

May 2018.
I remember it like it was yesterday.
I spent endless hours clearing my inbox (trying to maintain inbox zero). An inbox bursting with emails talking about GDPR, the European Union’s comprehensive data privacy regulation regime that was set to come into effect that month.
All the while rushing to ensure our own marketing practices were compliant and heeding reminders from our data protection officer about the hefty fines companies could face if they didn’t get their act together.
Over the last few years, we’ve continued to see a rise in the amount of data businesses are collecting on customers.
It goes way beyond the simple stuff like name and email address. Many now store more personally identifiable data such as your address, date of birth and not to mention your financial information like credit card details.
And with more and more businesses moving towards building real-time applications and microservices (using technologies like Apache Kafka) with user data, data compliance has never been more important.
As we approach its 2 year anniversary and with the average cost of a data breach now over 3 million dollars, I wonder... how can we stay on the right side of GDPR in this new world of real-time data? 🤔

Keep it catalogued
As you collect increased data on your users it becomes more important to know which databases hold Personally Identifiable Information (PII) and who is processing it.
Understandably, as your data operations become more real-time with the development of microservices this becomes more difficult. But, to stand a chance of complying you need a catalog of what data you hold and where it’s located.
And let’s be honest, we all fall victim to data hoarding - in some cases hoarding up to 5 times more than we need. Think about all the storage and database license costs saved by having a catalog that highlighted data redundancies and eliminated them 💸
Mask that data!
Data masking (aka data obfuscation) is one process enterprises are quickly adopting.
Data masking in simple terms is hiding data. This is typically done by obscuring the real data with random characters - covering sensitive and classified data from those who don’t have permission to view it. 👀
But how can we do this with real-time data you’re probably thinking. Dynamic Data Masking (DDM).

In simpler times it might have been only a few dozen colleagues needing access to certain types of data but with organisations opening up their data infrastructure to more and more departments it’s likely to be in the hundreds (if not thousands) needing access to data. With the use of automation and Data Policies, DDM changes the stream of data so the user, application, microservice or your grandma doesn’t get access to that sensitive data. 👵
Leave breadcrumbs️
Thanks to tools and technologies (like Lenses 😉) keeping an audit trail of all system, application and user actions has never been easier...and more vital in ensuring GDPR compliance.
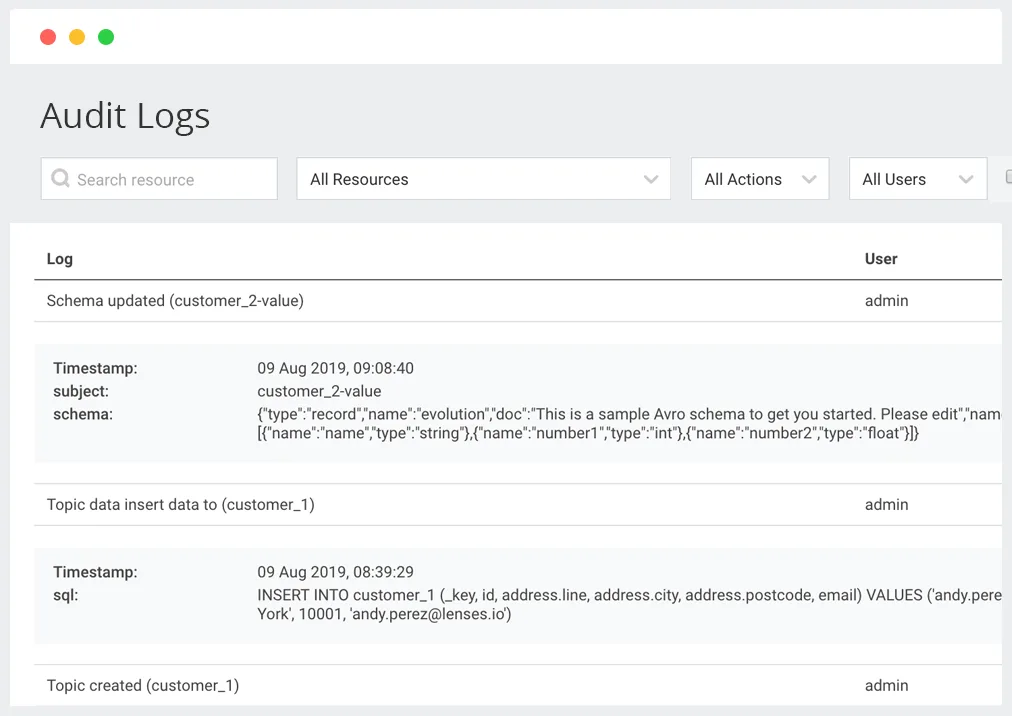
Audit trails maintain a record of activity by logging a series of events about your platform, applications and even users’ activities. Ensuring that system resources have not been harmed by technical problems that may arise, hackers or disgruntled employees.
Psst! Don’t forget that in the event of a data breach you’ve got 72 hours to notify customers and the relevant authorities. An audit trail will then be useful in providing an up-to-date record of who has accessed what information, when it was accessed and how it was handled.
With the 3 simple practices above, you can keep your DataOps on the right side of GDPR and stay compliant.
For more reading on this check out our CEO Antonios’ piece on Apache Kafka and GDPR Compliance





