

“Is this a Kafka problem?”. Not the sort of question you want to hear from your CEO on a weekend. Or any day for that matter.
But we hear these sorts of war stories often. Without the correct tooling, practices and supporting services, almost every organisation today is either experiencing stress, lost weekends, broken marriages, or yes, messages like that when self-managing Kafka.
Knowing it doesn’t have to be that way, Lenses.io and AWS gathered data and infrastructure engineers from a range of organisations from tech nobility Expedia, Monzo and Just Eat to digital startups together over a quite posh breakfast (croissants and acai almond butter pots) at Amazon HQ in London to share best practices on successfully building and operating a data platform around Apache Kafka.

Don’t give your users a black box
Croissants still in hand, Lenses.io CTO Andrew Stevenson kicked off with a talk on the need for organisations to leverage technology as an enabler and DataOps practices to drive towards “data intensity” if the industry wants to prevent data projects failures.
As a long-standing data engineer, Andrew witnessed first-hand how many of these projects failed to consider how end-users of the data (I think he means the business) would operate the data.
He pulled no punch: “Try giving a command line to the head of market risk at an investment bank. You won’t be having that conversation again I can guarantee that!”. Ouch! Visibility, self-service governance, security, data privacy and making data accessible via skills that already exist in the market are all factors he said must be considered if projects are to be successful.


To play this video, accept functional cookies in your privacy settings.
YouTube video
MSK features and roadmap
Mike Rizzo from AWS provided an overview of the Managed Streaming for Apache Kafka service. A managed Kafka infrastructure takes away much of the time and burden from operating a streaming data platform. AWS allow you to create and tear down clusters on demand. The service is deeply integrated into AWS’ other services including VPC, KMS, IAM and of course CloudWatch and CloudTrail for monitoring and logging. Horizontal scaling on demand is available and AWS ensure everything is patched automatically.
The AWS team finally also presented an impressive roadmap on how they are looking to improve the service over the next few months and years.
Migrating to MSK via GitOps
For those already thinking of moving to MSK, Lenses.io and AWS jointly presented best practices on how to migrate both your data and your application landscape (connectors, topics, applications, quotas).
Mirror Maker 2 would be used to migrate data. MM 2 provides a significant advancement in capabilities from version 1 and now also leverages Kafka Connect, meaning the connector can be managed within Lenses itself.
For the application landscape, Andrew did a live demo of migrating a stream processing SQL application. Lenses exported the application as a self-contained YAML file from one Kafka environment into Git. With a simple merge request, we watched the application effortlessly glide onto an MSK and AWS EKS cluster. The benefit of course of a GitOps approach is speed as well as adding governance and consistency to managing and deploying application flows.

Integrating Kafka with your corporate services
Lenses.io Cloud DevOps yoda Spiros Economakis showed how Lenses fits within a corporate environment without requiring the development of custom integrations and tools.
He showed how Lenses is deployed and connected to an MSK cluster in minutes with a single click via the AWS marketplace. In this way, the MSK configuration is automatically detected (TLS client authentication etc.).
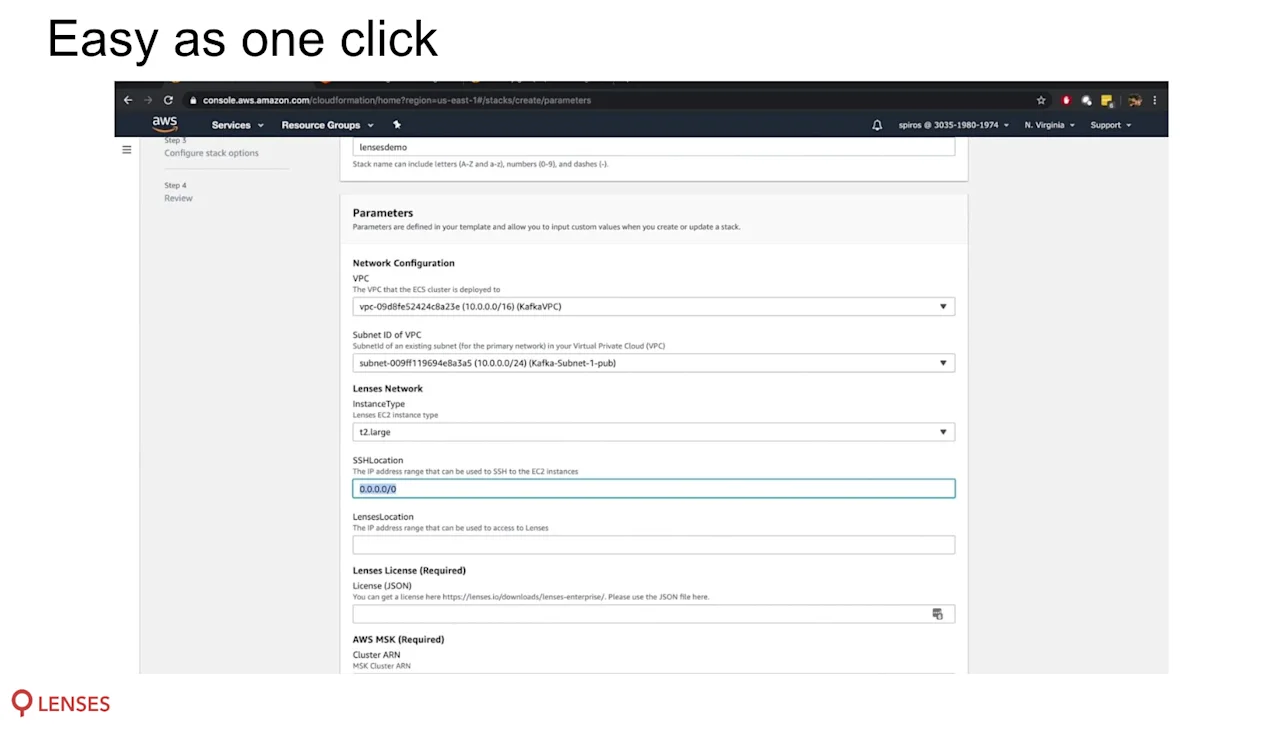
Spiros then touched on areas where many data projects fail: integrating your data platform with your corporate services tools and processes including monitoring, security and auditing.
For monitoring, Lenses.io is one of the few vendors to support AWS’ Open Monitoring with Prometheus framework. Open Monitoring provides access to JMX metrics generated by the MSK infrastructure.
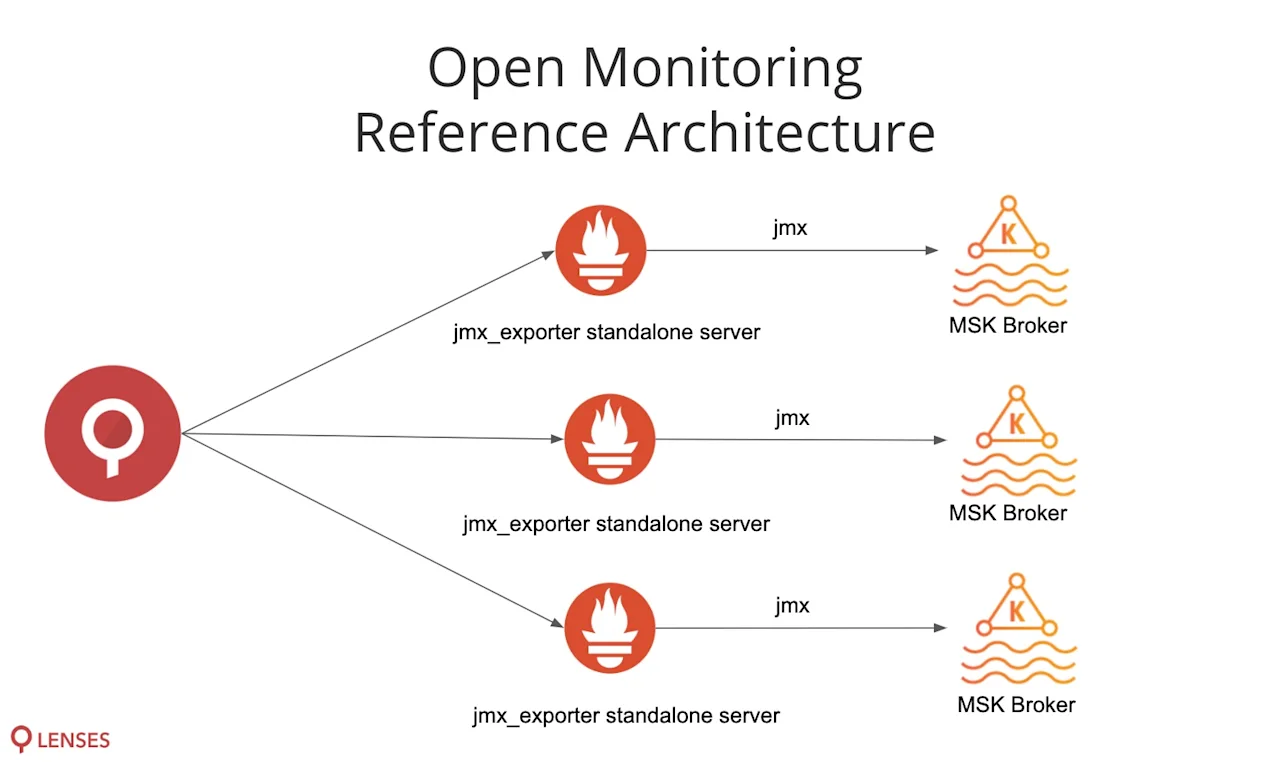
Lenses also exposes consumer and consumer group lag metrics that can be visualised and alerted on in Lenses or forwarded onwards to AWS Cloudwatch.
Staying on monitoring, he demonstrated how custom alerts triggered within Lenses on the health or performance of consumers, applications and infrastructure can be routed to CloudWatch or any third party solution such as PagerDuty, DataDog and Splunk.
For auditing, any audit tails of user actions across your Kafka and application environment (such as creating topics, modifying schemas, restarting connectors) can be routed to third party stores such as an S3 bucket or SIEMs such as Splunk. Monitoring audit logs is often a show stopper for teams wanting to onboard on Kafka.
Avoid seeing dead clusters
The event ended with a show-stealing presentation from Maksym Schipka, CTO of SaaS company Vortexa
Vortexa provide analytics to organisations on the movement of 7-or-so trillion dollars worth of oil and gas over oceans and seas. That’s probably worth keeping an eye on.
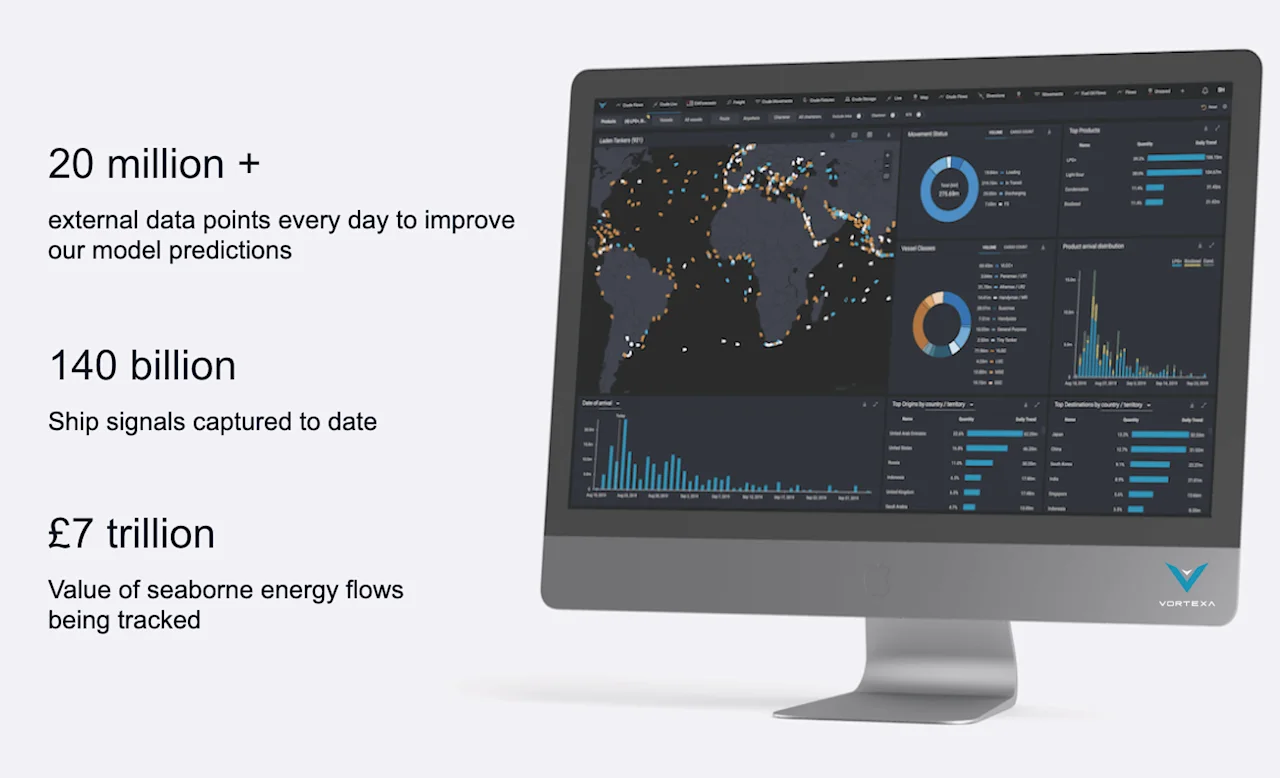
Maksym talked about the sophistication of their analytics. Their service needs to process 10s of millions of data points per day. Instant insights on slightest changes to the movement of ships can be worth 100s of millions of dollars to their customers.
Yet 18 months ago no one at Vortexa had even heard of Kafka.
Maksym was charged with re-architecting their service around a streaming platform. He talked us through the journey they took: starting with the very difficult process of building and managing two self-managed Kafka clusters. "At least twice a week Kafka would go pear shaped” he said. Everything was a trial and error experience. He talked us through some of the painful experiences of his team learning about Kafka, "It cost us a few dead clusters to find that bug!” he quipped about one particular situation.

Maksym’s team were losing too much sleep managing the Kafka infrastructure, trying to understand how application flows looked and troubleshooting when things went wrong.
So the decision to migrate to MSK with Lenses as the DataOps portal was taken. This freed his teams of this burden.
The transformation to Maksym was almost instant: "As soon as our Kafka became more stable and we had the visibility, my team became more adventurous with data” he said. Adding that with the visibility into the application flow provided by Lenses: “we suddenly realised the complexity of our deployment and knew they could make Kafka work”. Since then, his engineers refuse to work without Lenses he said. Quite rightly so, I would do so too!
Thanks for reading.
See the full Lenses.io presentation from the event here
Explore more about Lenses for AWS Managed Streaming for Apache Kafka





