Change Data Capture and Kafka to break up your monolith
How to build CDC flows into Kafka with full data observability into your microservices and PostgreSQL.

By Guillaume Aymé
Apr 21, 2021
Getting data from a database into Kafka is one of the most frequent use cases we see. For data integration between enterprise data sources when migrating from monolith to microservices, what better than CDC?
We talked about breaking up a monolith and the importance of data observability previously. Now we’re showing you how to do it with a typical microservices architecture pattern including PostgreSQL, Debezium and Apache Kafka.
Change Data Capture (CDC) is a means of maintaining (eventual-)consistency of state between two different database environments.
CDC represent a state-change (eg. Update, Insert, Delete, Create) of a row in a database table as an event. It does this by listening to the commit or change log of a source database.
For example following an INSERT into a table, an event such as the following is generated showing the before state (NULL) and the after state
This helps support a number of different use cases. A common one is to replicate data from an operational database into a data warehouse to drive analytics.
Or, as we will walk through shortly, to build event-driven applications in a way that decouples the code of two apps.
As an example, the diagram below shows 6 different state changes of a table as a stream of events. The _key of the event represents the primary key of the change row. The state of the table can be generated at any point in time. Individual events or an entire state can be shared to microservices that wish to consume it or act on the data.
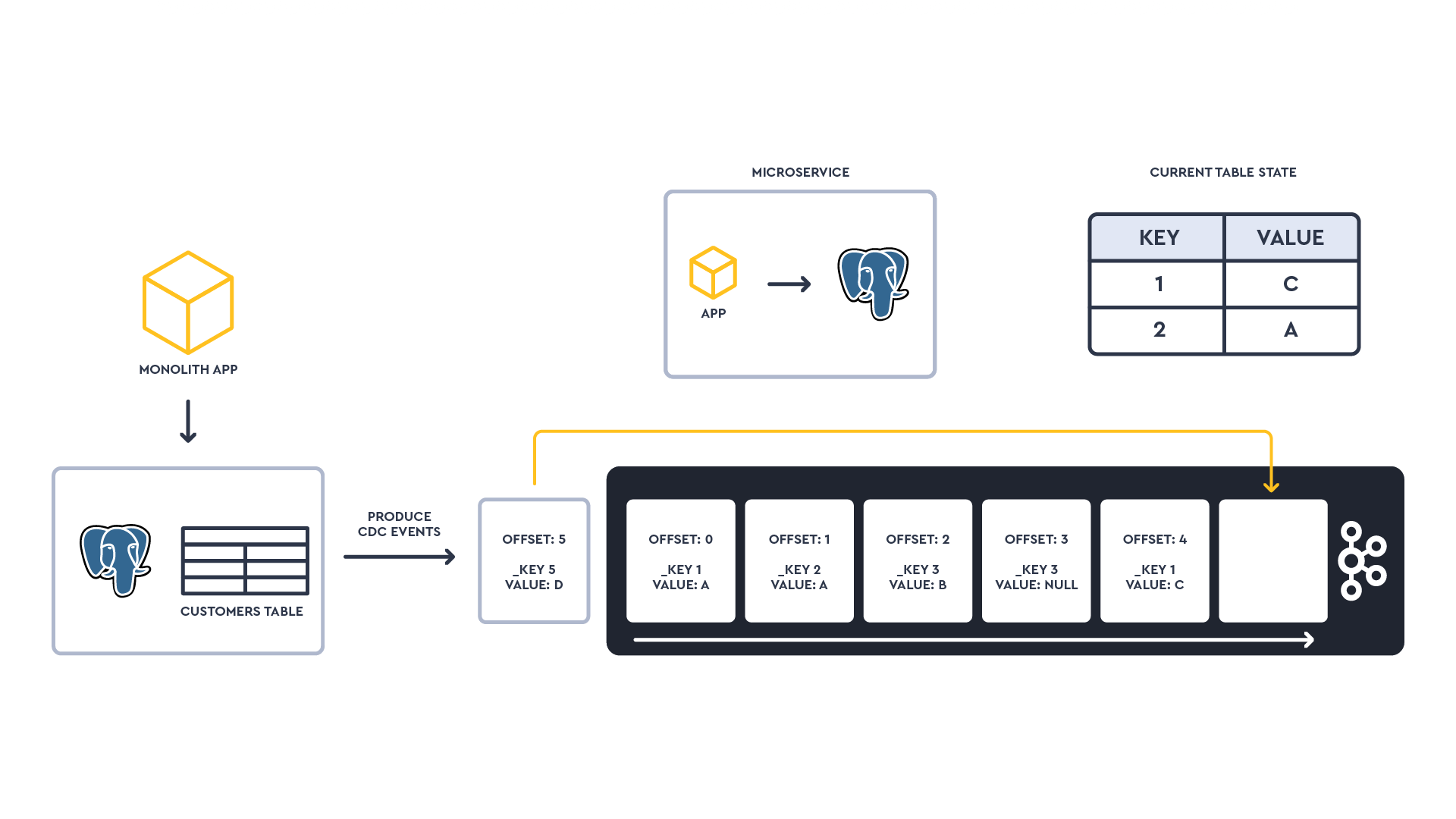
When working with Kafka, Debezium is the most common and powerful CDC solution.
Available for free as an open source Kafka Connect connector, it supports sourcing CDC changes to Kafka from a number of different DBs, everything from PostgreSQL, MySQL and DB2 to NoSQLs.
What’s handy is they provide relative good consistency in the format of their capture events across the different data stores they source from.
...But one of the biggest challenges when building CDC integration flows in Kafka is verifying data from source, Kafka and sink systems. This may be anything from trying to understand the cardinality of a field to how it’s being sharded or partitioned at the target.
That’s why Lenses brings you extended data observability and cataloguing into solutions such as Elasticsearch & PostgreSQL. This is an extension of observability into Apache Kafka streams.
The aim is to support an optimized developer experience whilst ensuring you can meet data compliance.
So let's imagine we are breaking up a monolithic eCommerce application sitting on an operational PostgreSQL database.
By monolith, I don’t necessarily mean a single runtime or even a single database/DB schema. It’s better to look at it as an application or series of components with a single build & deploy pipeline.
Releases on the monolith are too infrequent and involve high workload, risk and downtime. So to be more agile, the team decides any new features will be decoupled from the main build and run as isolated microservices.
First new feature required: a new notification system to update customers on the status of their orders. Every time an order changes (ie. status: "in process" to state:"sent") in the monolith PostgreSQL database, an SMS notification should be sent to the customer.
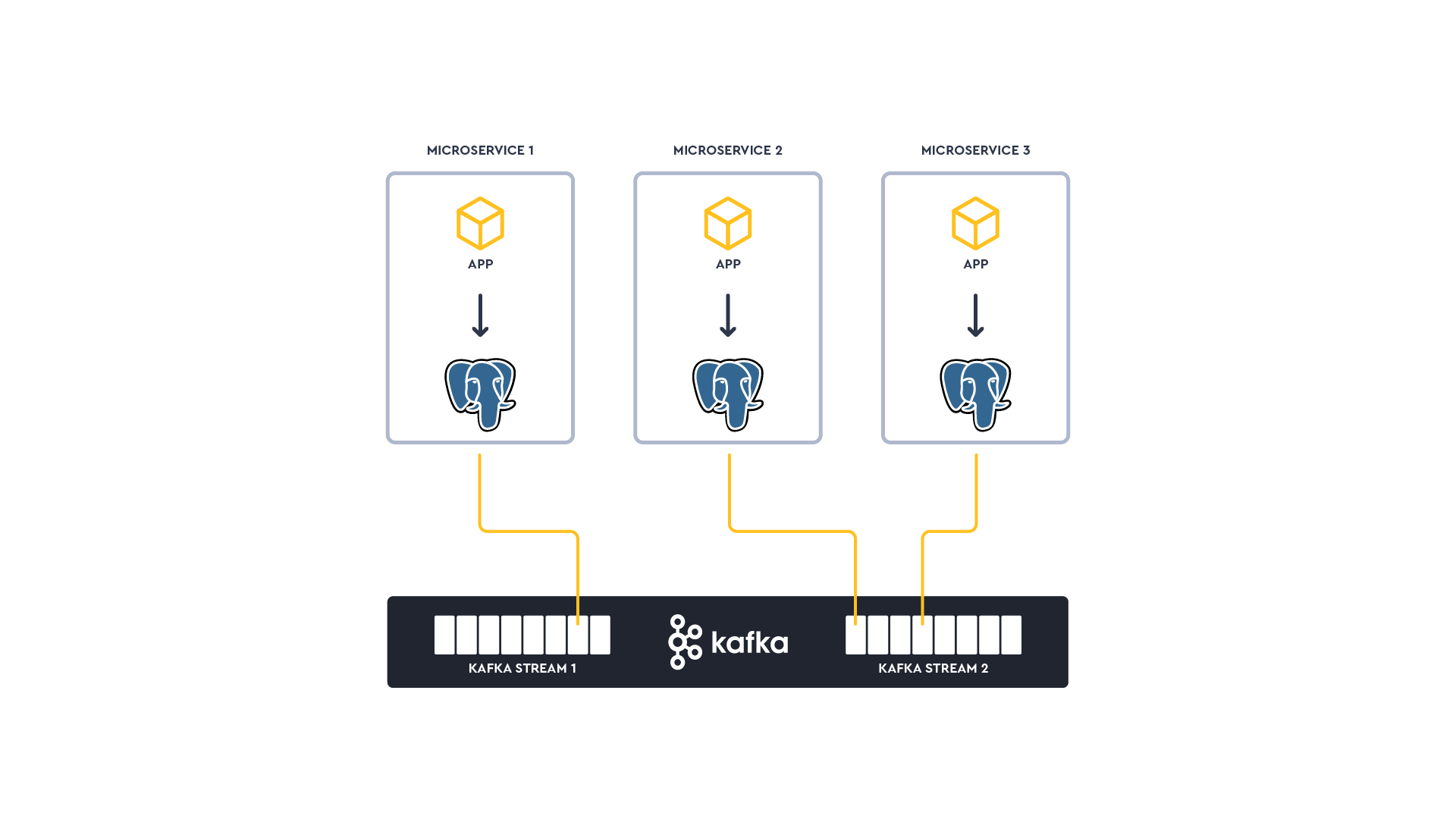
We’ll take a common microservice architecture pattern: The notification microservice must hold its own independent state. The state store will be an integrated PostgreSQL instance in each microservice.
This microservice needs to hold information about customers and their respective telephone numbers in a read-efficient store: Copying the entire customer database to the microservice is not an option.
Communication between microservices will be via actions/commands over pub/sub in Kafka in an asynchronistic fashion. This is in contrast to a typical API request/response.
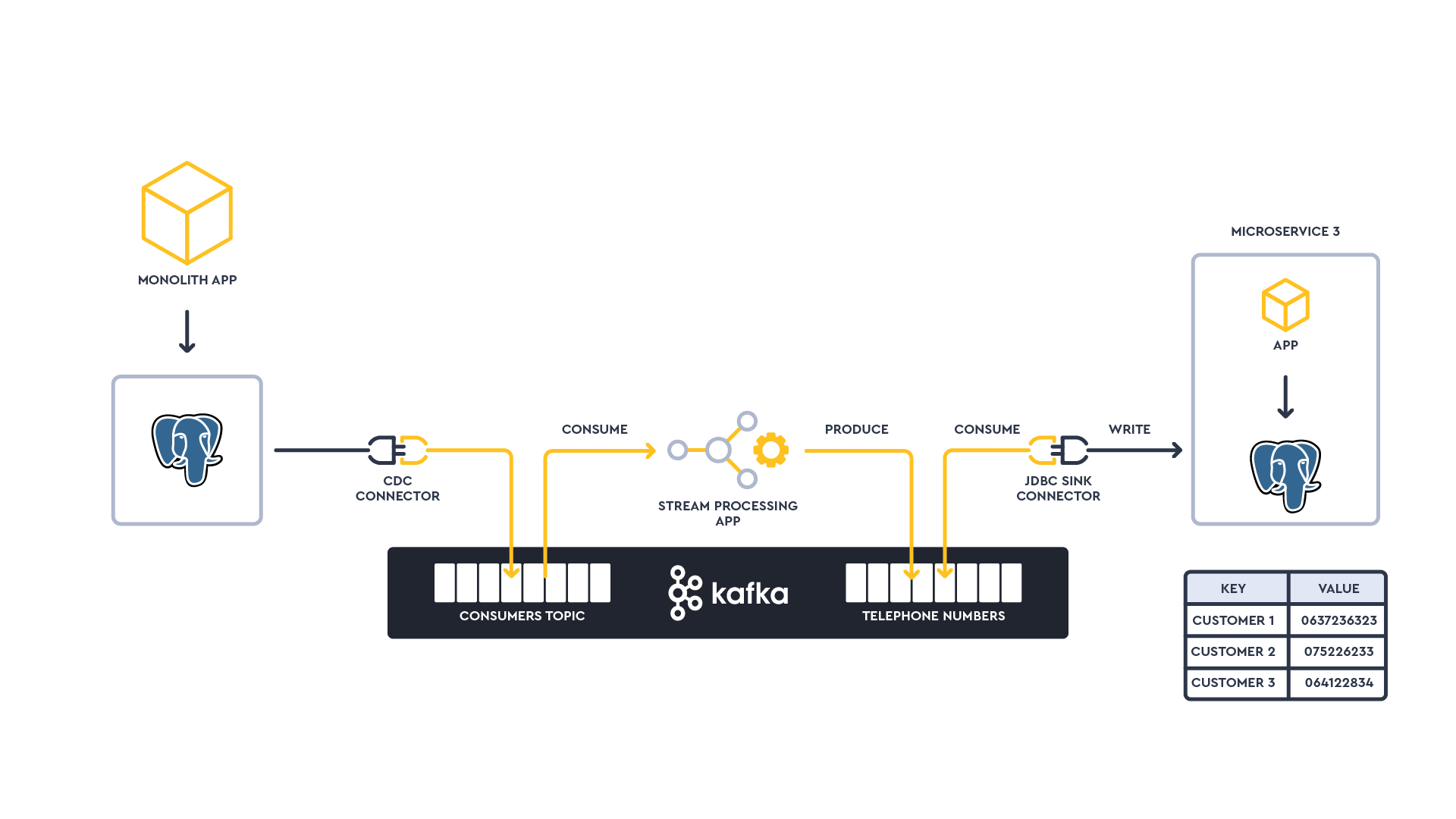
Overall, the architecture and process will involve the following:
Deploying a Debezium CDC Connector to stream state changes from Monolith PostgreSQL database to Kafka
Deploy a stream processing application to create a materialized view of Customers->Telephone Number into a new compacted Kafka topic
Deploy a JDBC Sink Connector to stream the materialized view topic to the microservice Kafka
Breaking up a monolith shouldn’t be trivialized. It’s going to require a lot of operational and engineering scaffolding; beyond what’s covered in this blog. Some of the most basic operational challenges to consider include:
How does the engineering team understand the data domain in the monolith?
Telephone number is considered PII. The proliferation of this data needs to be tracked and masked
How do we simplify the build and deploy of the stream processing application?
How do we ensure availability of the streaming app?
How do we rebuild the state in the microservice if necessary?
How to inject an event into Kafka to test the microservice?
How do we monitor the pipeline?
How do we explore events in a topic to troubleshoot the microservice if necessary?
How to ensure other engineering teams can explore metadata in order to be productive?
Many of these questions are why Lenses exists in the first place; to offer a single developer environment to explore, move and secure streaming data.
Let’s walk through the scenario.
If you're not a Lenses customer already...
Sign up for a free 7 day cloud Lenses+Kafka all-in-one environment. Within a few minutes you'll have a working demo environment to explore.
If you prefer to run on-prem, use the free Lenses+Kafka all in one environment
This instance will act as both our data store for our monolith as well as the data store for the microservice (of course normally the microservice would have it's own dedicated instance).
If you don't already have a PostgreSQL instance we recommend trying out Aiven's PostgreSQL cloud services (LENSES2021 to get $500 of free resource credits).
Alternatively, you could use something like AWS RDS or just run PostgreSQL as a docker.
A connection from Lenses to each PostgreSQL instance is required for the data observability & catalog. For this walkthrough, the same PostgreSQL instance represents both the monolith data store and the notification microservice data store.
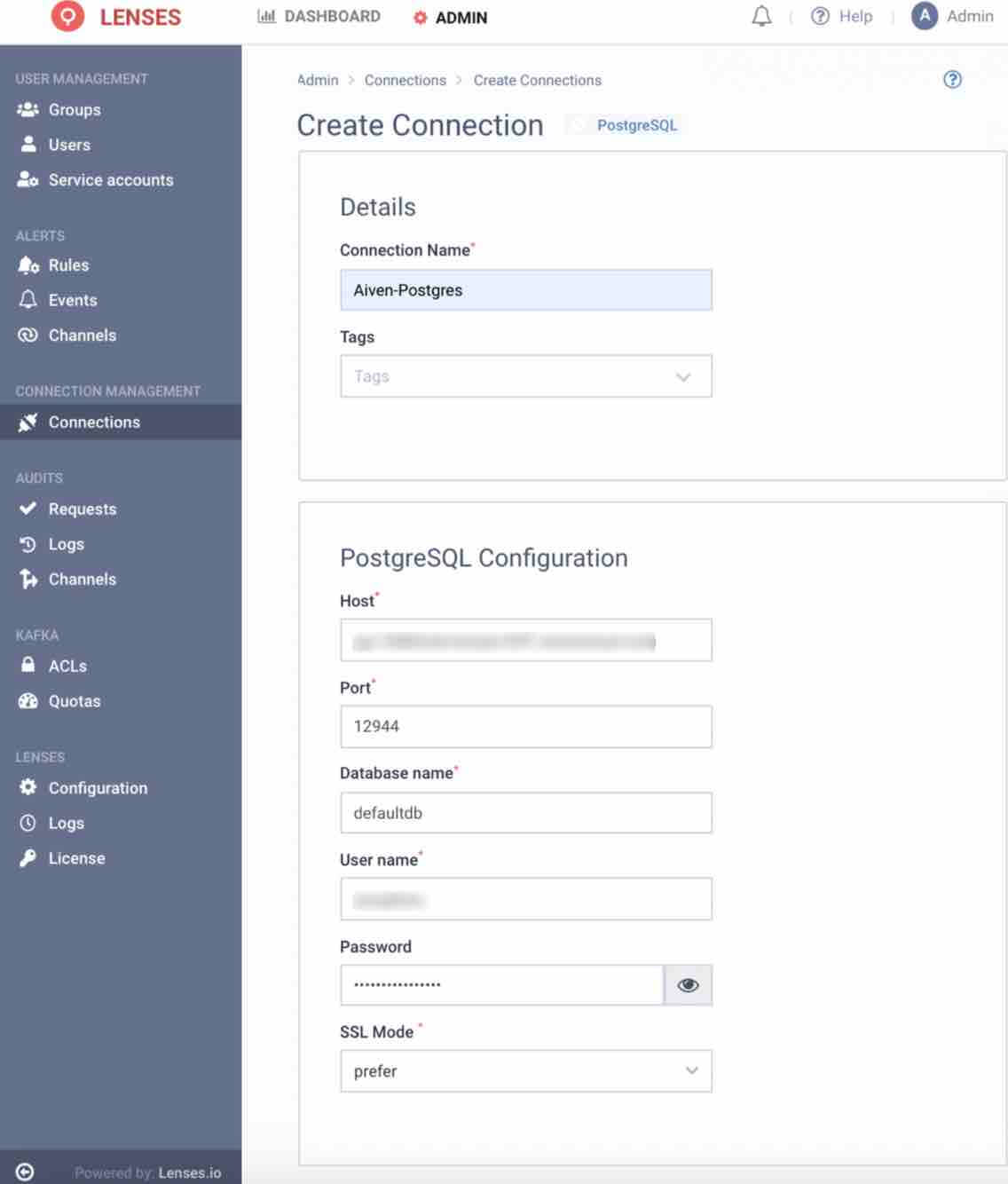
From the Admin menu, select Connections > New Connections > PostgreSQL
Provide a name for the connection such as PostgreSQL
Enter all the necessary connection details to your PostgreSQL including host, port, database name, username, password and SSL mode
Click Save Connection
To simulate data in the monolith database, we will create a Customers table with some sample data.
To create and insert data into a Customers table, use your preferred DB Client.
If you prefer to use PGAdmin run the docker:
From a SQL prompt, create a table customers:
NOTE: The contactDetails field will be populated with a JSON object such as the following:
2. Insert a few rows into the table and an update with the following SQL statements:
The new customers table and associated metadata should immediately be discovered and accessible in the Lenses Data Catalog.
Navigate to Explore, expand the filters to include your PostgreSQL connection and type in customer in the search bar.
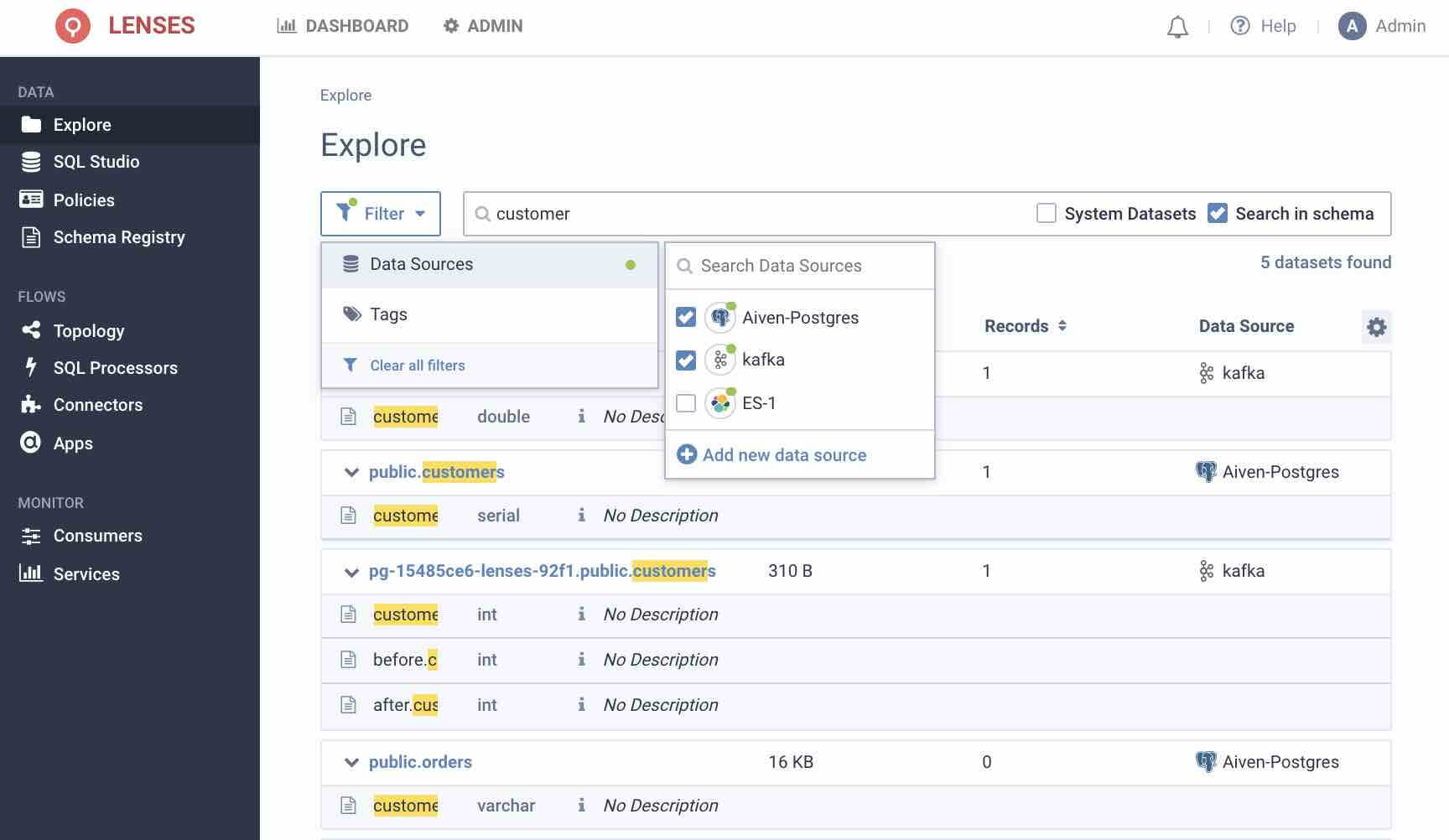
2. For more granularity in querying the data click on SQL Studio to enter a SQL prompt
3. Enter the SQL query:
NOTE: You may need to change the value of your USE parameter with the name of the connection you created earlier.
If you’re using the Lenses Box or Cloud environment, the Debezium CDC Connector is included in the Kafka Connect cluster’s plugin path.
If you’re using your own Connect cluster, the steps are easy just follow https://debezium.io/documentation/reference/1.5/install.html
In Connectors, select New Connector
Ensure you can see the CDC PostgreSQL source connector listed
Provide the Kafka Connect configuration for the connector for your PostgreSQL instance. Full Connect configuration can be found in the Debezium docs, but the following should work:
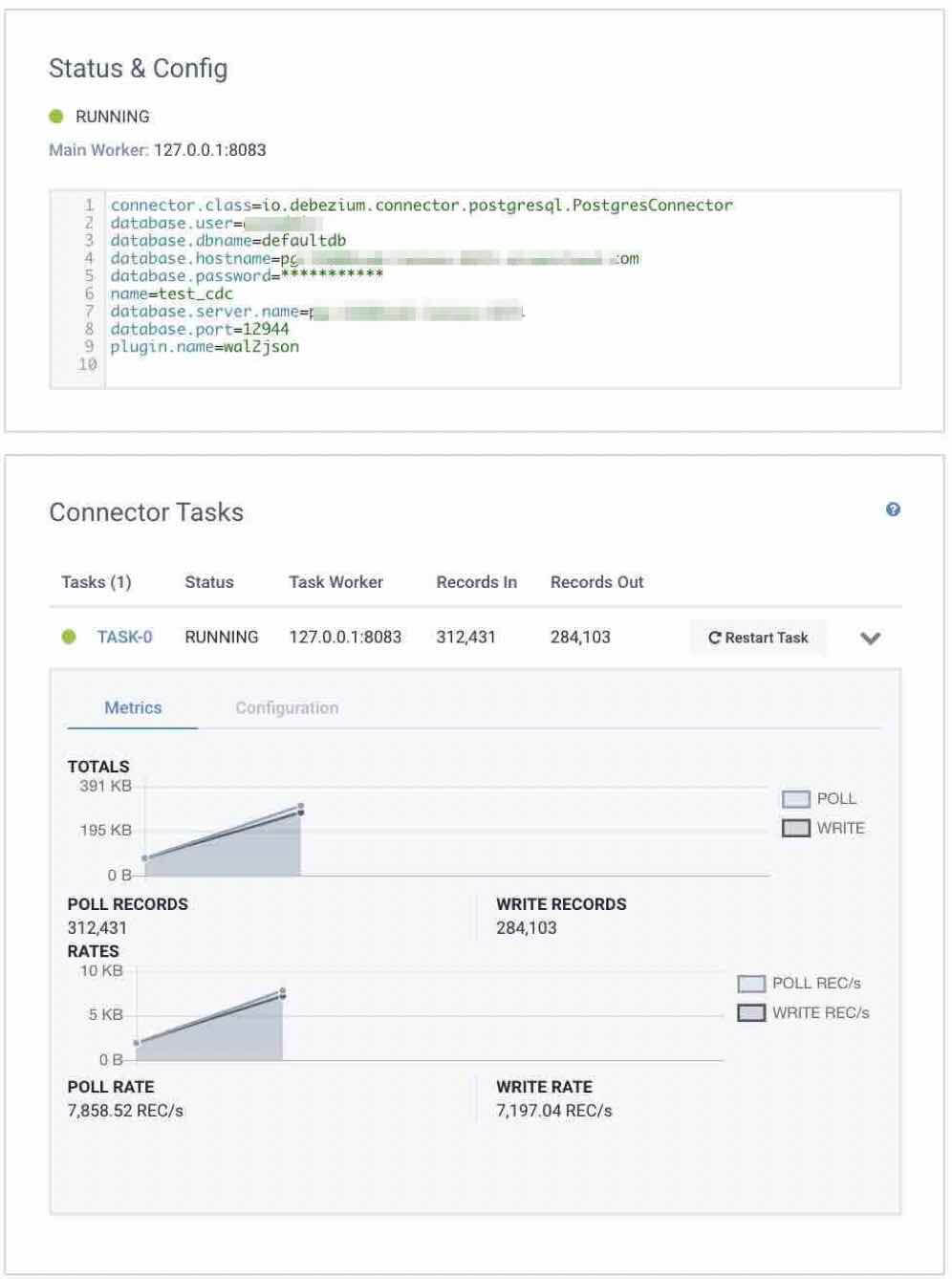
The table.whitelist parameter represents the change log the connector will source from.
NOTE: We would recommend you not to declare clear text passwords in your Kafka Connect configuration. See the blog on how to integrate your credentials with a secrets manager.
3. Click Create Connector to deploy the connector onto the Kafka Connect cluster
4. Ensure the connector has deployed successfully and data should appears when Task-0 is expanded after one or two minutes.
The CDC events from PostgreSQL will now be streaming into a Kafka named as the table it is sourced from.
In Explore view, verify the customers topic has been created by the CDC connector
The SQL engine that allowed us to query the PostgreSQL data earlier also works for Kafka topics.
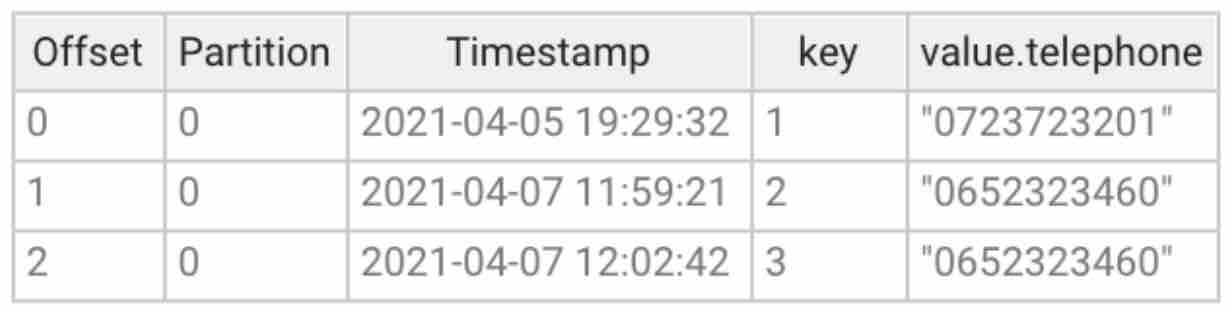
2. In the SQL Studio, run the query:
NOTE: You may need to change the name of the table in FROM in line with your environment.
Before sinking the data to the PostgreSQL instance of the microservice, a continuously running Streaming SQL application will be deployed to create a materialized view of all customers and their telephone numbers. This avoids sending a stream of stateless events to the microservice.
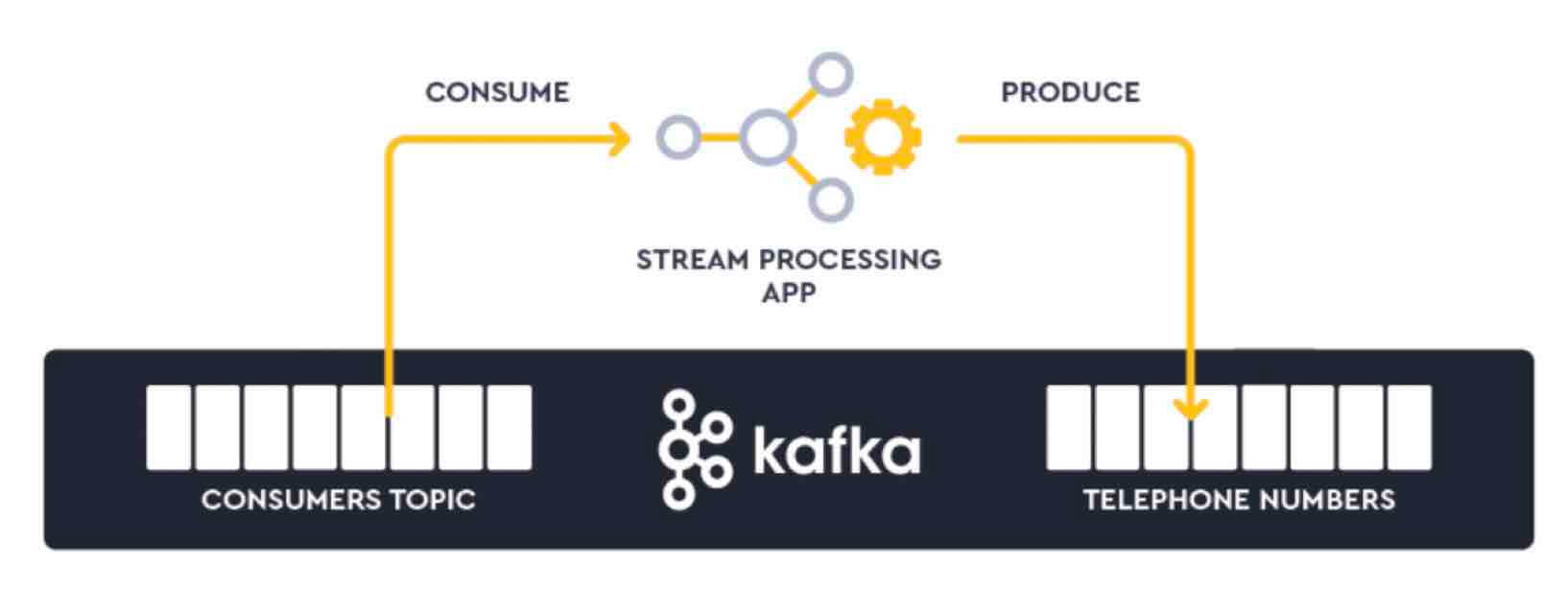
The application will be defined as SQL but underneath Lenses will build a Kafka Streams application.
The example application is very simple: it flattens the stream to create a KTable of customerId -> telephone number. But there are plenty of other more advanced use cases possible.
If you’re running Lenses Box or Cloud, this application will run locally. If you are running your own instance of Lenses, this will likely be deployed on your Kubernetes or Kafka Connect cluster.
1. In SQL Processors, select Create New SQL Processor
2. Paste in the following SQL Application logic
NOTE: Ensure you customize the name of the topic in FROM to match your environment.
The above SQL represents a similar logic to that executed earlier to validate that the CDC was sourcing correctly.
The results of the continuously running search will be populated into a topic customerTelephoneNumbers
This customerTelephoneNumbers topic will be considered stateful since we are using the SELECT TABLE clause instead of SELECT STREAM
AS_NON_NULLABLE function is required to instruct the KStream application that will be built that this field will not be null.
Click Create New Processor
Start the application by clicking Start SQL Processor
The application will be deployed.
5. A small number of events should be shown to have been processed. You may need to wait up to a minute or two.
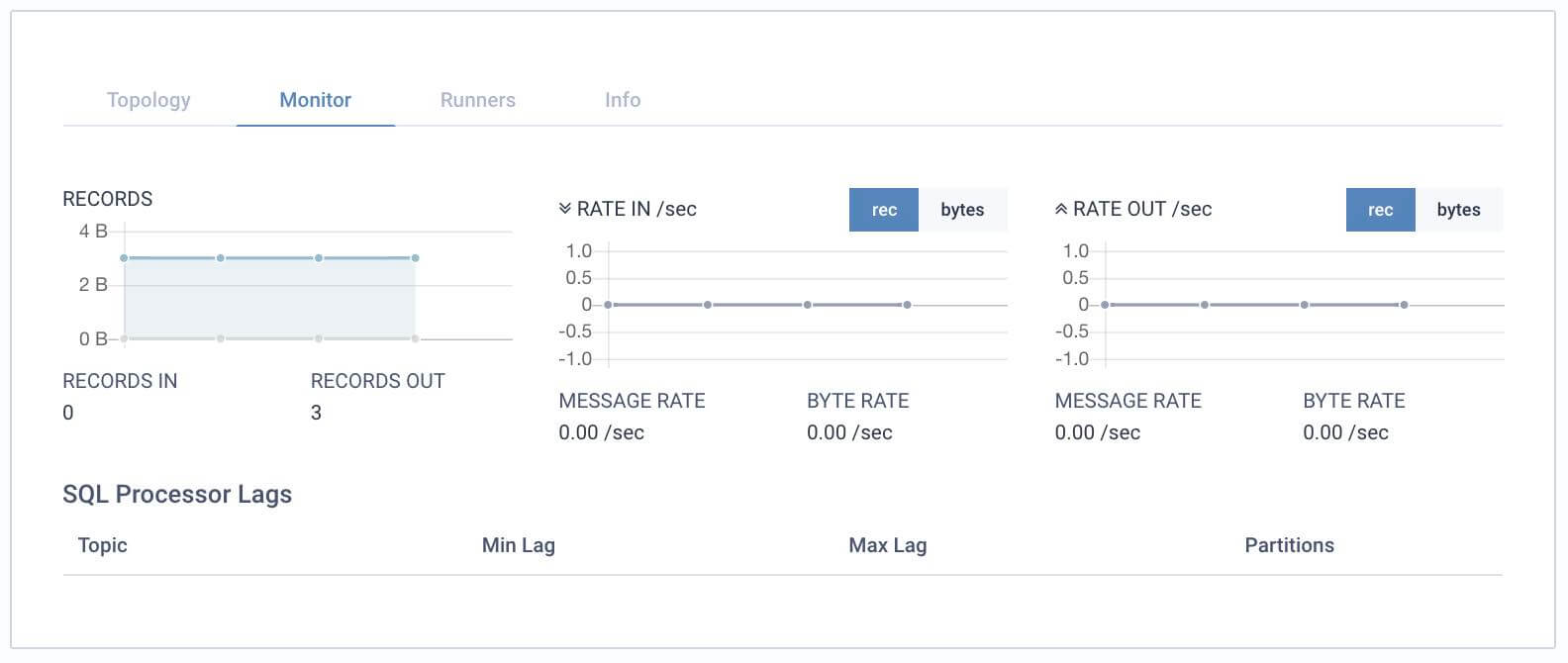
6. Return to the Explore view to drill down to the customerTelephoneNumbers topic to see the output of the running application.
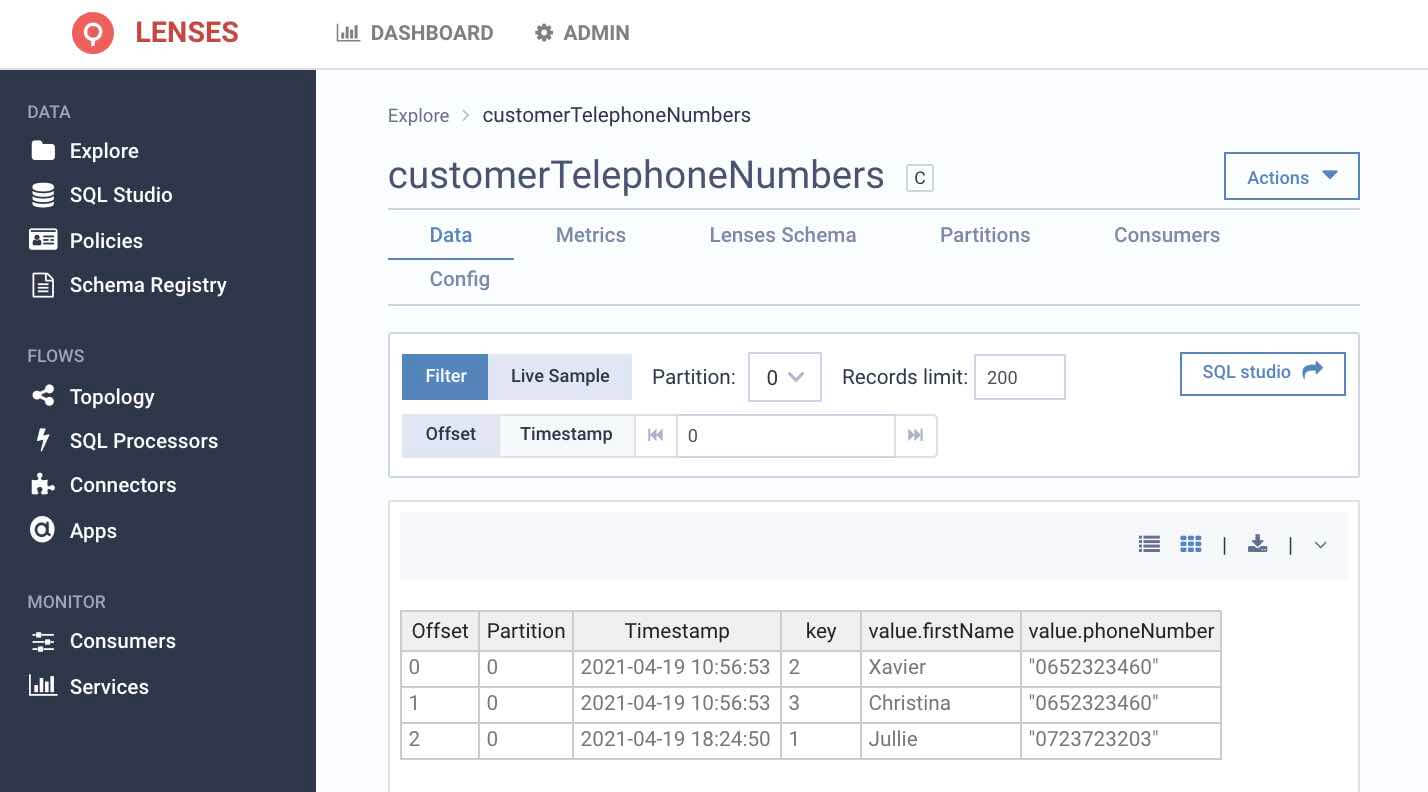
NOTE: Notice the topic created was configured as a compacted topic since we defined it to select a TABLE rather than a STREAM.
The materialized view of customerTelephoneNumbers topic should now be configured to be sinked to the PostgreSQL instance of the notification microservice.
1. In Connectors, select New Connectors and then JDBC Sink
2. Enter the following Kafka Connect connector settings to sink Kafka to PostgreSQL. Update the connection string with details of your PostgreSQL Instance
NOTE: A PostgreSQL Driver will be needed. For Box and Cloud environments, this is automatically available. If you’re using Lenses against your own environment, you may need to make one available on your Connect cluster.
As with before, in a production environment, do not declare credentials in your configuration or code. See here for how to integrate with a Secrets Manager
3. Click Create Connector
4. As with the CDC Connector, wait one minute or so before seeing data being processed when clicking on Task-0
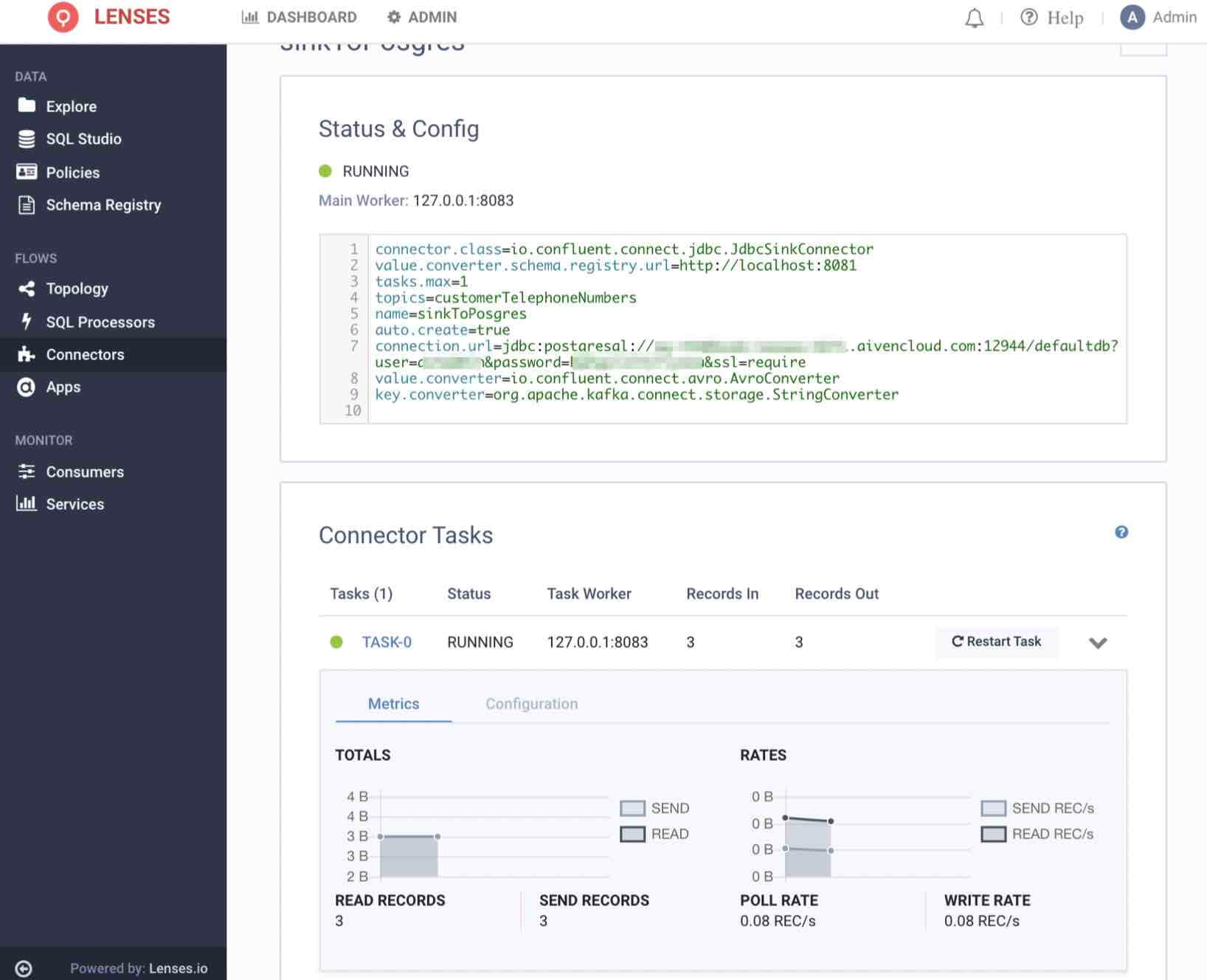
5. Finally, returning to the Data Catalog in the Explore page, verify that the new data entity customerTelephoneNumbers has been discovered.
NOTE: To see PostgreSQL entities, ensure you include PostgreSQL data source in the filters as shown in the screenshot
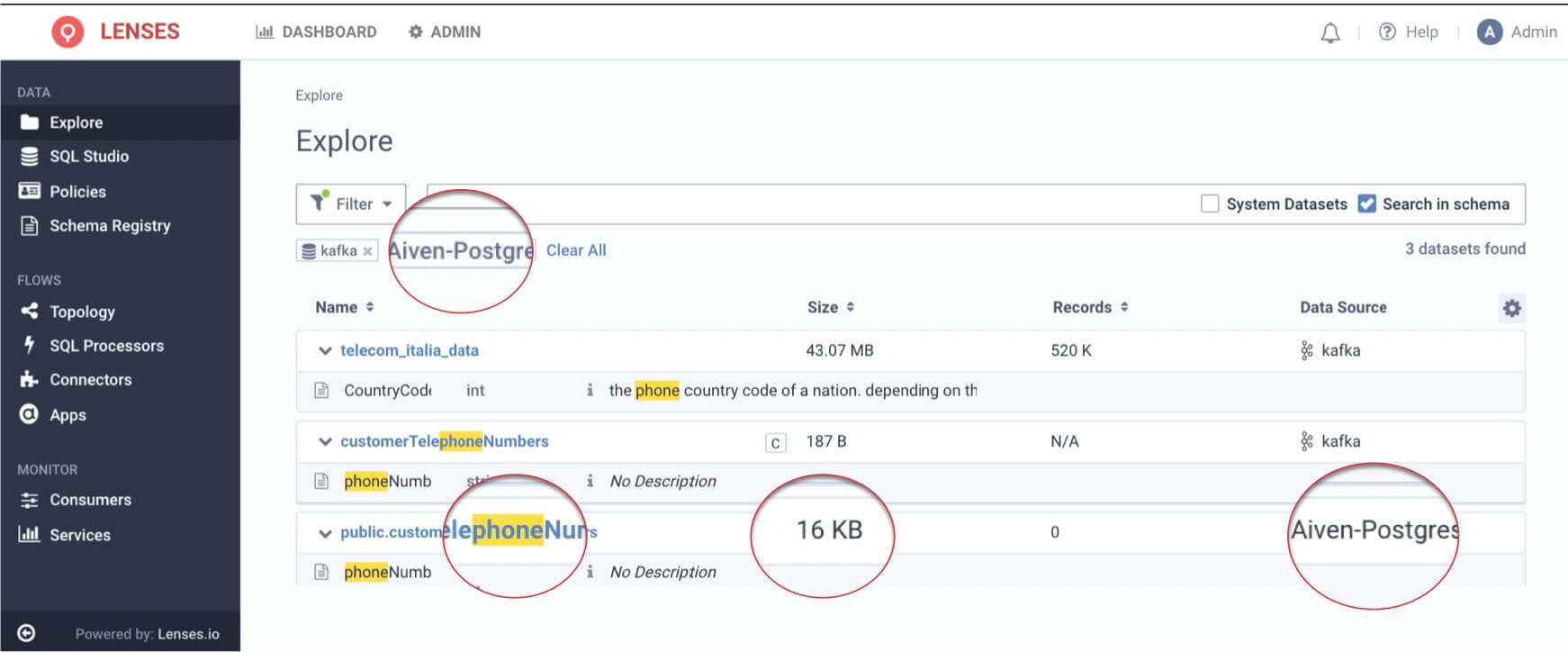
4. Select the customerTelephoneNumbers table to query data live in PostgreSQL.
Whether you're a Kafka expert and just need to do things faster or you're a Kafka newbie, this walkthrough has highlighted the importance of simplifying & offering great data observability & developer experience when operating the handful of technologies (Kafka Connect, CDC, Kafka Brokers, Kafka Streams, Schema Reg, Postgres, Kubernetes) required for a CDC pipeline.
Your next challenge will be around applying governance and compliance, so check out the links below.





