By
Sep 20, 2021Alex Durham

Alex Durham
Here we are, our screens split and fingers poised to forage through two days of fresh Kafka content at Kafka Summit Americas.
Tweet us your #KafkaSummit highlights if they’re missing here and we can add them to the round-up.
This year, Jay Kreps talks about the paradigm shift from a giant spaghetti data landscape to a data mesh for organizations. Where we once focused on the org chart as a taxonomy for understanding how companies work; these days we turn to application and data architectures.
As Marc Andreessen said at the turn of the decade, “software is eating the world”. Customers continue to demand better digital services. But how do we build an event-driven company in software? How do we make it scalable not only in systems terms, but in organizational terms?
By moving away from centralized, monolithic architectures with highly coupled pipelines, operated by specialized engineers, and moving towards:
A structure of distributed data products
Oriented around domains and owned by independent cross-functional teams
Using a common, best-of-breed data infrastructure.
Essentially, as Jay Kreps or a clever copywriter from Confluent puts it: moving from data mess to data mesh.
Here are a handful of sessions that work through the specifics of achieving a data mesh.
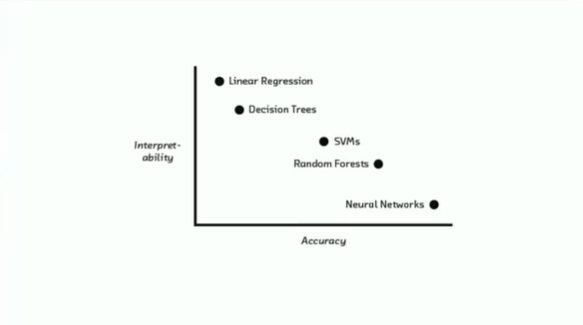
This talk tees up both the technical and ethical dilemmas we face surrounding data observability in a world of fiercely disruptive and powerful technologies. If a machine-learning model and the events driving it aren’t interpretable, how can we fix degrading performance, mitigate unforeseen biases, or prevent data loss?
This year’s Kafka Summit America saw an overwhelming number of sessions around the real-world impact of Kafka, and the organization-wide flow of events required to support it. The ASRC’s session delves into how they ingest data from 2,500 satellites operating in space, applying machine learning to interpret that information and make sure it is observable and actionable for human operators in real-time.
Small things can have a big impact when it comes to making streaming data operable. Zooming in from outer-space to the inner-workings of Kafka, Marios and Andrew tell stories from the trenches on how temporary workarounds for creating Kafka Topics in production can cause astronomical issues.
Who has stakes in your Kafka Topic? Who needs access to the data outside your team? Beyond the worst case of bringing down a cluster with the wrong Topic configuration, Marios explains the settings and fields you need to consider to make your journey to production a success.
He also throws in some Greek philosophy for good measure.

From trains and planes to cars and ships, there’s always an interesting event-driven story to be told or application to be built around transportation - and a set of streaming data attributes to tell that story. Here Robin Moffat explains how you can capture that data in shipping, how you can process it in a stream, as well as some examples of what you can do with it.
We’ve gathered some interesting insights on streaming for shipping too, so found this one particularly enjoyable.
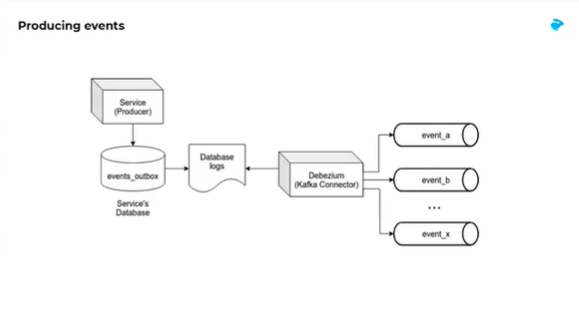
The teams at logistics company Loggi had a growing number of services, with many different ways of exchanging information. On a mission to make their engineering and data chapters more productive, they set out to manage Kafka’s flexibility by defining some company patterns that would scale well as their engineering team grew.
Here they explain how they did this by evolving from the widely used CDC with Debezium and Kafka as a way of communicating between services, and designed a way to deliver more than a million events per day, in production, and in different flavours.
For those supporting US Veteran services, the data they need is complicated and hard to reach, making it tough to ensure fast service delivery. On a mission to enable these core teams, Chief Technologist Robert Ezekiel and team need to act on data across siloed systems, each with their own security and service-level agreements, as well as the ability to update their own data and other systems when a Veteran interacts with the service.
In the spirit of celebrating all things event-driven data mesh, this talk promotes intentional data architecture design and standardization for teams to deliver their respective, world-shaping applications.
Behold, an impressive case study in event tracking at scale. Consdata’s Marcin Mergo explains how to find a specific event and visualize this journey through Kafka Topics, with these particular events fired from messages delivered to end users at the bank Santander.
Why bother? Depending on the use case (and application), events will take different paths through Kafka; and given that they process millions of events per hour, visualization for the teams behind them is essential.
This talk is particularly useful for those up against processing data from a wide variety of edge devices, and also make the steep governance steps necessary to share, publish and consume events to public and private entities.
Their platform requirements also fit squarely with data mesh principles: distributed data products that are modular - i.e. can be used independently.
That's the longlist for this year.
If you're hungry for yet more Kafka content, see our round-up of Kafka Summit Europe 2021.



