By
Apr 03, 2023Andrew Stevenson

Andrew Stevenson
With increased applications developed by different engineering teams on Kafka comes increased need for data governance.
JSON is often used when streaming projects bootstrap but this quickly becomes a problem as your applications iterate, changing the data structures with add new fields, removing old and even changing data formats. It makes your applications brittle, chaos ensues as downstream consumers fall over due to miss data and SREs curse you.
You cannot expect developers to stay aligned on a format of data between producer & consumer applications. Especially with 100s of microservices across dozens of engineering teams.
Many have adopted AWS Managed Streaming for Apache Kafka (MSK) service but are still managing their own schema registry. Do they need to?
In this blog we will give some background to using schemas for your Kafka applications, some challenges you’ll face, how you can easily explore and process streaming data via Lenses and why you may want to move to AWS Glue Schema.
You do not want applications to break. Applications need to adapt and add or remove features which means the contract of the data they produce evolves, if uncontrolled it leads to a domino effect of broken apps and data pipelines. The very same data producing applications will also want a contract to consume data for themselves.
This is not new to streaming data. A change in a database table would have a ripple effect on ETL pipelines, data warehousing and analytics. Similarly a change in an API can wreak havoc to anyone consuming it. Hence API versioning and backward compatibility.
To bring sanity we use a Schema registry. The advantage is that by using a Schema registry and a format like Avro we introduce not only type safety but it also offers evolution.
The fast moving consumer facing applications can still iterate quickly and publish data with consistency and governance while ensuring the decoupled consumers can read and understand the data with confidence.
You also now have visibility into what data you have. Not to be underestimated as you onboard new use cases rapidly to your clusters. Schema registry also form part of wider Data Catalogs.
The concept of schema registries and serialization formats like Avro may seem daunting at first, but they are not complicated.
Major schema registries include the popular Avro serialization format. They use schemas to serialize and deserialize data on disk and over the wire. What sets Avro apart is its support for schema evolution, including a set of rules that ensure consumers can read old data with new schemas and vice versa.
In Avro, when writing to a file, the schema is included in the file header, making it easy for readers to deserialize the data. But in Kafka, where messages are sent individually, the schema cannot be sent with every message without negatively impacting performance. To solve this, schema registries use serdes (serializers and deserializers) that attach a schema identifier, which acts as a reference to a schema stored elsewhere in the registry.
There are three main Schema Registry options to consider:
Confluent Schema Registry: This is the first and most widely used registry, but if you are not using Confluent Cloud, you must manage it yourself.
Apicurio: Developed by Redhat, Apicurio is used in IBM Event Streams and Redhat's Kafka service, Openshift Streams. It offers Confluent API compatibility and is a logical choice if you run your own Kafka, especially via Strimzi.
AWS Glue: If you prefer not to run your services, AWS MSK is a natural choice. It becomes a no-brainer when combined with Glue and the integration between the two and other AWS services such as EKS, RDS, Kinesis, etc.
According to Satya Nadella's concept of "tech intensity," cloud software has become a commodity that is easy and fast to consume. Kafka is no different. We believe you can leverage this "tech intensity" to get into production faster and keep things simple.
Schema registries store schema definitions, expose APIs for managing schemas, and provide serdes (serializers + deserialisers) for reading and writing data according to the schemas.
The Confluent Schema Registry attaches the schema identifier by storing it as part of the Kafka message key or value payload after a Magic Byte, which increases the payload size by 5 bytes.
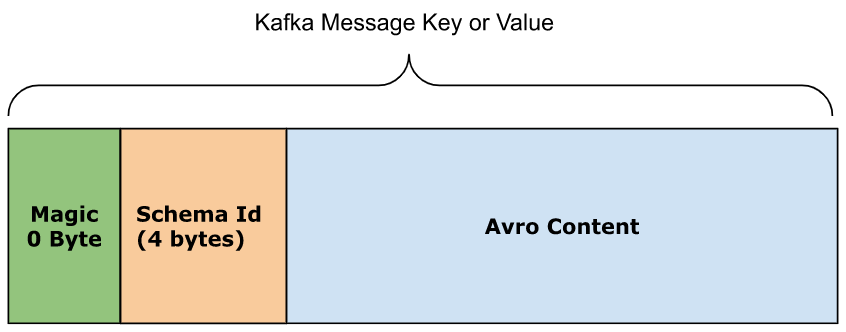
AWS Glue Schema Registry uses a payload approach to identify schemas, utilizing 18 bytes. The schema identification process begins with the first byte (Byte 0), which is a version number. The following Byte 1 denotes whether compression is being used or not, and Bytes 2-17 hold a 128-bit UUID, representing the schema version ID.
The deserialization process considers the first Byte value, and if it is set to 3, then the Glue-based serialization is used. Otherwise, a fallback deserializer is employed. In cases where the compression byte is set, its value must be 5. This ensures that the Avro content is compressed using Zlib.
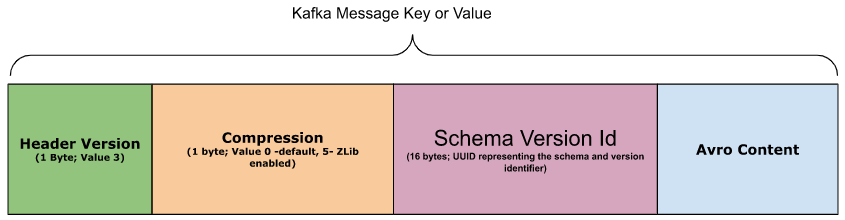
By following this payload approach, AWS Glue Schema Registry enables efficient schema identification, serialization, and deserialization, ensuring seamless integration within the larger AWS ecosystem.
In contrast, Apicurio Schema Registry offers two options for schema identification: headers-based and payload-based solutions. The headers-based approach is the default, but it results in larger Kafka message sizes due to the use of 8 to 32 bytes, depending on the settings. On the other hand, the payload-based implementation uses 8 bytes by default, which is more than the Confluent protocol format's 4 bytes. However, it can be configured to use only 4 bytes.
Remember Kafka has no notion of schemas, it just stores data as a byte array. So you can push whatever you want, and people do, even XML!
You can push JSON to Kafka as a string, Kafka will happily accept this but you will pay the price when reading it. At the console you’ll have to break out your `jq` skills and pick out the fields you want while burning down trees to pay for your CPU cycles. Even worse you may be shipping all that bulky JSON across the wire to have your browser based tool perform the jq kungfu.
It is worth noting that although Schema registries do support JSON schemas, it is generally recommended to use Avro or Protobuf instead. There are multiple compelling reasons for this. First and foremost, Avro boasts a robust and expressive type system that includes complex types such as records, enums, arrays, and maps. In addition, the type system can be expanded using logical types, making it possible to support more advanced data structures like BigDecimal. In contrast, JSON schema only supports a limited range of primitive types.
Another key advantage of Avro is its compactness. Data that has been encoded using Avro is typically smaller than equivalent JSON-encoded data, which can greatly reduce network bandwidth requirements. Furthermore, Avro offers code generation capabilities that simplify creating data structures and serialization-deserialization (serde) code in various programming languages. This can help save time for developers while also improving the quality of the code they produce.
Perhaps the most compelling reason to use Avro over JSON schema, however, is its superior support for schema evolution. As data constantly changes and evolves, it is essential to have a schema that can adapt and remain compatible with existing data. Avro was designed with schema evolution in mind, allowing changes to be made to the schema without breaking compatibility with existing data.
On the other hand, while JSON schema does support open content models, closed content models, and partial open content models, it does not define compatibility rules in the same way that Avro does.
For more information on JSON Schema compatibility, please refer to this resource: Understanding JSON Schema Compatibility.
The Lenses mission is to simplify real time data, to do this we make sure we work with the key components of a data platform. Since governance is a first class citizen in Lenses we have extended our schema registry support to include AWS Glue this covers, for Avro and Protobuf:
Schema management
Lenses SQL snapshot engine for data discoverability and observability
Lenses SQL processors for building real time applications and data pipelines.
Let's have a look at how we glue this together.
Lenses treats integration points as connections, these include Kafka, Zookeeper, Connect Clusters, audit and endpoints such as Splunk and Datadog. Glue is no different.
However, Glue is a bit special, it's a service offered by AWS so first we need a connection to AWS. This is effectively a set of AWS IAM credentials that is allowed to access and manage Glue. Once we have the AWS connection, we can use this to connect to Glue.
Go to Admin → Connections → New Connection
And create a connection to AWS with IAM credentials that have permission to access Glue.
Now we can create a Glue connection.
From the admin section, select the new connection, then schema registry. You will be presented with which flavor of schema registry to connect to. Lenses already supports Confluent API compatible schema registries such as Apricurio but we want to connect to Glue.
Enter your Glue ARN and IAM credentials and test the connections.
Managing schemas in Lenses is now the same as with other registries. In the Schema registries screen you can create, browse, edit and evolve your schemas.
You can create a topic & schema manually through the UI or alternatively via a Create TABLE SQL statement from the SQL Studio:
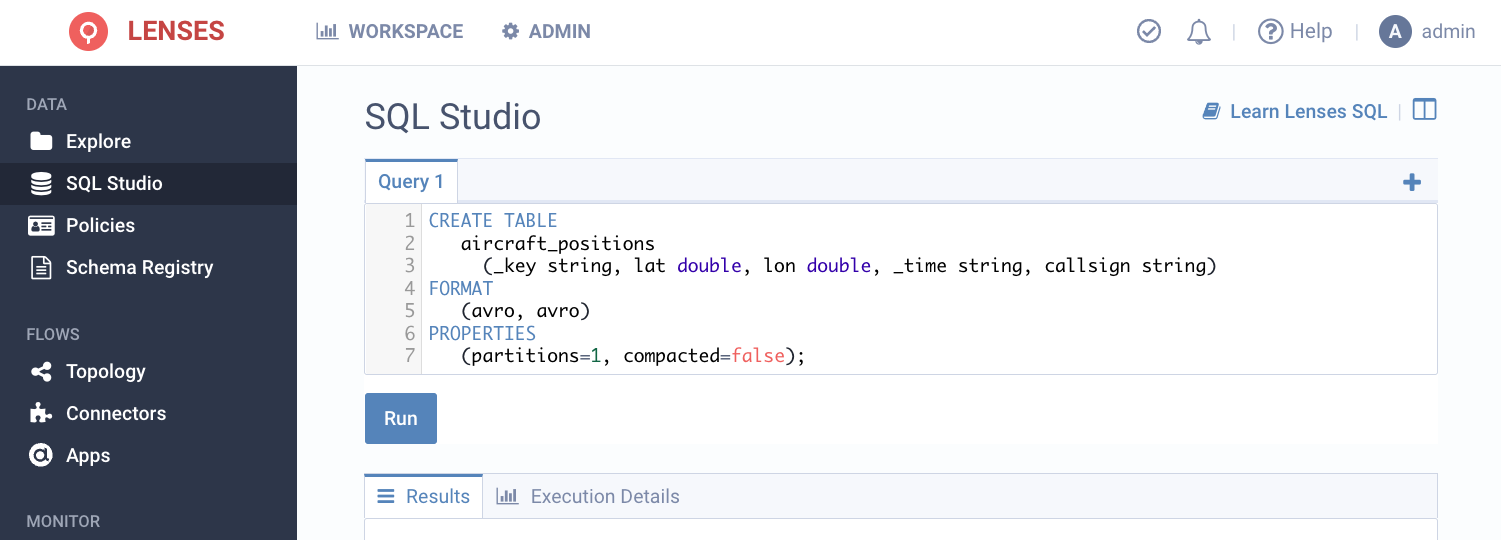
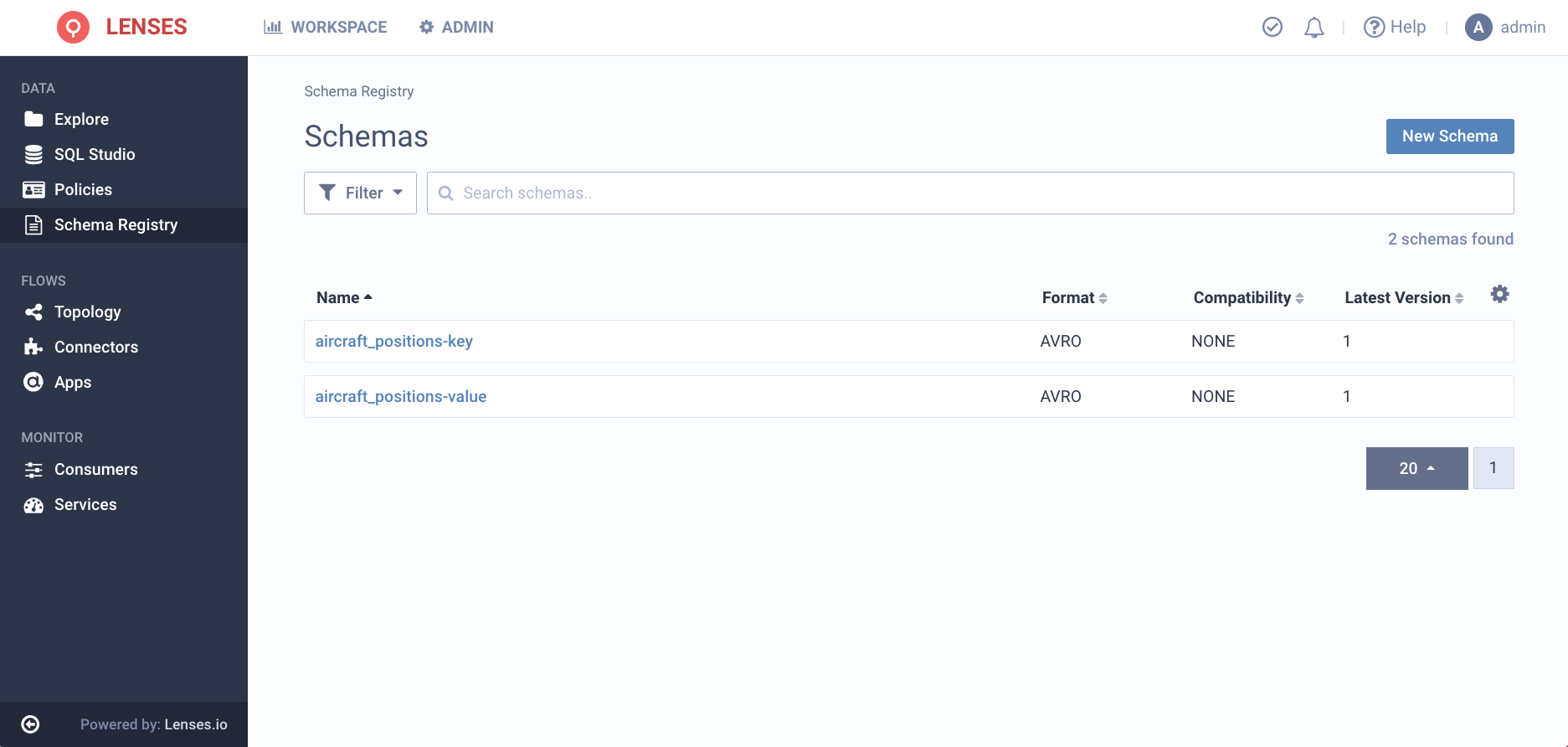
This will create the topic as well as link to the respective schemas for both key & value automatically. You can verify this from the Schemas page
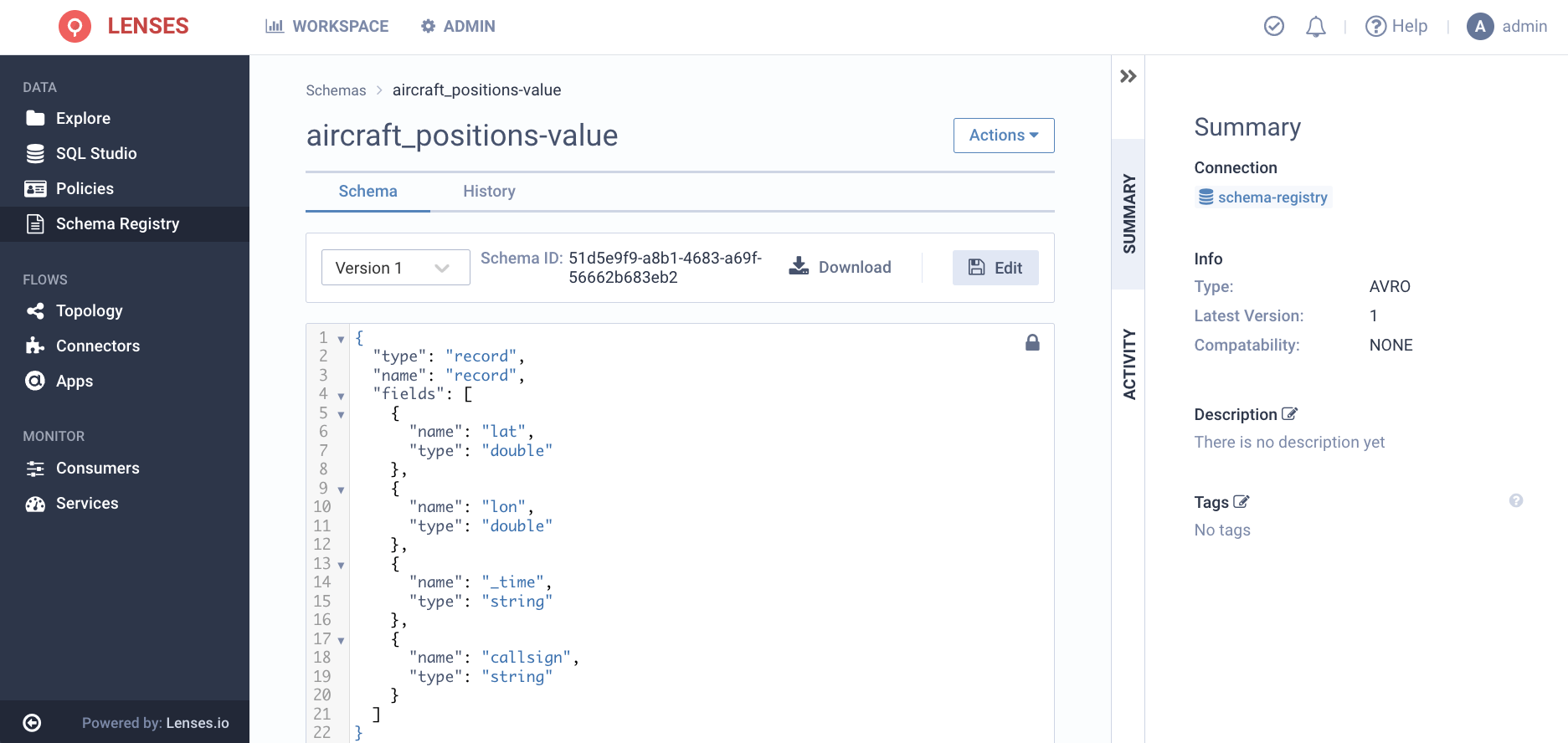
By drilling in, you are in full control to edit & evolve the schema as necessary.
Lets evolve the schema by simplify adding a document string to a field:
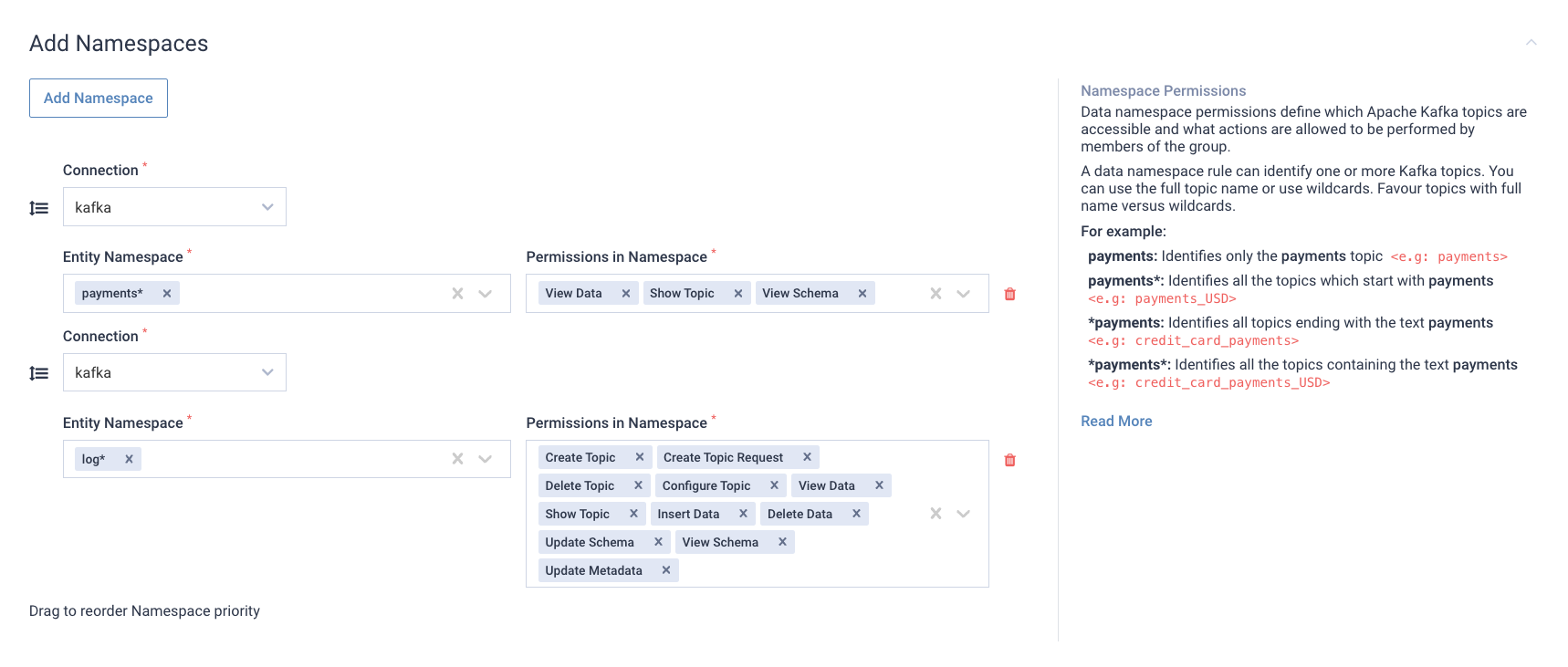
Lenses supports virtual multi-tenancy. Its permission model allows scoping on data namespaces on data source connections to restrict access to any resource.
This not only allows, for example, to restrict access to topics for a particular group to topic with a prefix but also extends to schemas. Only users with access to a data namespace will be able to view schemas associated with topics in that namespace. Additionally, the ability to manage can be further restricted.
For example, users of this group can view and manage schemas associated with topics prefixed with `log` but only view schemas for those with `payment`.
A big part of being productive with Kafka is about data observability and exploration.
Well managed Kafka clusters have schemas attached to topics. You could use the console consumer to read messages from a job and pipe to jq and spend hours trialing and erroring your jq skills but a quick way is with Lenses SQL snapshot engine.
This engine fires point in time queries against topics, Elastic search or Postgres, and sits behind the Lenses Exploration and SQL Studio functionality.
Querying your MSK topics, backed by Glue is straightforward. Just head to the Explore screen to visual explore topics, schemas and fields as well as inspect topic data.
In the Explore screen, we’ll see our topic, if we drill into its details we’ll see its Avro (or Profobuf), who created it, extra metadata and any metric.
Since our topic is new there’s no metrics or data. We can use Lenses to insert some autogenerated messages to test with. This feature is handy and often used to test microservices and debug real time applications.
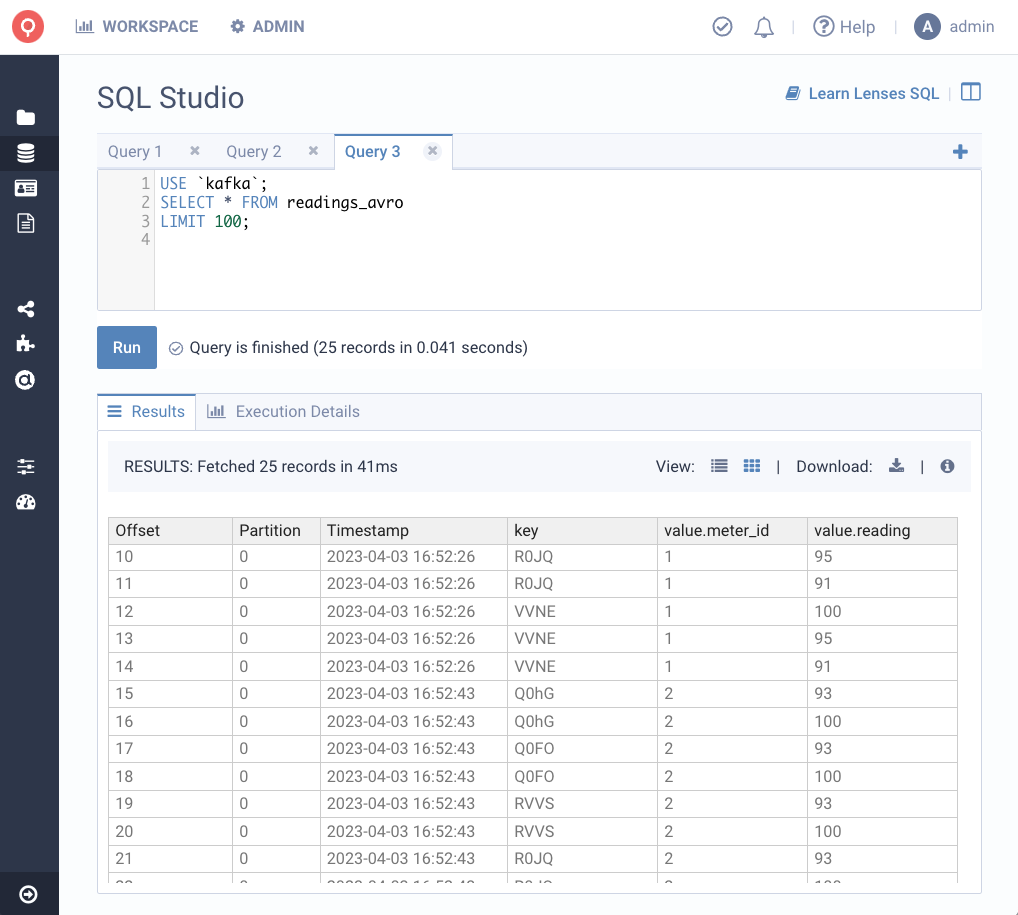
Or we can run powerful SQL queries, in the backend of Lenses, not with client-heavy jq queries like you may be used to. All via the simplicity of the Lenses SQL Studio.
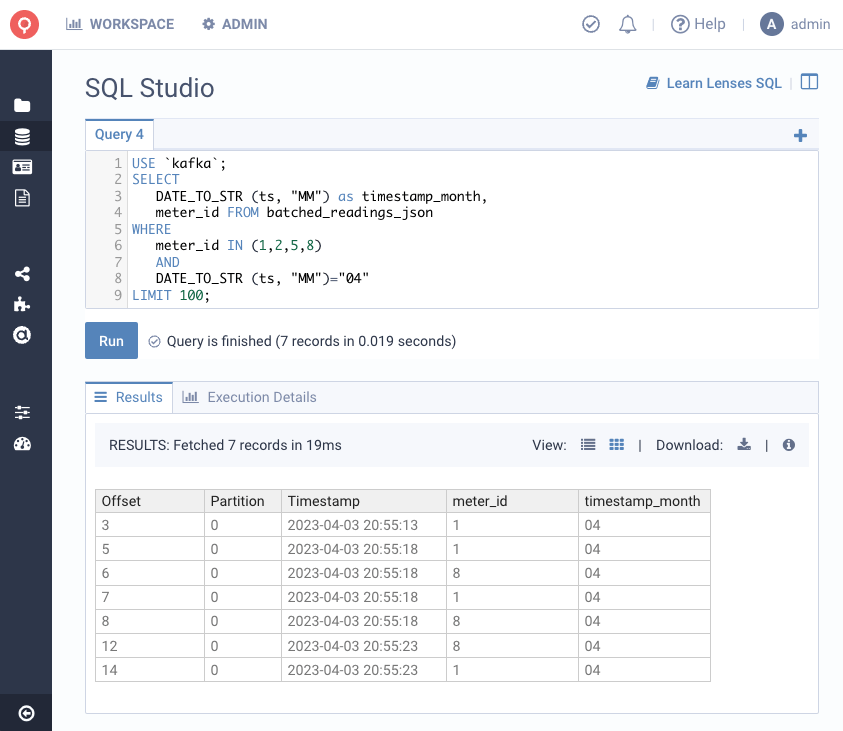
All this is also available via the Lenses CLI or Websockets.
Whereas the use case described above was for point-in-time queries for troubleshooting and data analysis, the same SQL engine can be used to continuously process data in a stream backed by Glue Schemas.
This supports common data processing workloads that might otherwise take days or weeks to write code and have deployed.
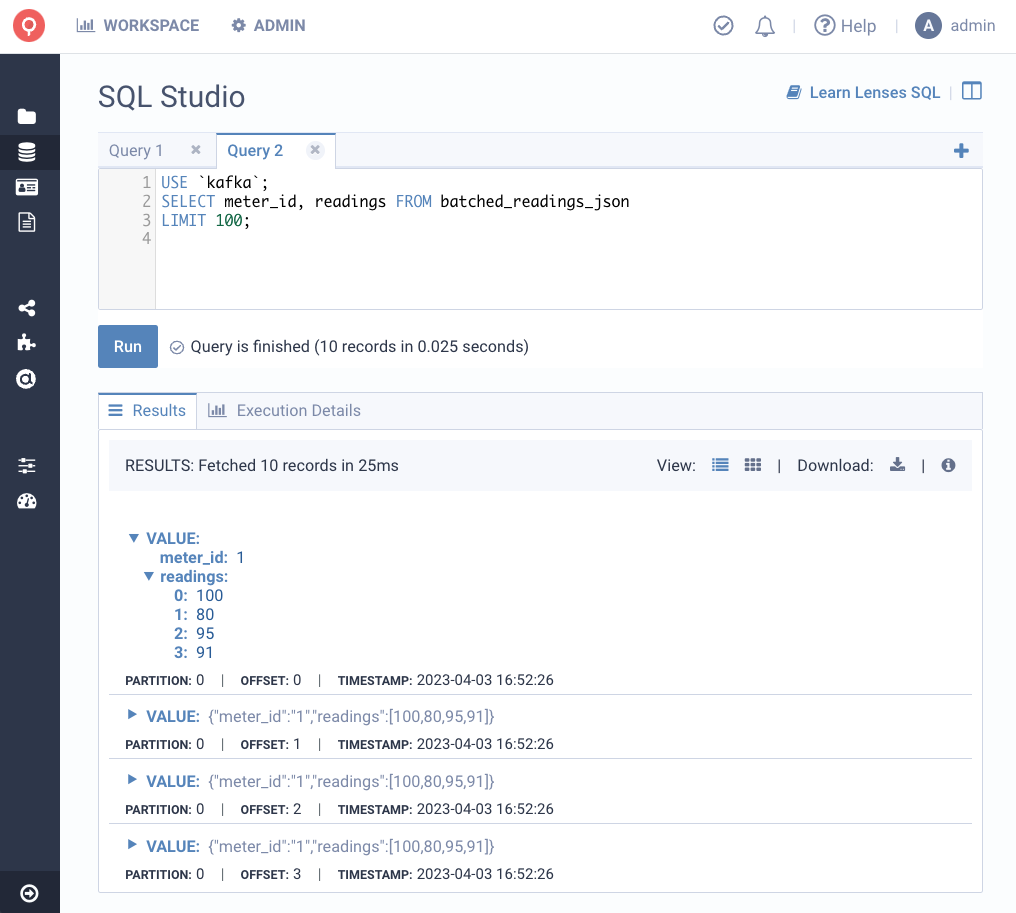
Consider the following data source with an array in a topic formatted as JSON:
It’s common to need to flatten an array like readings whilst at the same time requiring that consuming applications work with Avro. Here’s an example of a Lenses SQL Processor to process this data:
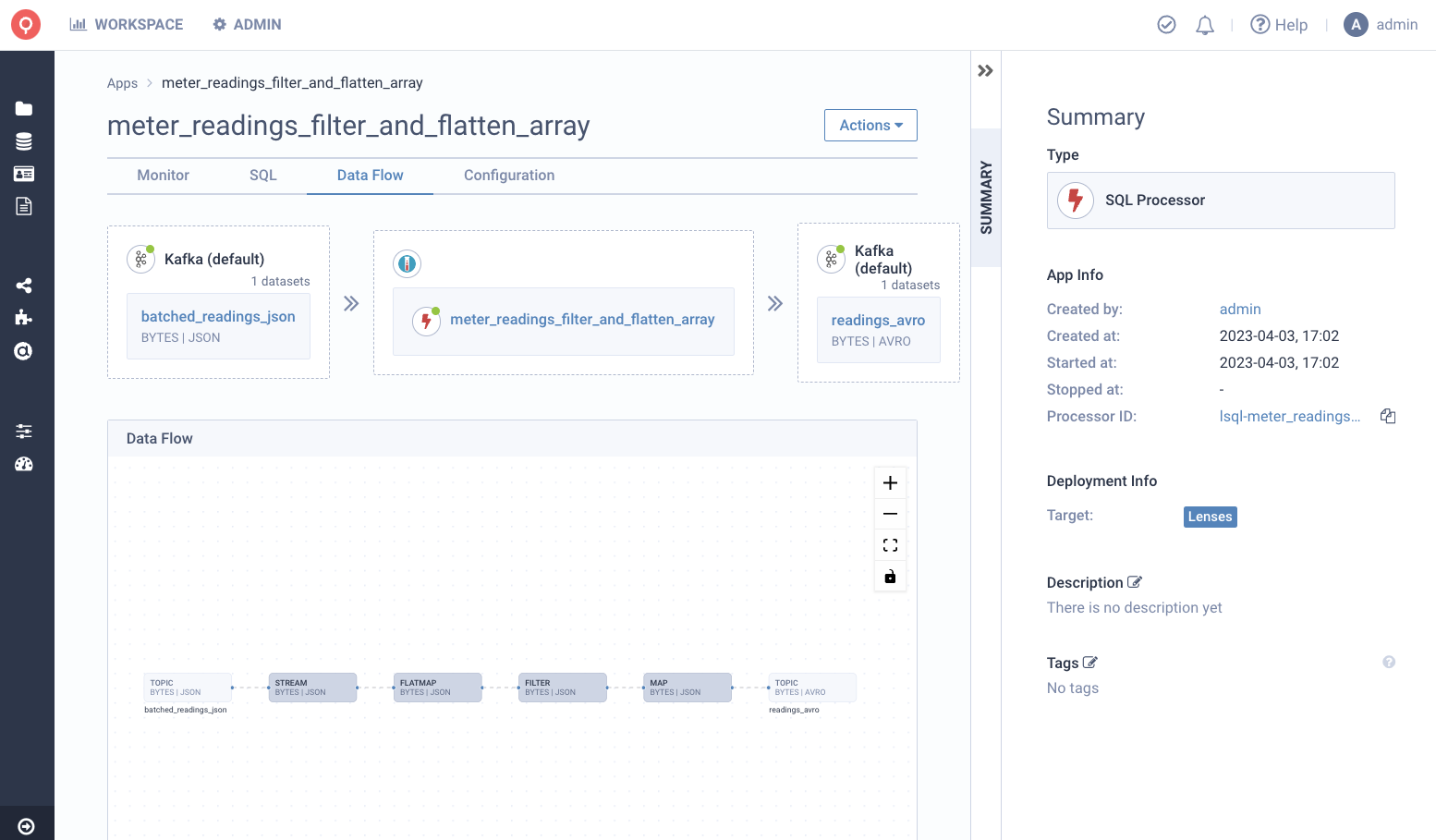
The following is performed:
The readings array is flattened
Results are filtered to reading above 90
The resulting topic readings_avro is serialised in AVRO with the schema in Glue Schema Registry
AWS Glue Schema Registry provides a simple, serverless, and fully managed solution for managing your data schemas in AWS environments, with tight integration with other AWS services and features.
Support for Glue Schema from Lenses now gives organizations the confidence to adopt Glue Schema registry by finally giving the Developer Experience engineers need whilst meeting compliance and governance requirements.
Get started with Lenses via our all-in-one Kafka Docker Box or connect Lenses to your existing Kafka environment in a free trial, both available from lenses.io/start




