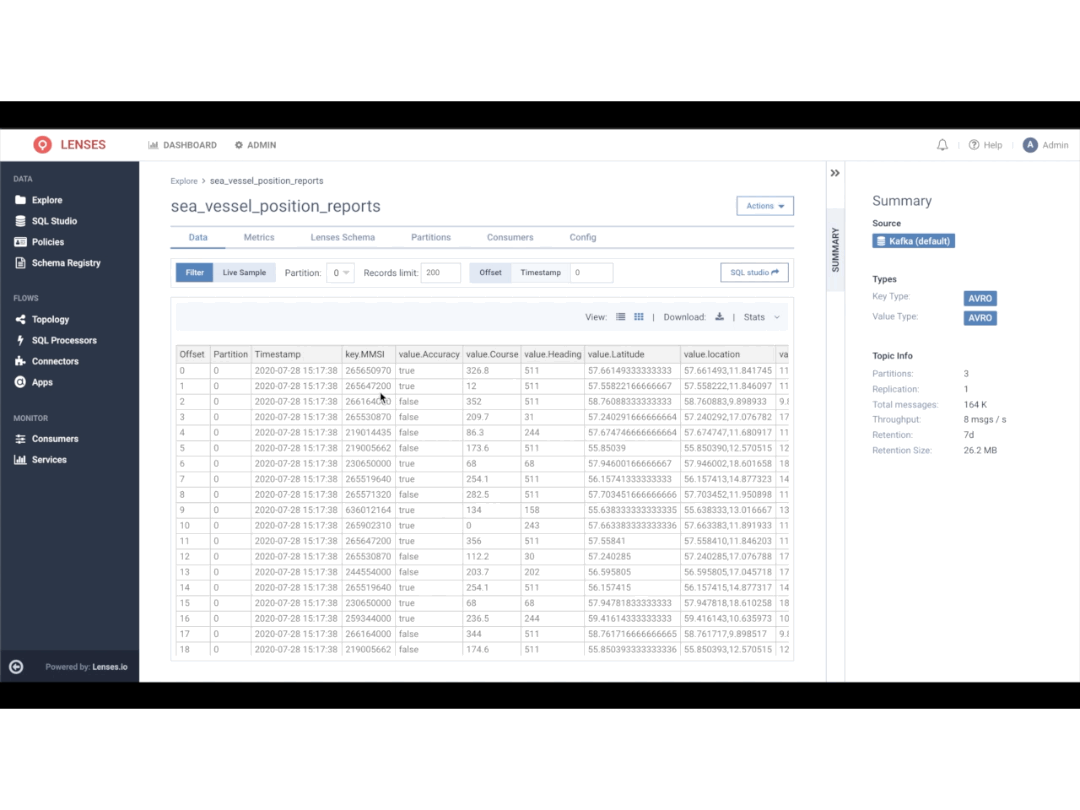
DataOps has emerged as a set of practices that enables a new generation of data consumers to directly access and operate data. This accelerates the delivery and quality of data products to market.
Successful DataOps addresses the data management challenges going away from the “one size fits all” approach to a more flexible and distributed approach to governance. It requires decentralizing responsibility for data governance with effective tooling that provides robust access controls on data, visibility, alerting and automation with machine learning so that it can be shared and processed.
DataOps takes many of the practices of DevOps but with a particular focus on socializing data, data governance and ethics. It lowers the skill level required to operate data so that business teams can self-serve, reducing the pain, cost and complexity of doing so.

DataOps promotes that data governance be embedded at the earliest stages of the development cycle of a data product directly by those that create the data.
For example, a data scientist building an Apache Kafka data pipeline should be equipped to define their application in a simplified language such as SQL. They should be able to define the data governance controls required to deploy their app to production without the need to bother engineering. They should have access to an intelligent and automated means to govern, review and ship data and apps to production (GitOps is emerging as a common practice for this).
Applying governance from the get-go will mean any data produced by the application will be instantly accessible to other relevant product teams. It forces those that create the data to think about governance from the beginning and redistributes the responsibility of accessing and socializing the data across the business. Empowering engineers in this way will create a data culture, grow the data economy and allow businesses to re-invent themselves from the inside out.
Having the ability to archive Kafka topic data is now essential. In th...
Mateus Henrique Cândido de Oliveira
The rise of hyperconnected data products....
Guillaume Aymé
Dec 20, 2024
How to write Protobuf-based Kafka producer & consumer microservices wi...
Eleftherios Davros
Mar 01, 2022






