Geospatial data processing with streaming SQL for Apache Kafka
How to do geospatial processing of data in Apache Kafka.

By Guillaume Aymé
Dec 18, 2020
An old airport customer of mine (whilst I worked for another company) used to pop someone next to a busy runway with a stopwatch strapped round their neck. The unfortunate person had to manually log the time aircrafts spent on the runway to measure the runway occupancy.
All very archaic. Even in those days.
The problem was solved by using a Point-in-Polygon (PIP) algorithm, taking data from their A-SMGCS System (Advanced Surface Movement Guidance and Control System) - basically the radar in the control tower to see if the coordinates on a plane intercept a defined polygon (such as of the runways) represented an array of coordinates. This was then visualized in dashboards.
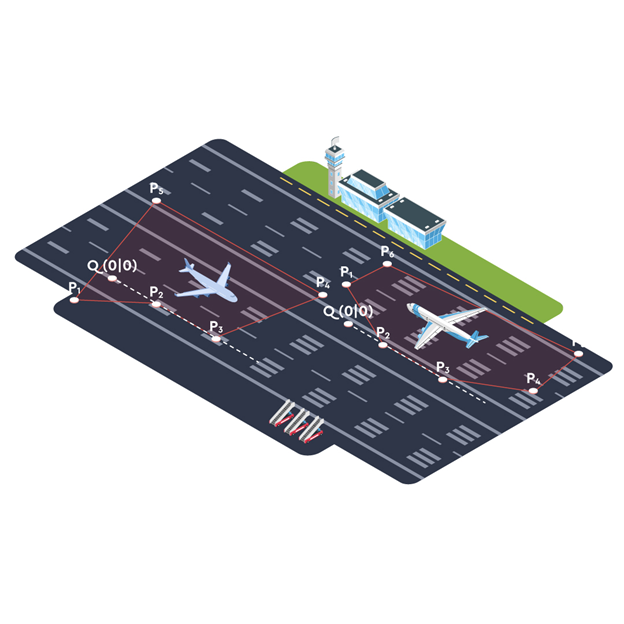
Not only did that person not have to suffer in the British rain, but the same practice allowed us to answer thousands more questions than originally scoped. This included checking whether they were in compliance with the time gap between aircrafts as they landed, and detecting pilots-behaving-badly by missing the correct runway exit in order to get to the parking gate quicker.
I documented it at the time here.
The process wasn’t really scalable though. From a compute perspective (each report had to do huge computation on-the-fly with Splunk) as well as from an accessibility perspective (i.e. how could this data processing be made available to engineering teams and with a good developer experience?)
With the explosion in connected and IoT devices, there’s almost no organization today that doesn’t need to optimize business operating models or deliver real-time consumer applications with geospatial data.
Many are adopting Apache Kafka to connect their applications; often in which location-based data is sitting there waiting to be stream-processed.
As with the airport use case, doing this sort of data analysis is easy on paper. But the challenge is how it can be applied at scale, without having to manage complex pipelines and where it can be brought to production with software governance and assurance.
The Lenses SQL Engine for Apache Kafka has helped data engineers do on-the-fly data analysis and data-processing on Apache Kafka streams.
It abstracts many of the complexities of stream processing. It will automatically run your workload on your existing infrastructure (such as Kubernetes) as well as integrating into your CI/CD practices. It then provides the monitoring, alerting and ability to troubleshoot the applications as they run in production.
Of course, defining a PIP algorithm in SQL would be impossible you might assume.
Implementing a Java interface, we can easily build a UDF to extend the Lenses SQL. This can apply the PIP algorithm to detect if the coordinates of a given event intersects with a polygon.
For this particular use case, I’ve built a UDF that takes three arguments. A latitude and longitude value as well as a JSON Array that defines the polygon that we wish to map to.
The JSON Array includes a key as a label and then an array of lat/long tuples. Such as this.

Overall, a query may look like this:
The function works both in Snapshot mode and Streaming SQL mode for continuous stream processing to be served into another Kafka topic.
The algorithm is based on a nice research piece “Determining if a point lies on the interior of a polygon” published here.
You can read the full section if you’re that way inclined but if we had to summarize it in a tweet I would write:
"Imagine if our point (the lat/long) has a line drawn to its right across the polygon. The number of times this line crosses an edge of the polygon determines if it’s inside out. If it’s an even number, it means the point is outside the polygon, if an odd number, it’s inside the polygon."
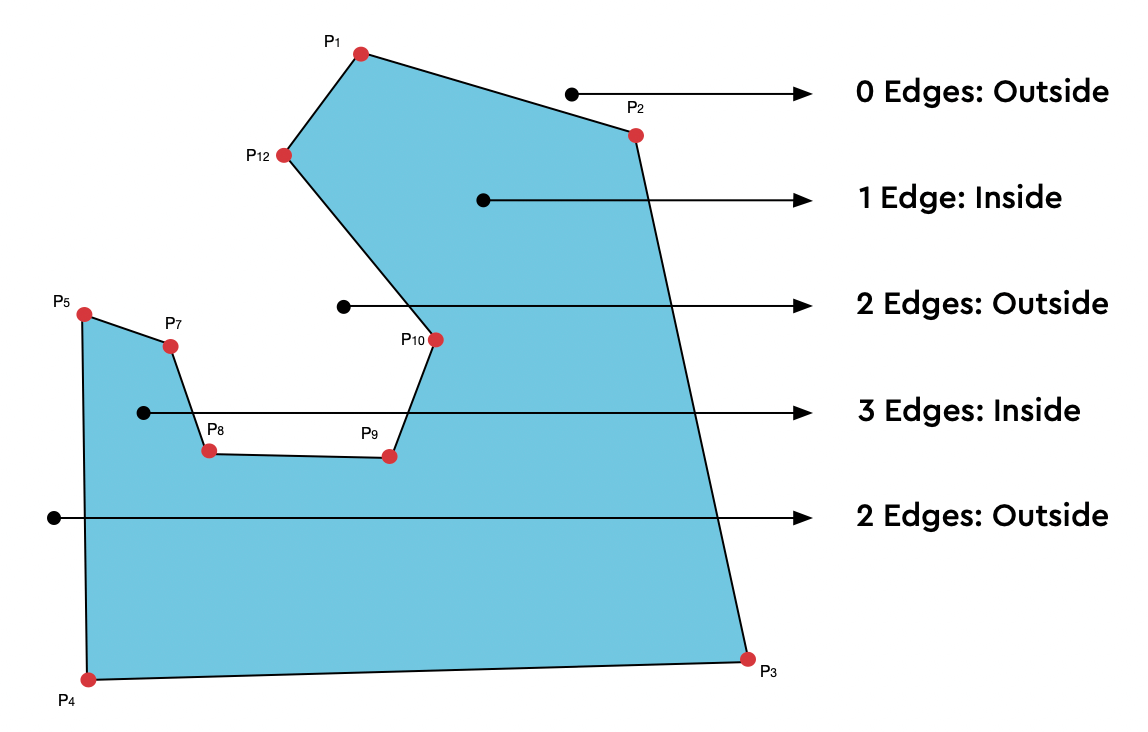
The algorithm is translated to this in Java:
The use of UDFs in SQL in an easy-to-use framework can become a game-changer to an organization.
UDFs can be defined to represent composable parts of your business (“composable business” increasingly a trend) that can be used and shared by different teams across your organisation. Allowing you to define business logic with SQL.
For this geo-spatial processing use case, this means processing location data generated by the different devices, applying some business context by geo-mapping it and then making it available to downstream applications across the business. This may be to automate business operations or to deliver the data in a consumer-facing application for example.
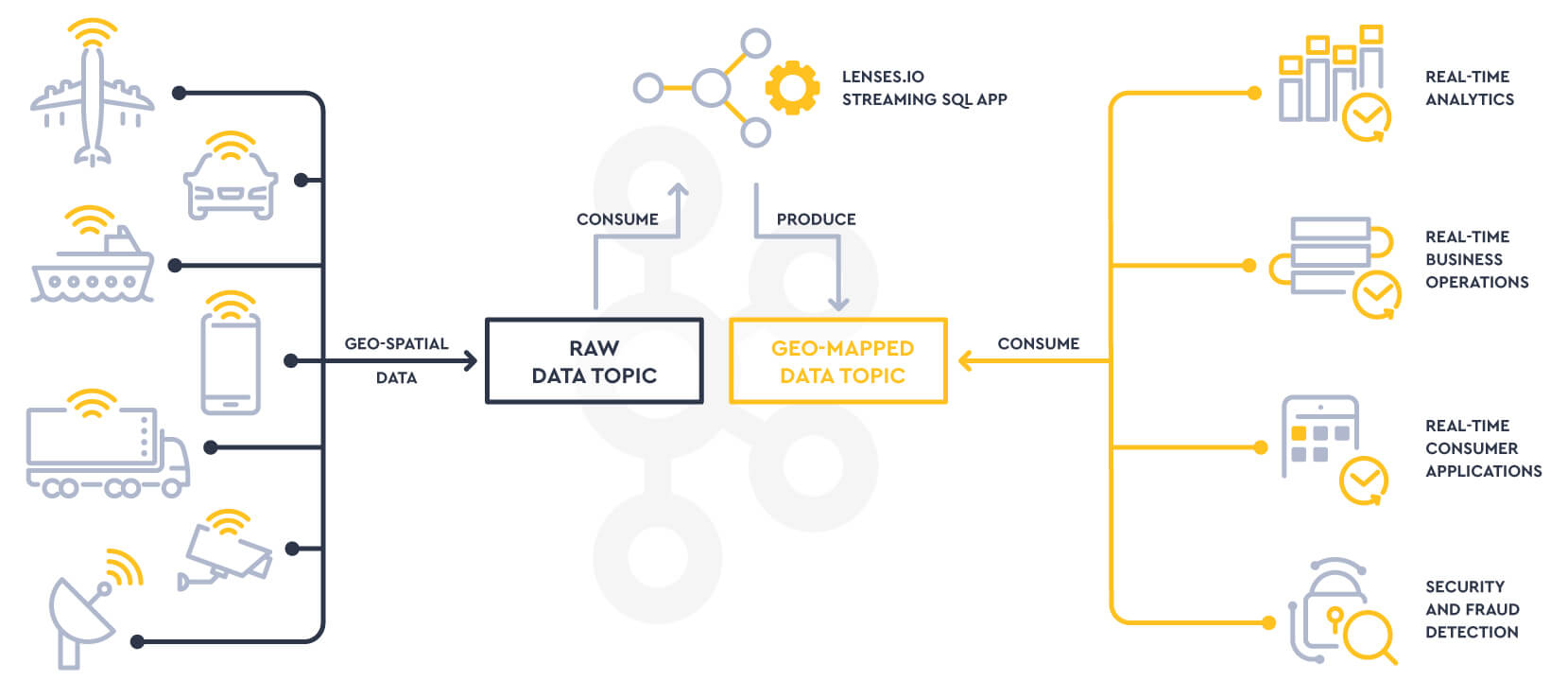
The possibilities are endless.
This UDF is not polished but ready to be road-tested to demonstrate the concept.
This can either be in your own Lenses and Kafka environment or you can use the free Lenses+Kafka “all-in-one” docker.
1. Clone the project from https://github.com/themastergui/udf_spatialmap
2. Get your Box docker command and license key from lenses.io/box. Or alternatively request a Trial to use Lenses against your own Kafka.
3. Run the Box docker.
When you run it, you’ll need to mount the following 3 jar files from the project to the /opt/lenses/plugins/udf/ directory of the container.
json-20201115.jar
lensesio-lemastergui-udf-spatialmap-1.2.0.jar
lenses-sql-udf-4.0.0.jar
Example command:
Ensure you have at least 4GB RAM and ports 9092 and 3030 are available.
3. Access the Lenses UI from http://<host>:3030. The environment can take a few minutes to be fully available.
4. Create a “coordinates” topic. You can either do this from the “Explore” menu (ensure you set the key/value serialization to String/JSON) from the ACTIONS menu. Alternatively, from the SQL Studio, run the statement:
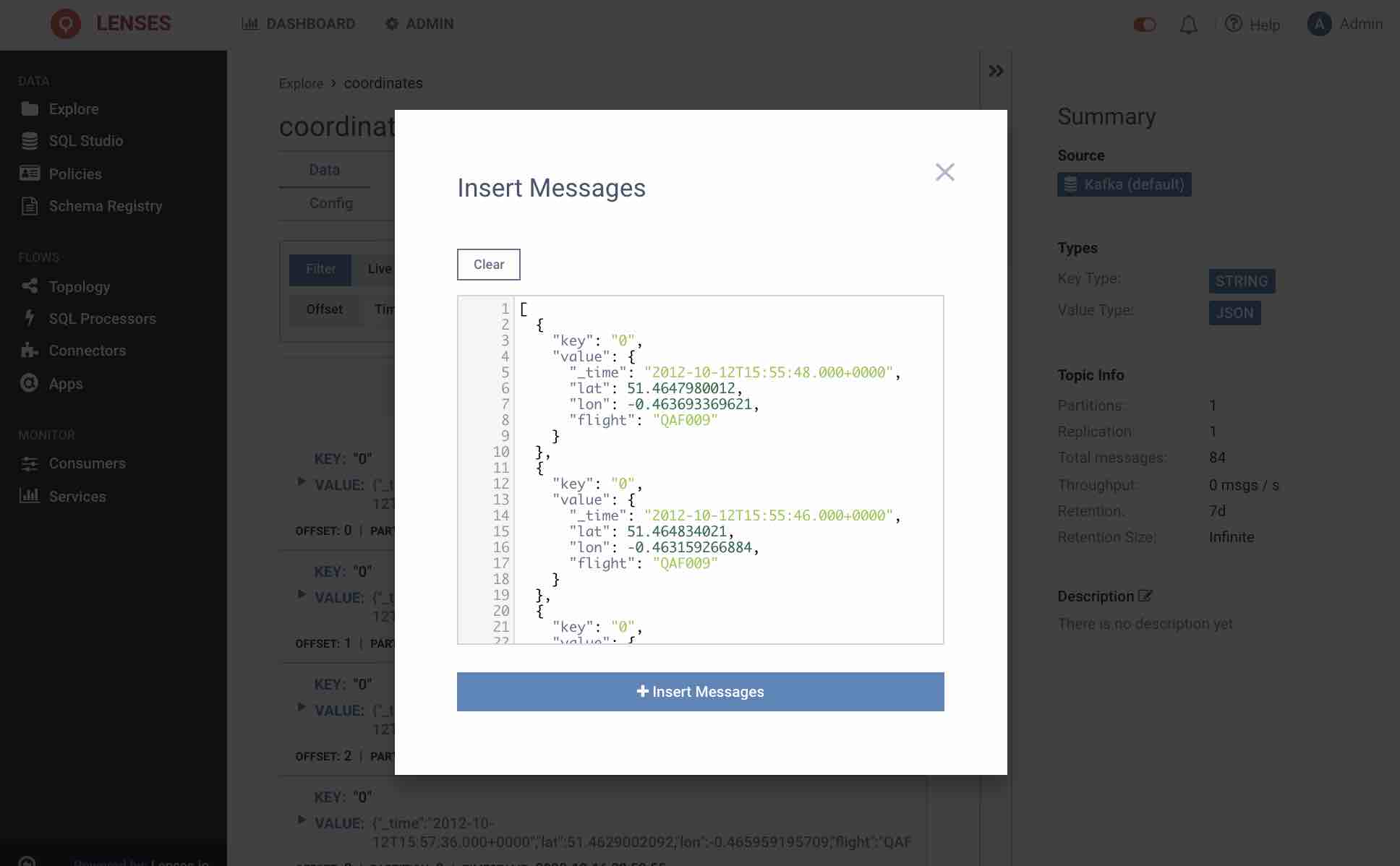
5. From the Explore menu, find the coordinates and from the ACTION menu, select Insert Messages.
The following JSON is some sample data of a flight landing at an airport:
6. Back in the SQL Studio, run the SQL Statement with the UDF function
From the results set, it will return true if the point intercepts with the polygon and false if it doesn’t.
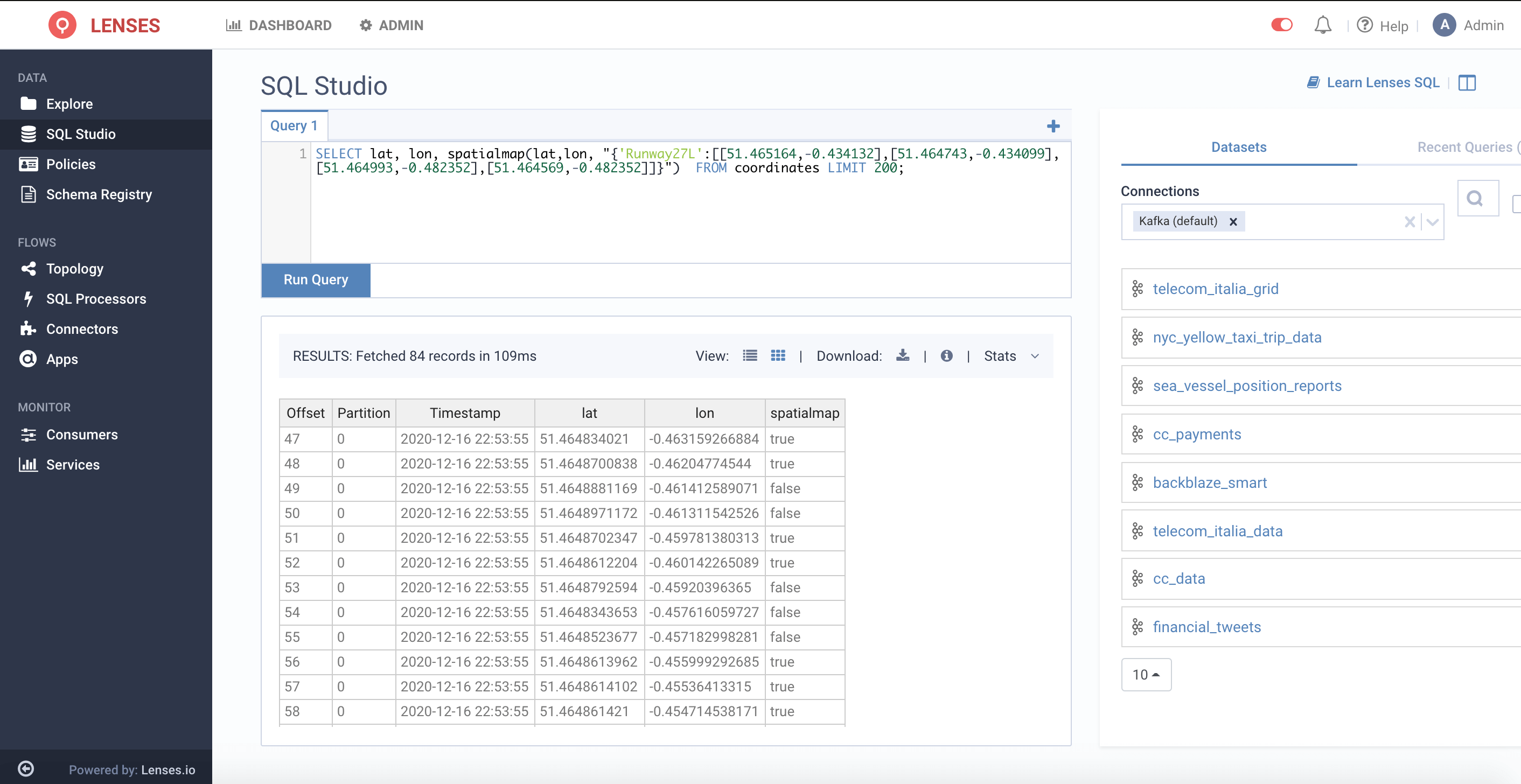
How fantastic is that?
What we’ve just shown is querying data in a Kafka topic in a “Snapshot” mode.
There is also the possibility to run the workload continuously as a stream and publish the output to an output topic. This makes the data ready to be consumed by another application.
1. From SQL Processors section, create a new processor
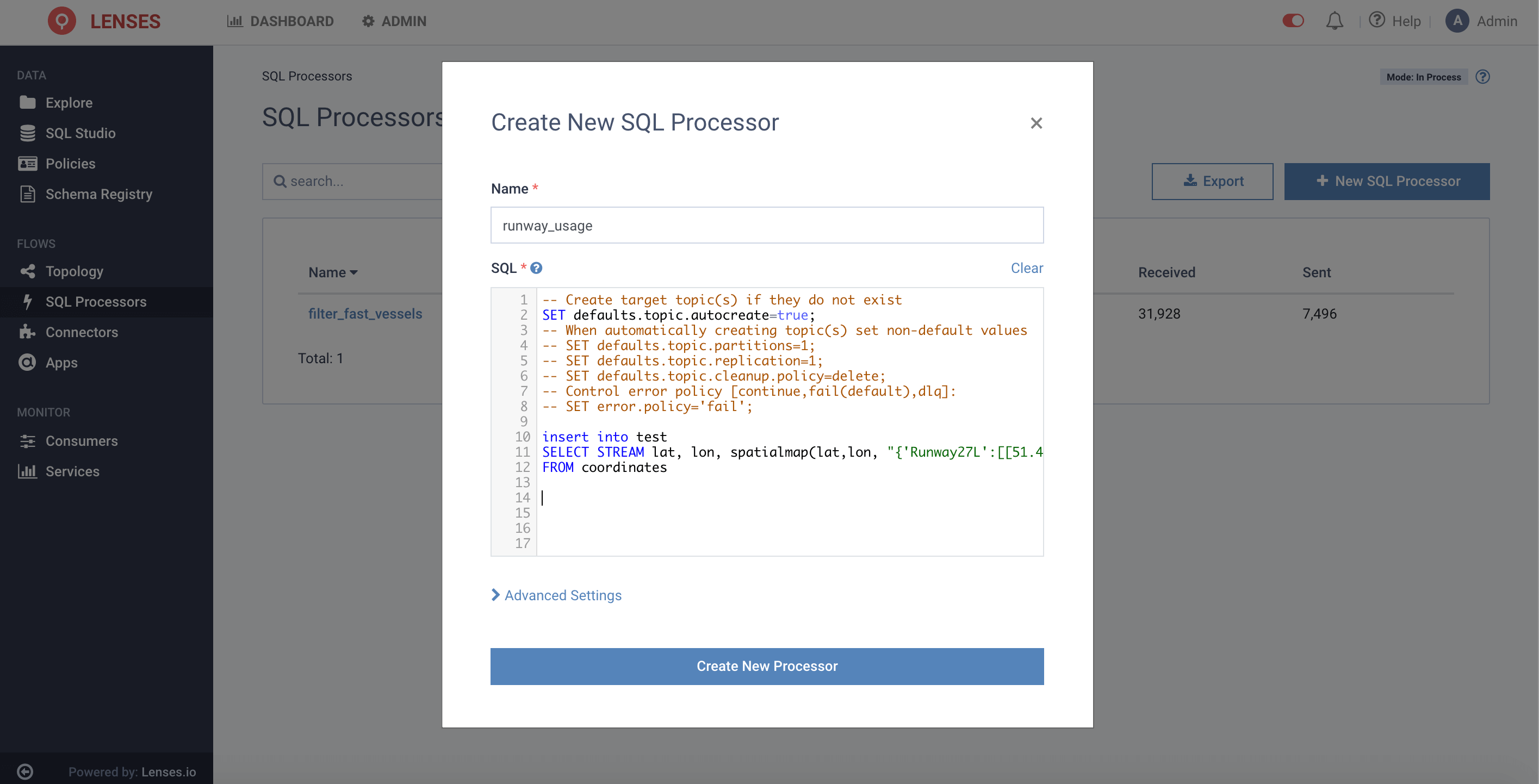
2. Give it a name and create it. If you’re running the Lenses Box, it will run the workload locally. In a real environment, it would be deployed over Kubernetes or Kafka Connect.
3. Return back to Explore view and find the runwayoccupancy topic. Ensure you see a stream of output data from our query.
Let us know about your stream-processing use cases to see how SQL can simplify your life of getting to production. Share your comments to us directly on social media. Or feel free to contribute to the project in Github.
Learn more on how to build data processing applications with SQL with our Streaming SQL cheatsheet





