
Apache Kafka observability to avoid flying blind
Using a terminal for Kafka observability won’t work. Does everyone really have to be a Kafka expert to see inside your event-driven architecture?

How many tools does it take to change a lightbulb in Kafka?
Knowing what data you have in Kafka and across your streaming applications is like trying to see in the dark; then there’s the problem of access for the rest of your team.
The bottom line? Engineers shouldn’t all have to be Kafka know-it-alls to troubleshoot Kafka streams.
What is Kafka observability? Why bother?

Faster Kafka troubleshooting
of your Kafka streams

Team collaboration
A shared understanding of streams through metadata

Meet compliance
by discovering sensitive data in your streams

Accelerated delivery
of your event-driven applications

Cleaner data
for fewer incorrect dashboards & upset customers
“We knew that Kafka was critical for our business but we also knew it would be difficult to operate. Using Lenses helps us know where to look for the data we need so we can see what’s working across systems and apps.”

Laurent Pernot, Software Engineering Manager - Article
Best practices for Kafka data observability
Engineers struggle with the Kafka commands they need to learn.
Investigate Kafka by exploring events using SQL via a Kafka UI or API. Lenses understands your data irrespective of serialization: Avro, Protobuf, JSON, CSV and more.
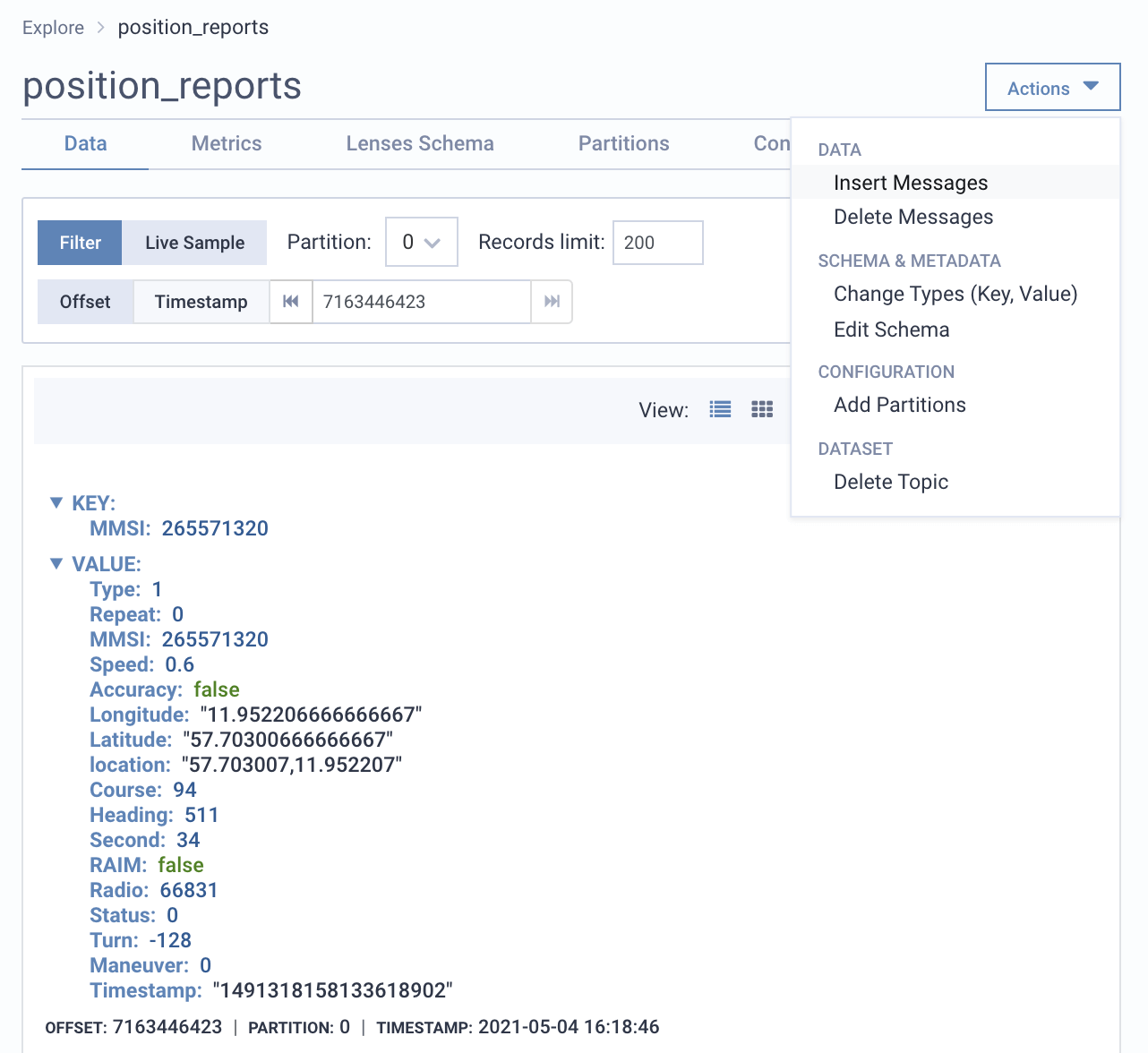
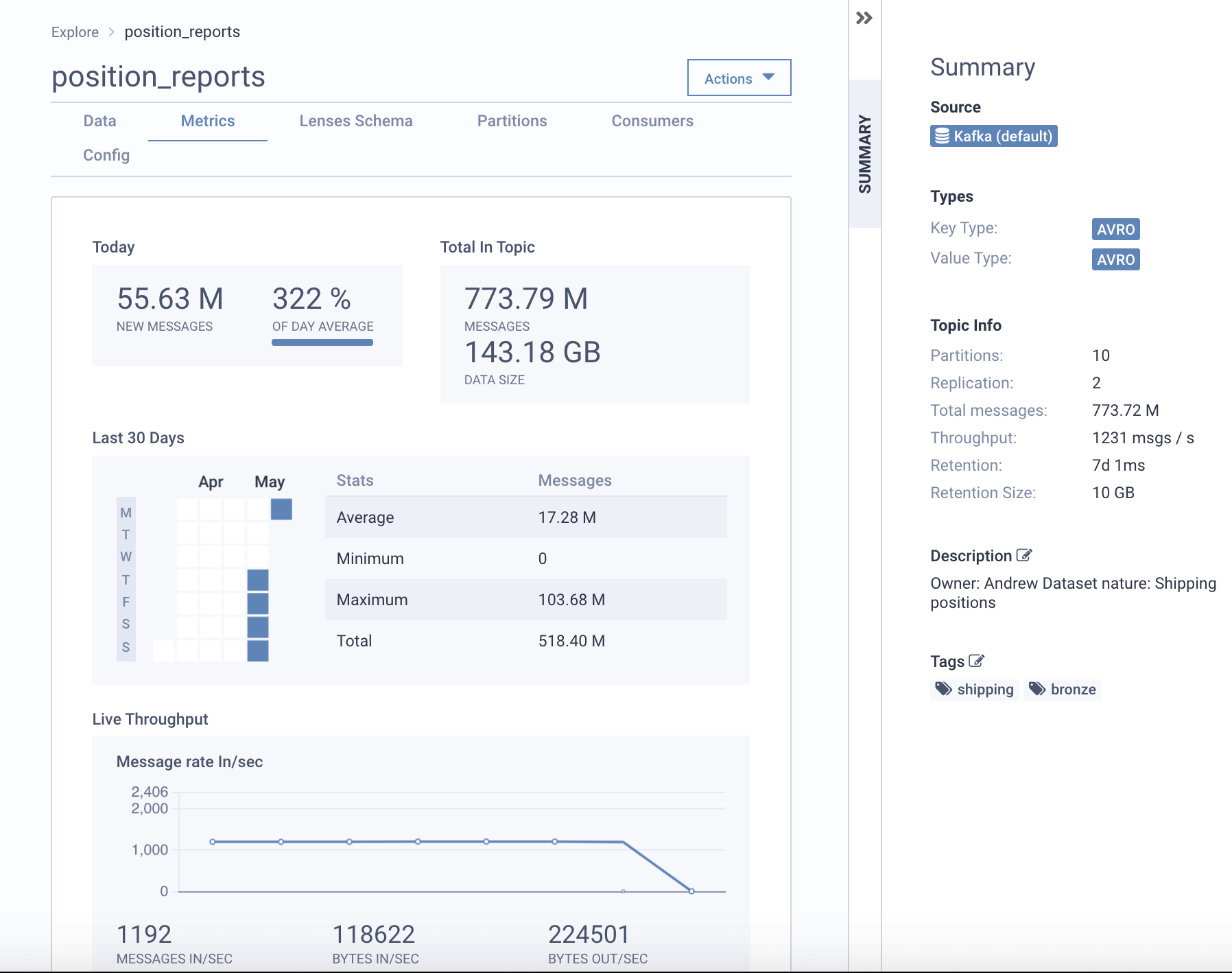
We have no visibility into our Kafka topic health.
Explore Kafka topic metrics such as throughput & lag as well as metadata such as partitioning & configuration.
How can we document what data we have?
Real-time discovery & cataloging of metadata across your Kafka, PostgreSQL and elasticsearch infrastructure.

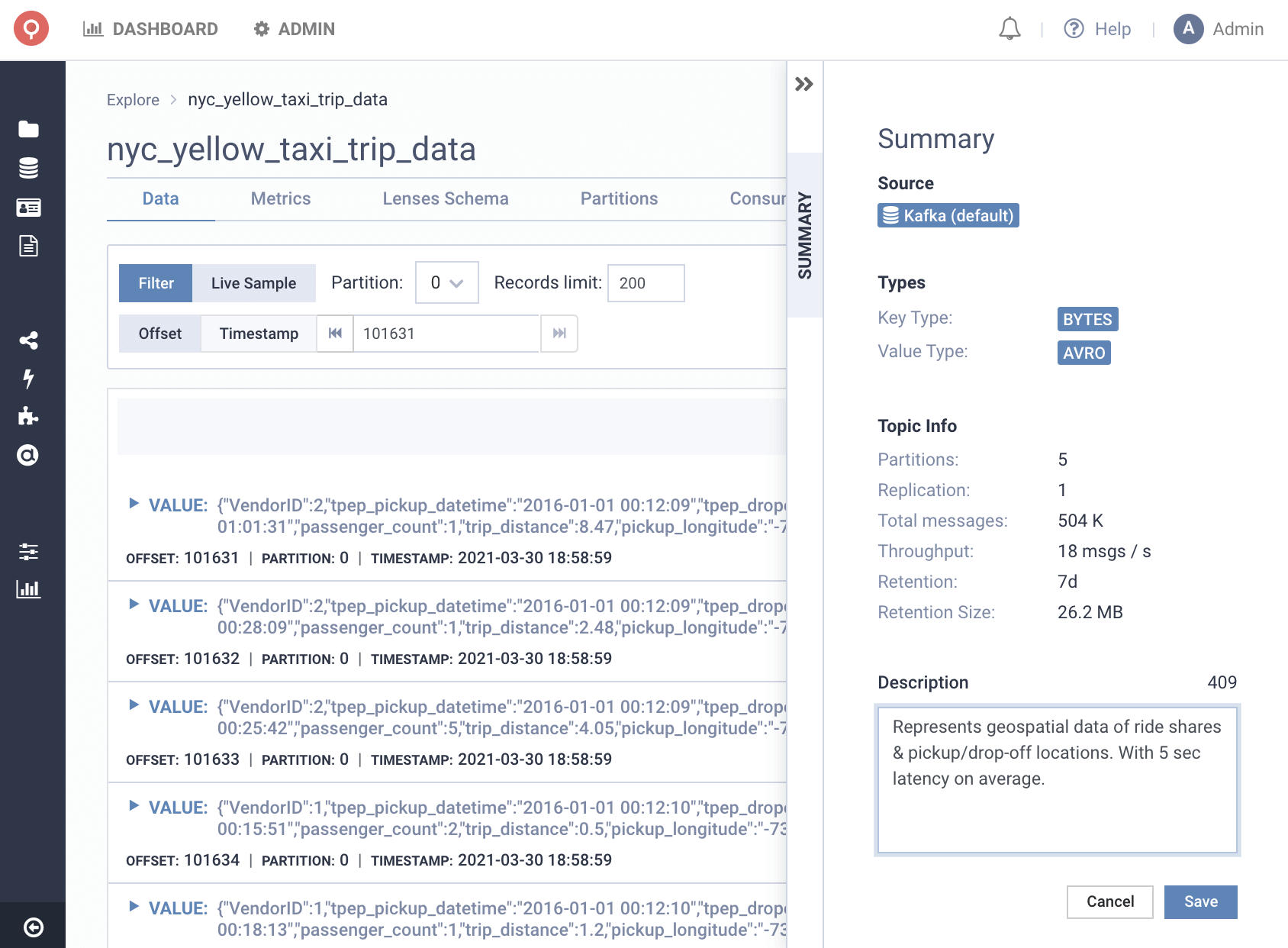
How can we better collaborate & add context to Kafka streams?
Allow engineers to add tags & descriptions to your Kafka and microservice data entities to better find and socialize data.
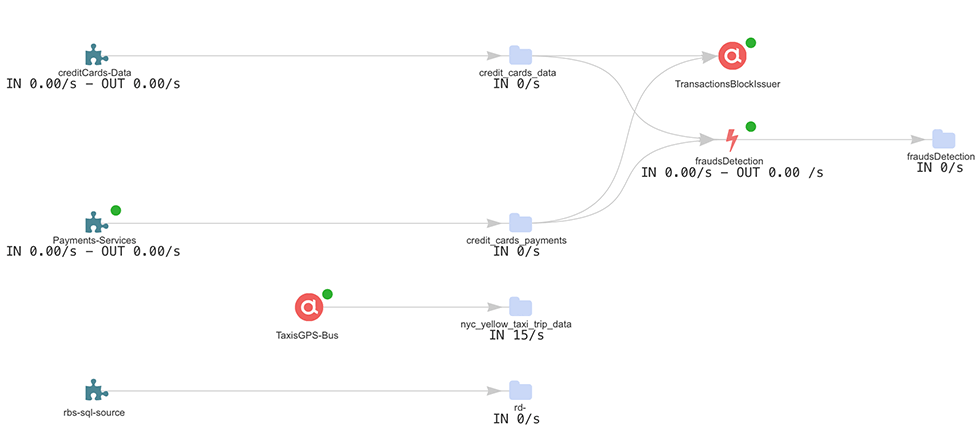
How can we track data lineage of our data pipelines?
Have a holistic view & data lineage across data stores, microservices and event-driven applications through a UI or Topology.

How can we redact sensitive data to stay compliant?
Categorize metadata across your applications, connectors and data streams, and then configure pseudonymization and masking to obfuscate fields.
Kafka observability architecture

What are the components of Kafka observability?
Data
Exploration
Flows
monitoring
Data
catalog
Data
masking
Metadata
tagging
Connection management
Case Study

Gaining 300 Data Engineering Hours Per Day with Lenses
With over 27 million monthly active users & more than 2.5 thousand coders, learn how this mobile gaming company improved developer productivity through Kafka data observability.
How to
Navigate data with SQL
Our Snapshot SQL helps you find those needles in a haystack of real-time data. We walk you through how it works.
Explore data
Debug microservices
React to live data
To play this video, accept functional cookies in your privacy settings.
Navigating & Querying Apache Kafka with SQL from Lenses.io on Vimeo


