By
Mar 05, 2021Alex Durham

Alex Durham
Once upon a time (2017), in an office far far away, you may have been cornered in a conversation with someone from Legal about GDPR. It could have gone something like this:
“You there, Data Engineer”
“Yep, that’s me”
“What PII do we have residing in this Apache Kafka database?”
You probably mumbled something about Kafka not being a database.
“And who can read/ write the data? To which topics?”
Avoiding eye contact, you returned to the sea of Kafka Jira tickets. Those were the days.
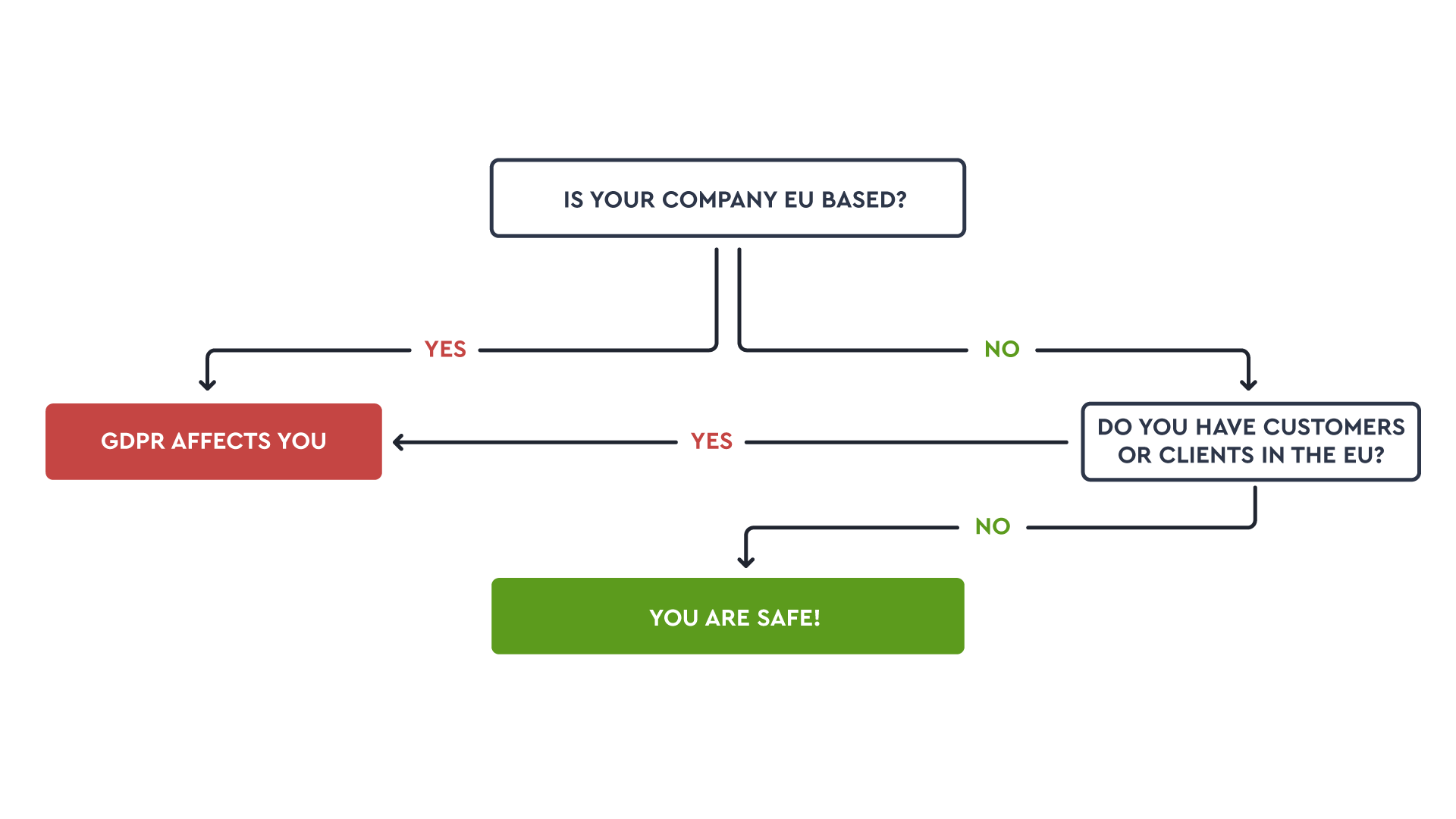
But perhaps, like many in the process of building a company’s central nervous system, the pandemic hasn’t diverted the compliance pressure that comes with adopting streaming technologies - but doubled down on it. Especially when your organization is on a quest to drive adoption of data technologies.
Fines imposed under the General Data Protection Regulation have increased by almost half over the past year, as European authorities flexed their regulatory muscles despite disruption caused by COVID-19. Take Norway’s Data Protection authority, for example. In January of this year, they planned to fine dating app Grindr 100 million Norwegian crowns (a lot of money).
The GDPR (or general data protection regulation) aims to protect people with regard to the processing of PII (personally identifiable information) and the free movement of such data.
Comparable regulations also exist in the US and worldwide: CCPA and HIPAA operate on similar data protection principles.
These regulations require knowledge on:
What PII data an organization holds (identify and keep track of PII in Kafka)
How PII is processed
The mechanisms to retrieve or remove them on request.
We’ve gathered insights from our heavily-regulated and Fortune 500 customers on what good compliance for Kafka means in relation to GDPR.
Examples we explore here are not legally bullet-proof, and we try to look at their limitations as well as their successful business cases.
Nonetheless, we hope they will help you demonstrate a reasonable level of protection for your PII when it comes to operating technologies like Kafka.
Firstly, it’s worth calling out the elephant. Kafka wasn’t exactly designed with GDPR in mind:
Kafka is an immutable log, meaning in many cases you can’t delete events.
It encourages a high volume of producers and consumers. Having many consumers of PII is a legal department’s worst nightmare - data proliferation.
What’s more, because there isn’t a peer-to-peer flow of data between applications, encrypting data can require advanced DevOps practices.
It’s difficult to see inside Kafka and know where you might be breaching GDPR. There are no granular access controls for Kafka other than ACLs. So you will need tooling.
Many feel that Kafka is a database and therefore meeting compliance is much the same as a traditional DB. Wrong.
GDPR is not a checklist. It involves continuous improvement of data operations (DataOps) and data management.
To stand a chance of keeping your Kafka GDPR compliant, you need to practice good housekeeping & security operations.
You won’t know what to protect if you cannot see inside Kafka.
Good identity & access management is in place.
Separation of duty policies & approval workflows.
Collect and monitor real-time data via audit logs & performance metrics.
where necessary.
Loop in business & legal teams with practices and guidance.
Here’s the heavy and helpful stuff for legal. We’ve organized practical solutions under each of the seven guiding principles, with some overlap.

First up, you need a lawful basis for collecting and using personal data.
Kafka of course cannot ask the customer if they consent, but it can store this information as a reference for future processing.
Your customer-facing teams need to capture and record who has consented to their data being used - and how it is used. This means being able to track in Kafka which data you can process in which applications and by which users.
If you’re developing stream processing applications, you’ll need access to this consent.
Imagine you want to develop an app processing customer data - a recommendation engine for example. You have one of two options:
The only data you store in a Topic has been consented to (then, how would you revoke it later?)
You join a Kafka stream with another stream (or a KTable lookup would be more appropriate) with a list of approved customers. Only a stream with a successful join is released. Here’s an example using Lenses Streaming SQL:

This principle says you must be clear about your purposes for stream processing from the start. This means teams need to record 'purpose' as part of your documentation and specify these in your privacy information for individuals.
If your customers ever request to access the data you store about them, you should be able to serve them with a copy of their data. This report must include the various ways you’re using their information.
Whilst manual documentation is still undoubtedly needed, much can be automated in your CI flows through metadata.
Metadata in Lenses can be exposed in two forms:
Your streaming app metadata (e.g. description of the application logic) and
Your data metadata (e.g. how this event was generated or whether the event is categorized as PII). Both can then be accessed via the App Catalog and Data Catalog respectively.
Metadata may come from your schema definition or via custom tagging and categorization.
It can work like so:

Data minimization is processing just the right of personal data needed for the stated purpose.
To keep the data you’re processing to a minimum, you first need to discover and understand which data is PII, before classifying its impact (DNA sequencing information has higher impact than your customers’ pets name for example).
This helps you know if you need to worry about Data Minimization at all.
You can create and assign tags to PII and its metadata in Lenses to meet the following requirements:
Is it PII?
Is it ‘Adequate’? Does it contain the data needed to sufficiently fulfil its purpose? E.g. ‘Customer-ID’ & ‘ZIPcode’ ’ are required for this analytics dashboard to show % distribution of customers by region.

3. ‘Relevant’: Does it have a rational link to that purpose?
Yes, Customer-ID and Zip Code are relevant. ‘Telephone number’ ’ doesn’t relate to the purpose.
4. ‘Limited to what is necessary’: Are you holding more than you need for this purpose and timeframe?
You may only need a sample of 10,000 customer records to understand the distribution of customers by region.
How can this be applied in the Kafka-sphere? Users should be segregated. Certain users should have some fields exposed in a topic and others pseudonymized. If they need wider access, an employee with higher privileges can grant them via an approval workflow.
Read about the life of PII.
Once the purpose of PII has been fulfilled, your customers have the right to request that you totally erase their data.
Does the person exist in Kafka?
Which topics do they exist in?
Can I quickly verify that they exist or have been deleted?
Not to mention Kafka doesn’t forget. It only knows how to expire or compact events.
The easiest way to remove messages from Kafka is to simply let them expire, or set a custom retention period.
There is a Kafka Admin API that lets you delete messages if they are older than a specified time or offset. This API can also be invoked via Lenses to ensure it is protected with access controls and audited. An example being with the Lenses Snapshot SQL:
Unless topic partitioning has been set by customer, this is unlikely to be useful however. If the topic has been configured as “compacted”, Kafka can delete records sharing the same _key to only leave the most recently generated event after a clean-up policy. Within Lenses, this can also be invoked with the Lenses Snapshot SQL such as with a command:
Here, a tombstone is being set: the process of setting a NULL payload for a specific unique _key that we want to delete the records for. Once again, this is only likely to meet an edge case of right-to-be-forgotten scenarios.
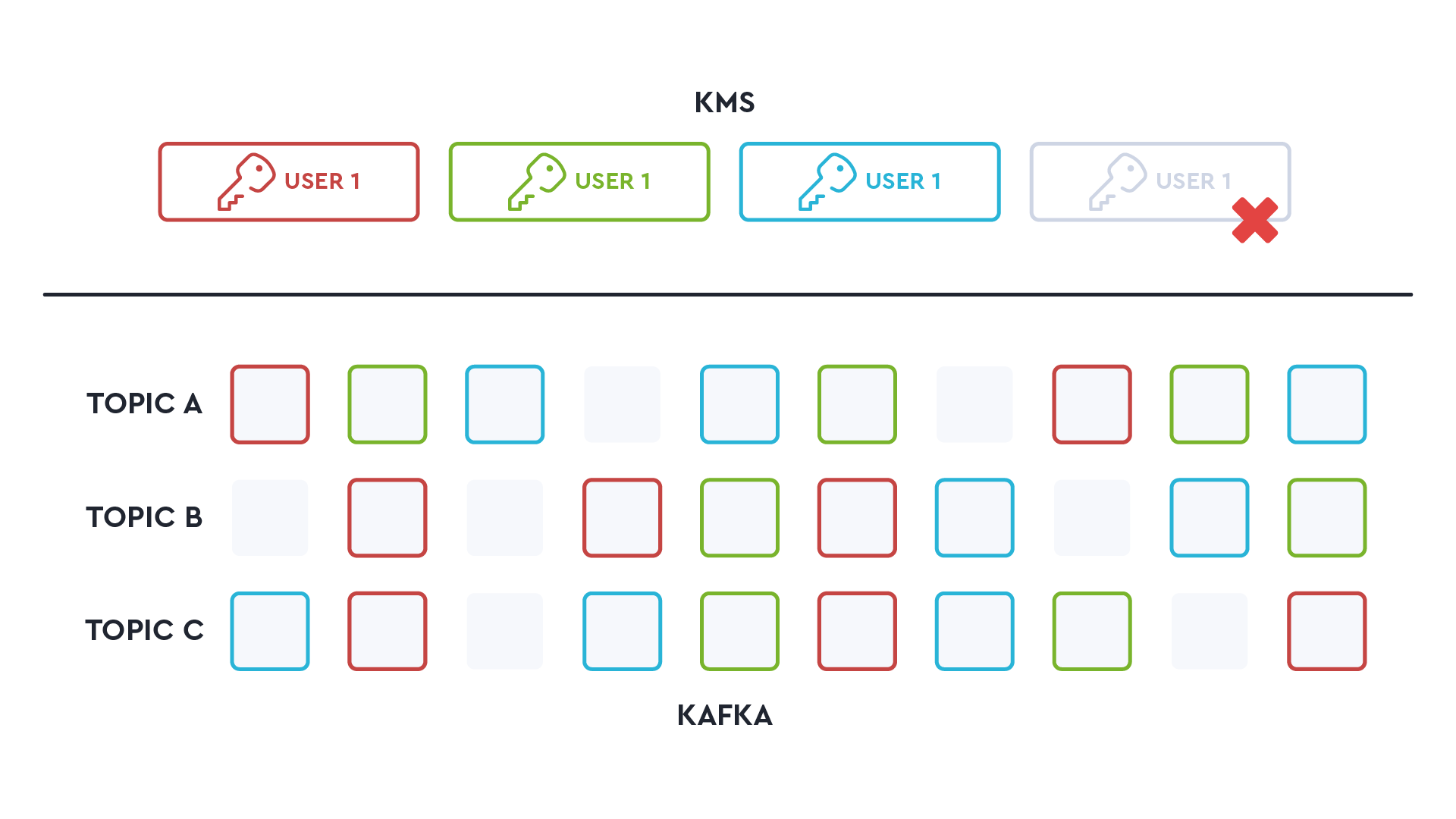
If ‘limited to what is necessary’ means deleting a user’s data entirely, you may need to crypto-shred them. Crypto-shredding is a technique that associates a unique encryption key with each customer and their data in Kafka. If a customer invokes their right to be forgotten, their unique key can be deleted.
Although on paper this sounds fine, it’s rarely suitable:
1. It has to be 100% secure. Even if you "delete" a key, how can you ensure there isn’t a copy of the key?
2. Securing the keys has to be balanced with offering a good developer experience.
3. How would you compensate for the degradation of performance for every read/write operation and the implementation cost?

Accuracy means making sure customer data being processed is recent and relevant.
For example, imagine a customer has given permission for your team to process their data and send promotions for a coffee only when they are inside a Starbucks. ‘Accuracy’ means being able to process data on these terms so they receive their offer at the right time.
Kafka builds a good case for data accuracy because the essence and value of event streaming is in the freshness of data.
If a customer asks for a copy of their data, you should be able to repurpose and translate it into a format they can access.
This may mean exporting data serialized in a Kafka topic, maybe in protobuf or AVRO into a CSV file so it could be presented in court. Lenses is a perfect fit in this scenario, showing data in a visual format like so:
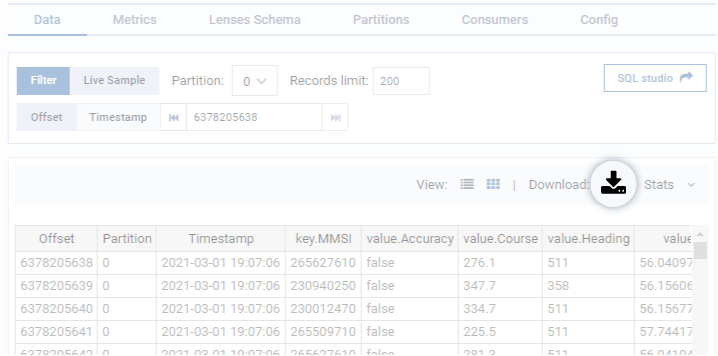
It’s also useful showing it in a UI like this if your Legal team just need to see the data themselves.

Storage limitation is about keeping personal data for the shortest amount of time necessary, whilst respecting local laws (such as anti-fraud) and adhering to any national or scientific interest.
We touched on data retention briefly and what it means in relation to ‘purpose limitation’ of data in Kafka. But beyond a technical challenge, data retention policies are about educating your organization on what Kafka is - and what it isn’t - in the context of your company.
A big part of retaining data for the right time period is in managing the expectations of those building streaming apps, by making it clear that data won’t last. Anyone interfacing with data in Kafka should be required to set and manage their own retention period, so they don’t treat Kafka as the database it isn’t.
For example, data stored for any longer than, say, two weeks, can be moved from Kafka to S3 or HDFS to rest. The Kafka to S3 connector will allow you to sink data to an S3 bucket whilst partitioning into different files by fields within the payload (such as customer_id).
Product teams with knowledge of their own business context and legal requirements should be able to set their own topic retention rules, decentralizing responsibility from the platform team. This can be done in a self-service manner as shown in the screenshot.
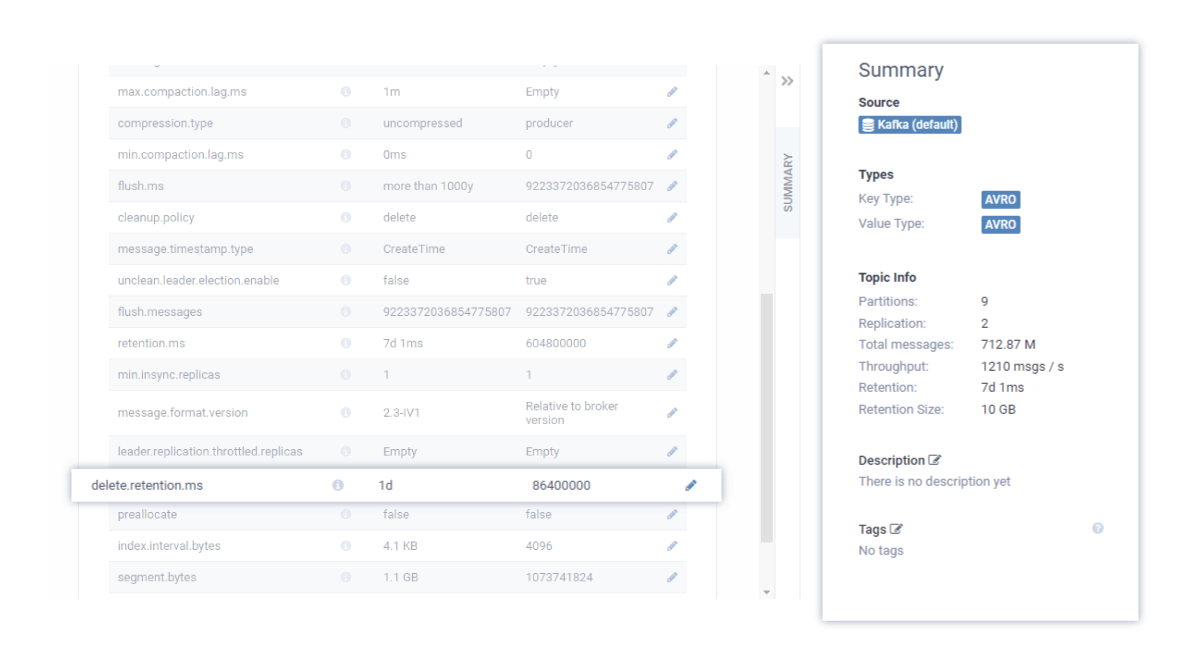
Teams should be able to query metadata timestamps in Kafka topics to do spot-audits that retention policies are being respected.

GDPR says that in the event of a breach, you need to notify data subjects and the authorities within 72 hours.
You should plan & rehearse incident response procedures with your security operations to detect and isolate breaches as quickly as possible.
As part of your procedure & documentation, the impact of the breach should quickly be determined and contained. If Kafka has been exposed, you’ll need quick access to the following:
Audit logs (infrastructure, application & data operations)
Size of the data sets implicated (i.e. number of records in the topics)
Impact level of the data breached (as categorized)
Individual customers implicated in order to provide notifications
Asset information related to the Kafka environment (hosts, packages installed etc.)
Other logs for forensics
Again the problem boils down to the fact that visibility into Kafka data is challenging and time-consuming. The data may be serialized, large, difficult to search, understand and analyze. This is why data observability & data cataloguing are so important.
And there’s the fact that with a standard Kafka setup, any user or application can write any messages to any topic, as well as read data from any topics.
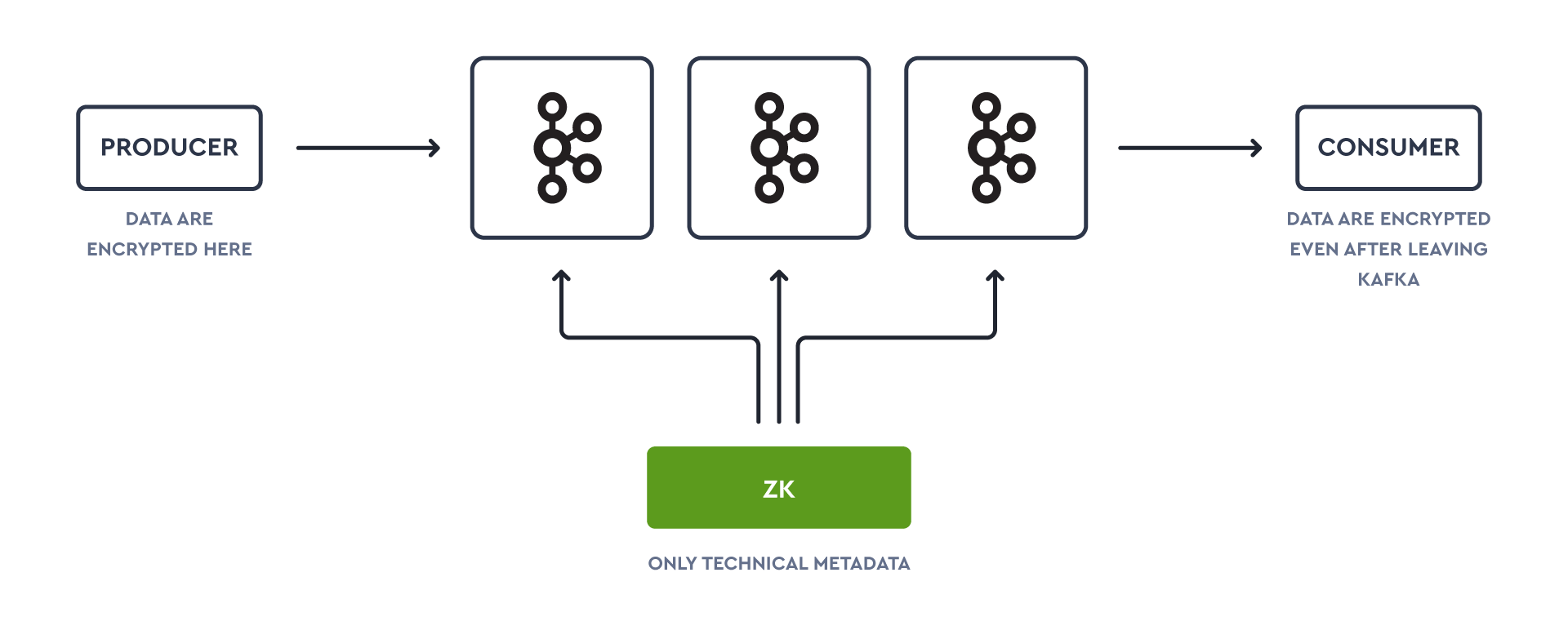
Encryption will help reduce risk of the integrity and confidentiality of data being compromised. We should look at the data in three different states:
Data-in-transit: Protects the data if the communication lines are intercepted whilst data moves between client and Kafka and Kafka to Kafka. Endpoints here should also be authenticated. This is of course the bare minimum of a zero-trust security policy. Use of sidecars with your applications can be a good option to simplify the security operation tasks and ensure good developer experience in how keys are rotated.
Data-at-rest: protects data from the system (access or theft of hard drive etc.) itself being compromised. This can be either encrypted by the hardware or by the application. It’s common for many managed Kafka providers such as AWS MSK, Aiven and Confluent Cloud to now offer this as standard.
Data-in-use: Protects data on memory within the application in case the application or system itself is compromised before it hits the disk. Discussing this is beyond the realms of Kafka or the scope of this guide.
Kafka Audit Logs - Collect all your Kafka system & data operations (such as creating topic, evolve schema, deploy connector) audit logs and integrate them with your SIEM such as Splunk for real-time security monitoring and incident response.
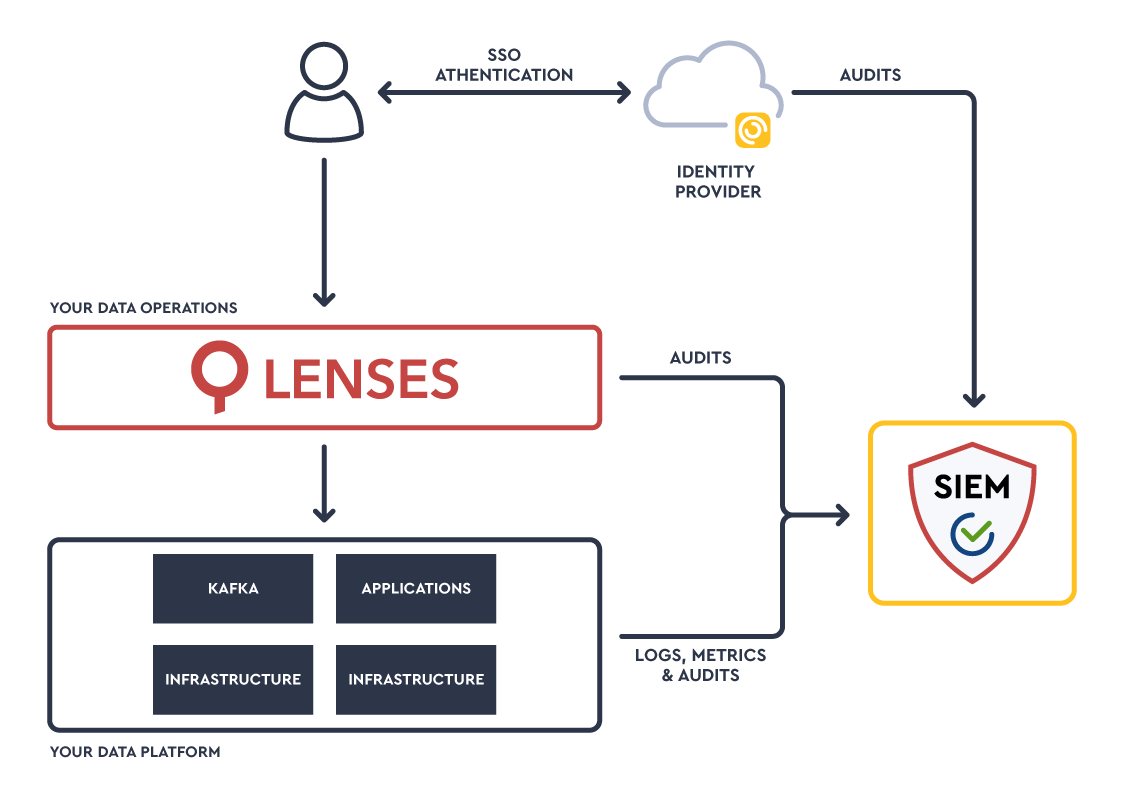
Place identity & access management - Connect your users to your single identity provider (SSO) and segregate users & apply appropriate data access and data operation privileges. As Franz Kafka once said: “It’s often safer to be in chains than to be free”.
Not only is it safer, it speeds up time to market.
The accountability principle requires each individual within the organization to take responsibility for what you do with personal data and how you comply with the other principles.
Good governance and data protection policies are more than a set of legal requirements. They are a culture, an education programme, a set of beliefs, values and actions.
There is a common misconception that compliance measures slow down teams. In fact, operationalizing streaming data will accelerate the delivery and quality of data products.
If you look into previous court cases related to GDPR, those that comply are often not those that follow every rule to the letter, but those who practice and cultivate a spirit of good governance.
Special thanks to: Dario Carnelli, Guillaume Aymé, Ivan Majnarić, Vladimiro Borsi, Antonios Chalkiopoulos, Adamos Loizou
Reasons and challenges for Kafka replication between clusters, includi...
Andrew Stevenson





