By
Apr 14, 2021Yiannis Glampedakis

Yiannis Glampedakis
As a developer, you're no stranger to your vast and varied data environment… Or are you?
The tremendous amount of data your organization collects is stored in various sources and formats. You need a way to understand where and what data is, to be able to do what you need to do: build amazing event-driven applications.
Lenses adds a wider perspective to your Kafka topics with data observability. Developers get a catalog of data entities across technologies core to microservice-based architectures, such as Elasticsearch and PostgreSQL, with new metadata management functionality to make it work.
The main goal in the short-term is to enhance the developer experience and extend your field of vision so you can focus on building your core applications. But the longer term goal is far bigger and will be a big part of DataOps in the future: Use metadata to drive automation in data management & governance.
Let’s start with now.
If you were on day one of an engineering job and needed to build an event-driven application, could you be immediately productive? Would you be able to find and understand what data you could use?
We’ve really gone for the Space metaphor. So if you’re buying into that, you, the developer, are flying your data product across the streaming event-strewn galaxy. You’re surrounded by several-hundred billion stars, moons, asteroids, comets - data that helps navigate and fulfil your mission.
Impressive, but overwhelming.
In this article we’ll see how Lenses metadata management is enabling different data operations use cases. We’ll share examples of metadata that we’ve found most useful when it comes to Kafka and its orbiting open-source DBs.
Metadata is often simply described as the data about data. When operating data moving in and around Kafka, it’s important to have a metadata strategy that...
Answers questions about datasets or data itself
Helps you understand the data’s behavior
Details what to expect from the data
Shows how the data is used by people and apps
Measures the data’s quality or performance
Tells you how timely or fresh the data is
Besides the directly measurable upside of metadata, there are also the day-to-day collaboration benefits with your fellow pilots:
Standardized tagging nomenclature provides an abstraction that everyone can understand
Avoid duplicating data that already exists
Governance of your data platform grows more scalable
Your data lives in potentially thousands of data sources: operational repositories like Elastic, Postgres and more.
This data moves around and beyond your organization in the form of streams via Kafka, and may eventually come to rest in a warehouse (Amazon S3, Snowflake) or be surfaced immediately in an event-driven consumer-facing app.
As more teams turn to building applications off a Kafka event stream, the level of data proliferation increases and engineering productivity drops. It becomes impossible to see, let alone understand, what data is out there.
That’s why last year we built the first data catalog for Kafka, automatically discovering data entities and giving developers the ability to understand relationships between applications and datasets.
Let’s look at the most helpful kinds of metadata and what they’re used for.
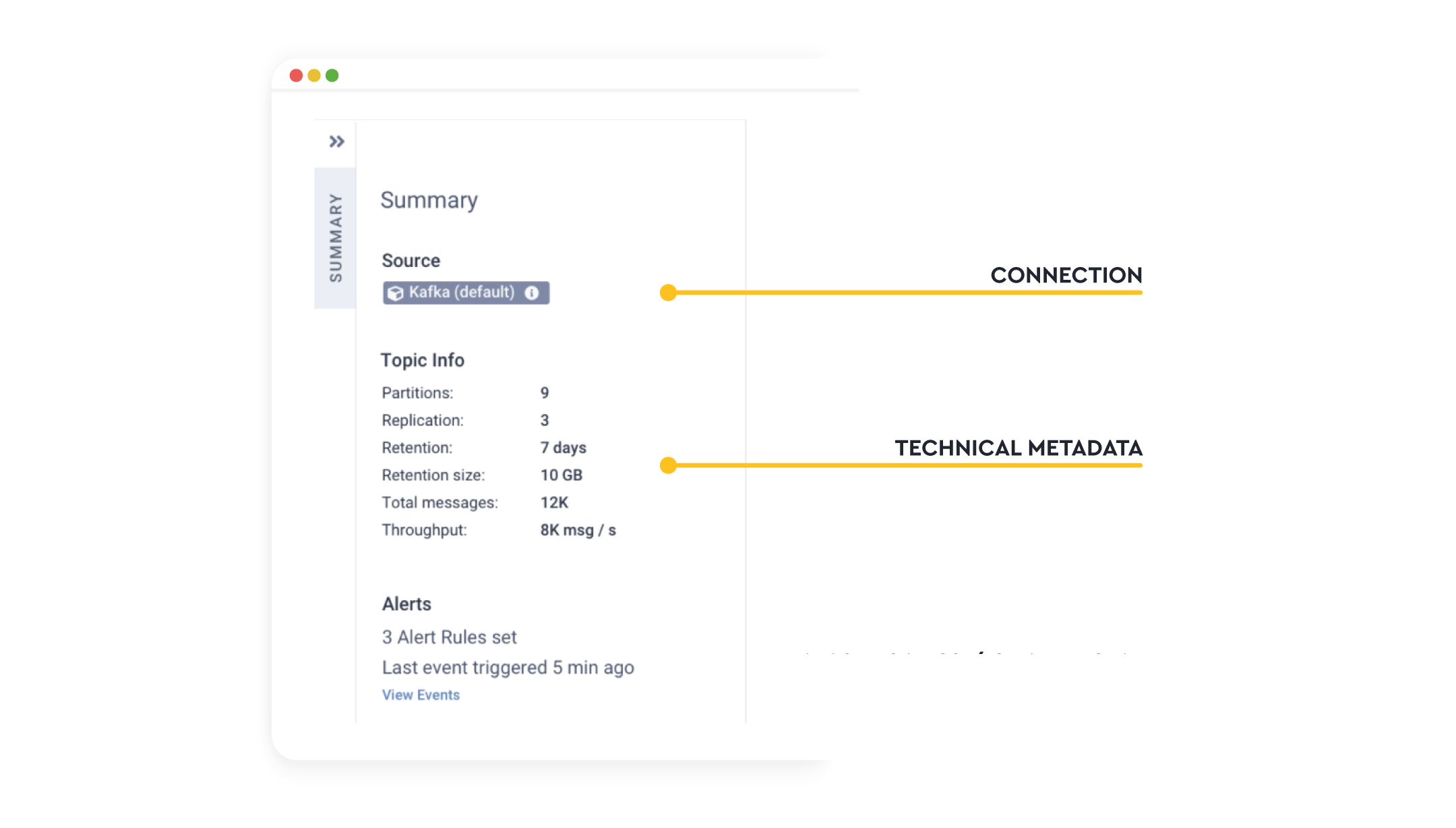
Technical metadata provides information on the shape of the data, how much of it there is, how it’s being stored and where it’s being sourced from.
This data can be intelligently discovered automatically. This avoids having to have manual processes to document data sources in data dictionaries, Excel sheets or Confluence. Information that soon becomes out of date and causes people to lose trust in it.
For this type of data, the most basic information you need is the information about the data schema itself: fields in the data, field data types, primary keys etc. This can be taken from the database if it’s stored at rest, via schema registries for application-to-application flows. Or potentially by introspecting the payload of the data in the case of formats such as JSON, CSV or XML.
Other technical data would include information such as:
State: Such as configuration
Serialization: The serialization format of the data
Partitioning/Sharding: Helps on how to best consume the data
App relationships: Which applications are processing this data?
Metrics: What is the data availability or quality?
This helps someone make a decision on how and when data can be used. This is by understanding what it represents, who’s currently using it and how much it can be trusted.

Tags: What ‘type’ of data is it? What line of business does it belong to?
Associated Service: What business service depends on this data?
Description: What is it used for?
SLAs: What service-level is associated with this data?
Sensitive information: What compliance requirements and impact level does this data have?
Quality: How much can this data be trusted and for what use cases?
Information about how the data is being accessed, by whom and its lifecycle:
Usage: Who has access to it? Is it available to a specific user or group of users?
Resources: Associated Quotas, ACLs, etc.
Again, impressive to categorize your datasets in this way, but metadata is only useful when you can act on it and address use cases.
Adding Tags and Descriptions directly to your topics is a simple yet powerful Lenses feature. Tags could include anything from the version of the application producing to Kafka, to the name of the data owner. This helps different engineering teams collaborate better: When faced with 100s of different Kafka topics for example, it’s great to be able to search and filter based on tags.
Tagging Kafka topics or data entities with a tenant, team name or data source allows you to measure the rate of adoption of your data platform - who’s using it, what data sources are being processed on it, and potentially how you should cross-charge.
Tagging may include specific compliance and regulation that needs to be met based on the data within the data entity. Tagging “PII” or “GDPR” or “HIPAA”. This can then be used to export the list of all datasets as part of a compliance audit.
Above were just some use cases designed to help make engineering more efficient. Our next goal however is to use metadata to drive automation. A few example use cases being:
When tagged with a high service level, a data source is routed automatically through a quality check pipeline
With a data entity classified as PII, pseudo anonymization rules are automatically applied
User data access controls are applied dynamically based on metadata
Tagged with “archive” a data integration pipeline is automatically deployed to archive all data into an S3 bucket.
We’re also working on providing metadata management to streaming applications & pipelines and not just data entities.
This will allow us to offer a personalized view to an engineer of their world: their lens into both application and data landscapes.
Stay tuned.
The rise of hyperconnected data products....
Guillaume Aymé
Dec 20, 2024
How to write Protobuf-based Kafka producer & consumer microservices wi...
Eleftherios Davros
Mar 01, 2022





