By
May 16, 2021Alex Durham

Alex Durham
In keeping with tradition, we’ve chowed our way through the entire all-you-can-eat buffet of Kafka Summit Europe 2021 talks to bring you the best content to catch up on.
Jay Kreps’ keynote this year addresses a few Kafka-shaped elephants in the room, as well as an overall shift in the way event-driven business is surfacing.
On the technology front, Confluent announced new support for Kubernetes as an orchestration layer running on Kafka in a private cloud. He added a quick reminder of the eagerly-anticipated GA of Kafka without Zookeeper to “dramatically simplify the operation of the system”.
Making Kafka truly enterprise-grade is a topic that’s been thrown around over the past few years, without really seeing it come to fruition for the community at large. But this now seems to be changing.
Today, Kafka really is driving software that sits at “the center of how businesses transact with their customers, how they carry out what they do”, as Jay said.
Managed services are taking out nearly all heavy infrastructural lifting, the pandemic has expedited the move to Event-Driven Architectures (EDA), and EDA governance frameworks are taking center stage across the two days of talks.
We were also happy to see significantly more women speakers taking to the stage than in previous years.
Here’s a rundown of our favorite talks that stay in step with the ‘Kafka-driven business’ theme.
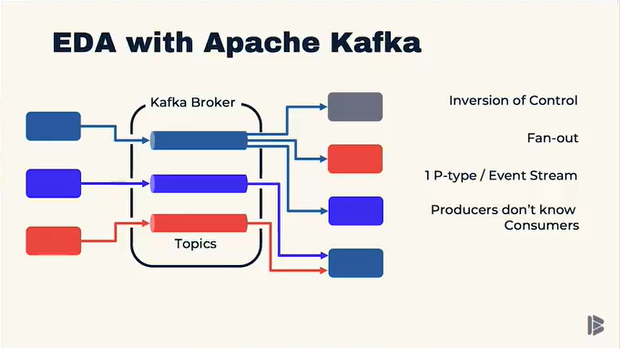
Except for a handful of bigger organizations, use of Kafka so far has largely been to pipe data integration - a handy use case but a crying waste of Kafka’s potential.
If you’re experienced with Kafka for data integration but not connecting applications in an event-driven environment, this practical talk by Bogdan Sucaciu from Deloitte Digital about what an Event-Driven Architecture is, and how it works, might be interesting for you.
It really simplifies this beast of a topic.
Governance governance governance. Engineers may want to studiously avoid this one like a hole in the head, but 2021 is the year that data engineering gets to grips with the billion (or at least million) dollar question:
“How do you govern an entire ecosystem of event-driven applications, without centralized, lengthy ticket-based processes, rigid rules and manual effort?”
Alejandro Alija and Marco Laucelli of Galeo Tech give a breakdown of how they did it for a large insurance company; a framework with data cataloging as its main engine and implemented using GitOps. So go forth and govern your EDA.
It looks like Galeo Tech did a lot of this development themselves, but we’d argue that today you shouldn’t have to.
The Internet of Things is getting huge, meaning a growth in the volume of data being sent between technical devices.
Challenge #1 is that traditional enterprise IT infrastructure is just not suitable for hundreds of thousands of messages per day. Challenge #2 is the massive scalability and bi-directional communication required for these millions of devices to deliver the near-instant value we expect.
Run by Margaretha Erber and Dominik Obermaier, this MQTT <> Kafka breakout session is a useful assessment of why and also how MQTT and Kafka can complement one another best in the context of scalability, weighing up the pros and cons of different clients and approaches.
P.S. Here's how we designed a Kafka Connect connector architecture for more efficient data observability and integration from technologies such as MQTT.
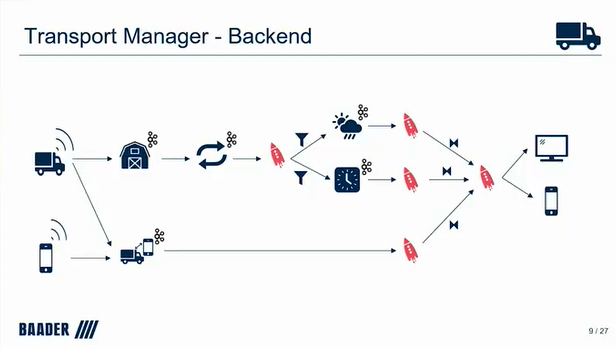
Here, Patrick Neff of BAADER gives a practical, real-world explanation of how data analytics for a food processing factory can be solved with Apache Kafka.
This is interesting from an EDA perspective, with BAADER also incorporating data such as weather and ETA to help improve the timing of poultry delivery.
But what’s perhaps more interesting is how less-technical business users such as data scientists are now able to generate value from Kafka by building stateful and stateless stream processing applications. This means the developer and business experience is taking a front-seat as event-driven applications become the norm.
Where 75% of an engineering team used to be dedicated to making sure Kafka was scalable, the heavy lifting can now shift to consumer-facing applications and discovering new data products.
Over the past year, many organizations with five year projects to break up a monolith had to double down and move to microservices within months, or even days.
The acceleration of such projects has made topics like fault-tolerance even more pressing, particularly with various dependencies across applications.
This session by Asaf Halili of Oribi talks about building fault-tolerant microservices and avoiding excessive retries by using different kafka topics and DLQs to store failed transactions when a database goes down.
It wouldn’t be a Kafka Summit without a handful of Goldman Sachs presentations about their Transaction Banking Platform they are building on AWS MSK.
Here, they cover how they recover and manage transaction errors in their platform. Just like in Asaf’s talk, they define specific topics to ensure there is a delay in retries followed by DLQ topics for persistent errors.
Nice talk from Aiven about best practices for structuring your data in Kafka. Everything from the size of events and fields you should hold in your keys, to how to use headers and add trace information.

Thoughtworks are quite the thought leaders when it comes to building Event Driven Architectures and Domain Driven Design. Here Simon shares top mistakes when building EDAs, everything from over-engineering your architecture to ensuring your focus on choreography over orchestration of your events.
If you’re a fan of Thoughtworks, check out How to build the data mesh foundation from Zhamak Dehghani. Her thinking always adds great value.
Security is so critical that this deserves a call out. Here’s a worthwhile presentation from our friends in Hashicorp on applying a zero trust security model, offering a good developer experience for managing secrets and encrypting data flowing through Kafka with the help of Vault.
Bayer is a Life Sciences company. This talk is worth mentioning because of the complexity of datasets they need to work with and the impact their work can have on scientific research.
They have developed complex pipelines that allow them to process and semantically analyze data related to scientific and medical research. This includes doing Natural Language Processing on short and long text documents (some documents are 1000s of pages).
This allows both Bayer teams to more easily access and find research data but also allows them to offer new services to the industry.
Igor shares some best practices when developing your own Kafka Connect connector, including applying validation of configuration and how best parallelize workload across tasks & mapping to partitions and offsets handling. It’s good to see some of the inner workings of Kafka Connect even if you’re not developing your own Connector.
That's a Kafka Summit wrap (with a moreish EDA filling).
Kafka Summit APAC and Americas are on the way, and we hope to see you there.
Press Release...
Lenses
Where data streams meet AI. ...
Alex Durham



