By
Mar 30, 2021Yiannis Glampedakis

Yiannis Glampedakis
When you’re one of many developers commanding streaming applications running in Apache Kafka, you want enough data observability to fly your own data product to the moon. But you also want to boldly go where no developer has gone before to discover new applications.
At the same time, you don’t want to be exposed to sensitive data that summons you to your compliance team, crashing you back down to earth.
With this delicate balance, you can stay in the innovation race by seeing beyond your flight path, but also limit data in all the right places… to avoid crashing your ship.
This is the theme of our latest release of Lenses (4.2): mightier metadata management to create a safer, more productive developer experience when building real-time applications. With some bonus features added in for good measure.
Here’s a quick breakdown of the Lenses 4.2 highlights.
PostgreSQL has been an often-requested relational database that now joins the growing Lenses dataverse. We’re focusing on technologies within a similar orbit to Kafka - first Elasticsearch, now PostgreSQL, a common state-store for event-driven and microservice-based applications.
This allows you to explore data across Kafka, Elastic and Postgres with SQL in a seamless way. You can do away with having to manage access controls across multiple tools often with over-generalized ACLs. Instead, you have a unified, fine-grained security model protected with namespaces.
You can also mask PostgreSQL data in the same way you can mask data in Kafka using Lenses data policies.
With PostgreSQL, we hope to widen your toolkit to support the most popular use cases such as Change Data Capture (CDC), breaking up monoliths or just building cloud-native event-streaming applications.
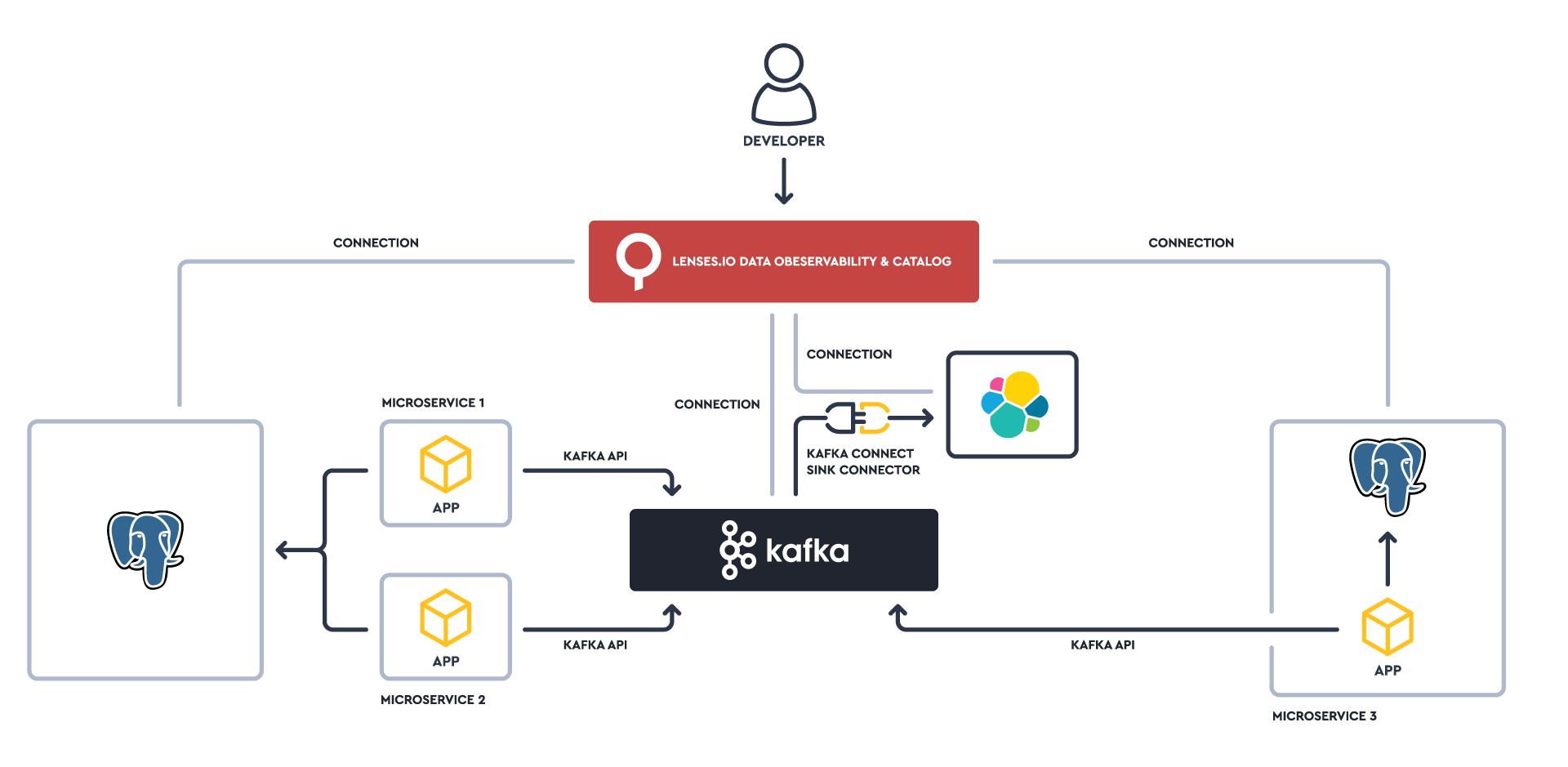
Our last major release brought you the industry’s first real-time data catalog for Kafka. It works like Google Search over your galaxy of streaming data, discovering metadata in real-time and their relationships with your streaming applications.
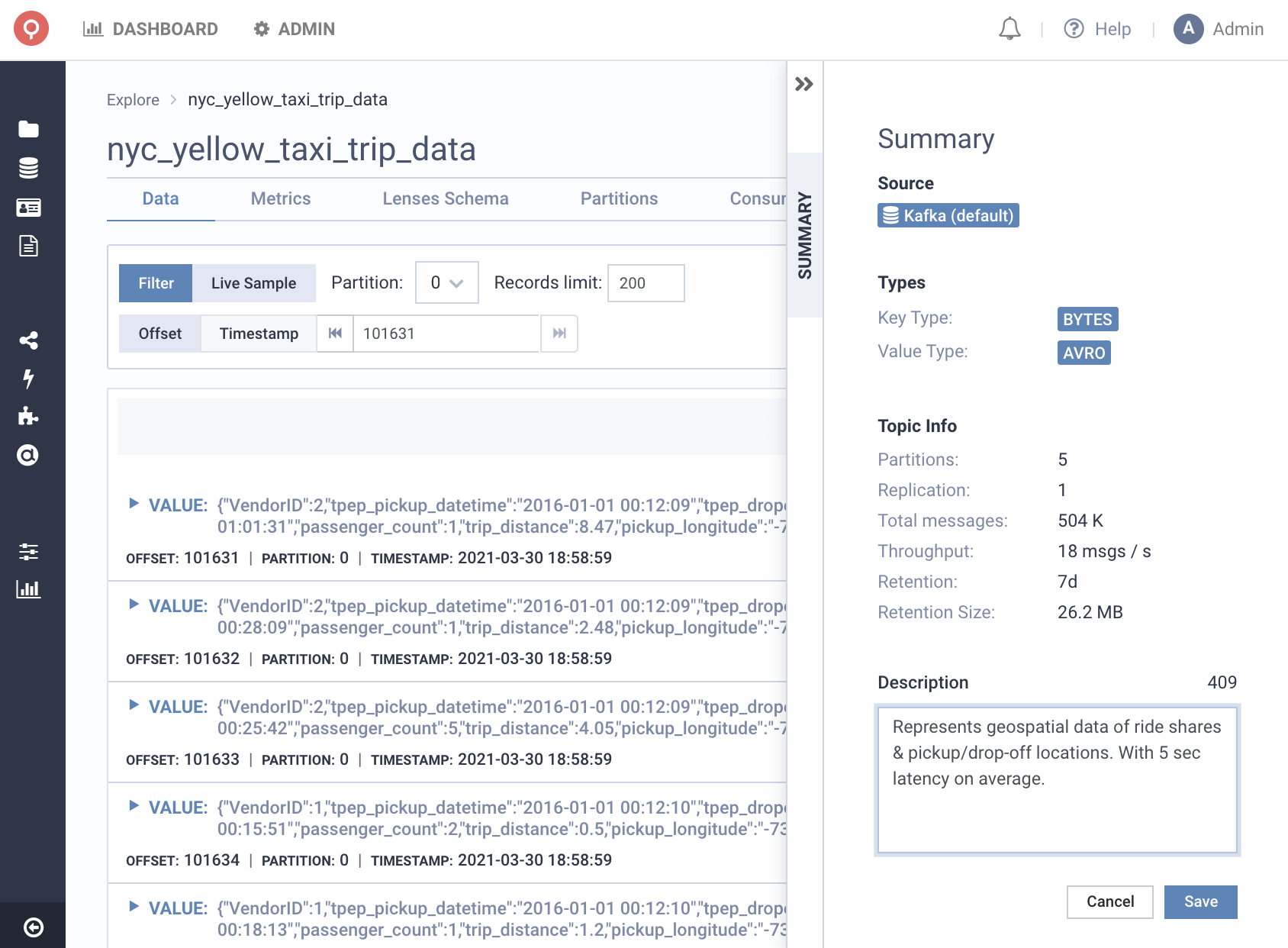
So as well as enriching our data catalog with PostgreSQL data, we’ve also revamped the experience for managing and exploring the metadata for increased productivity.
Augment metadata with business context by adding tags & descriptions to Kafka topics, Elasticsearch indexes and Postgres tables. Bring business and technical context closer together - like SLAs, regulatory requirements, data quality.
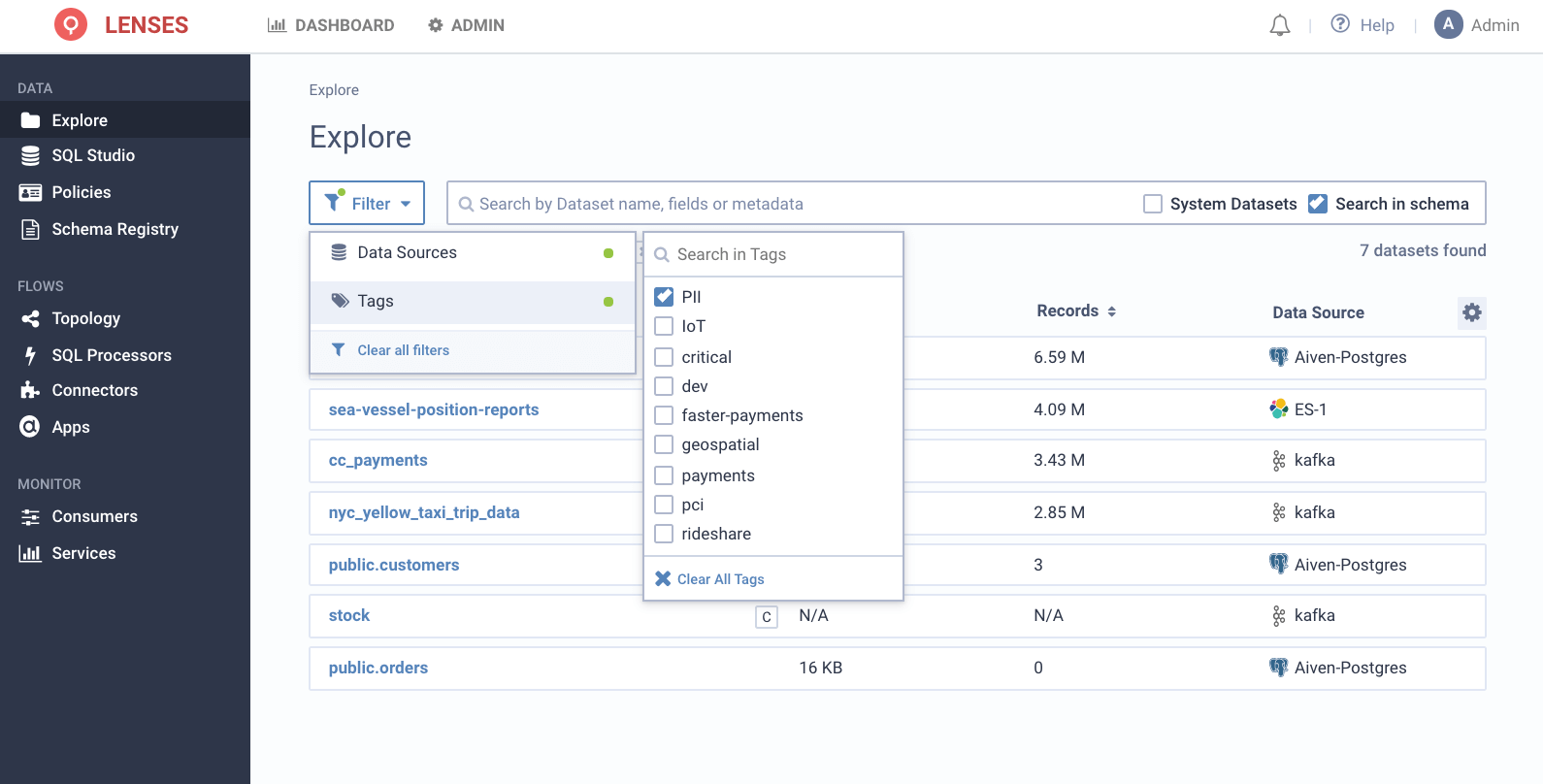
Use technical & augmented metadata to better navigate, filter and act on your data. Your fellow developers can benefit, especially in a multi-tenant environment, by being able to see what’s relevant and declutter your data field of vision.
No one except your adversaries enjoys lack of user identity & access management for Kafka. The poor Kafka admin having to reset passwords and decommission accounts doesn’t enjoy it. The frustrated developer who’s playing the longest rally of Slack ping pong ever to request access. Nor the security & compliance teams who are breaking into a cold sweat with the rocketing risk-levels of your streaming data platform.
We’ve now added Google SSO to our list of supported Identity Providers (Okta, One Login, Keycloak, etc).
That’s the highlights reel for this release.
So put on your extravehicular mobility unit (i.e. spacesuit), and enjoy your take-off.
Head to the full 4.2 release notes and check back for further deep-dives on these capabilities in the coming weeks.





