By
Apr 29, 2019Andrew Stevenson

Andrew Stevenson
In this series of blogs, I’ll go over on how Lenses gets your data pipelines into production faster, with security and data governance at every step.
First a bit of an introduction. Organizations around the world strive to be data-driven, seduced by the lure of Big Data and hidden treasures they will find lurking within. Using big data requires learning new systems and jumping into the world of open source technology. Investment is needed to get the right skill sets onboard, learning new distributed systems and new approaches to building them. This takes time and effort away from actually extracting the valuable insights you have been promised, and when you do get your star big data developers on board they probably don’t know your business domain and data.
If you are lucky enough to have implemented a big data pipeline you are probably now migrating it to a “real time” streaming platform. If you are sensible you have chosen Apache Kafka or Apache Pulsar, two scalable and fast distributed systems to act as the data conduits. This is the correct choice - everything is a stream of events and batch is just a subset of streaming. There is no batch. However, streaming brings with it new challenges:
New skill set (again) for the streaming paradigm
Management of your application landscape - how do you deploy and promote through your environments
Visibility into your application landscape - with all those microservices that are now floating around
Applying data governance.
Let’s address the first point in this blog - having to learn new skill sets rather than reuse existing ones and opening visibility into the streams.
I have a background in Data Warehousing, so maybe I’m biased, but for many years I moved TBs of data around happily with SQL Server Integration Services and used SQL for the majority of pipelines I built. More importantly, the business users were also able to build the pipelines and reports using a common skill, SQL.
Once I stepped into the “open source” world, the tooling was, if I’m honest, appalling. Writing custom code, a massive lack of enterprise features (security) and zero documentation. This doesn’t fly at tier 1 investment banks. Pipelines I used to be able to build in a few days took months. I survived, with slightly more grey hair, but business users struggled. I saw this first hand in many big data projects.
Those with the business knowledge, the domain expertise, who know the data are sidelined
At Lenses, we recognize this. Lenses, our DataOps platform, opens up data pipelining and data exploration again to all users in an organization, empowering the data literacy that already exists.
Let’s take a look at some, but not all, of the features the Lenses SQL Engine, version 2.3 supports;
Intellisense, not just autocompletion
Avro, JSON, XML, CSV, basic type and Protobuf support
Full support for joins and aggregations
SQL browsing, viewing and exploring data in the browser, Python, Go, CLI and Websockets
Support for Hortonworks schema registry and others
Role-based security with topic black and whitelisting
Scale-out options with Apache Kafka Connect and Kubernetes with no need to install more
servers to distribute the load. Run with vanilla Apache Kafka
Access to and filtering/joining on the key and values
Access to headers and keys
User defined functions and user defined aggregate functions
Table based and continuous queries with live aggregations.
These features and the easy-to-use browser UI means Lenses opens up data pipelines and exploration to a wider audience. Business analysts, data scientists, and developers can all now inspect data, construct flows and build data-driven applications without the need to bring in expensive specialists.
When you build a data-centric platform with Apache Kafka®, data flows through “topics”. For those unfamiliar with Kafka, a topic is where Kafka stores the data. Think of it as a table of messages that Kafka pushes to subscribers.
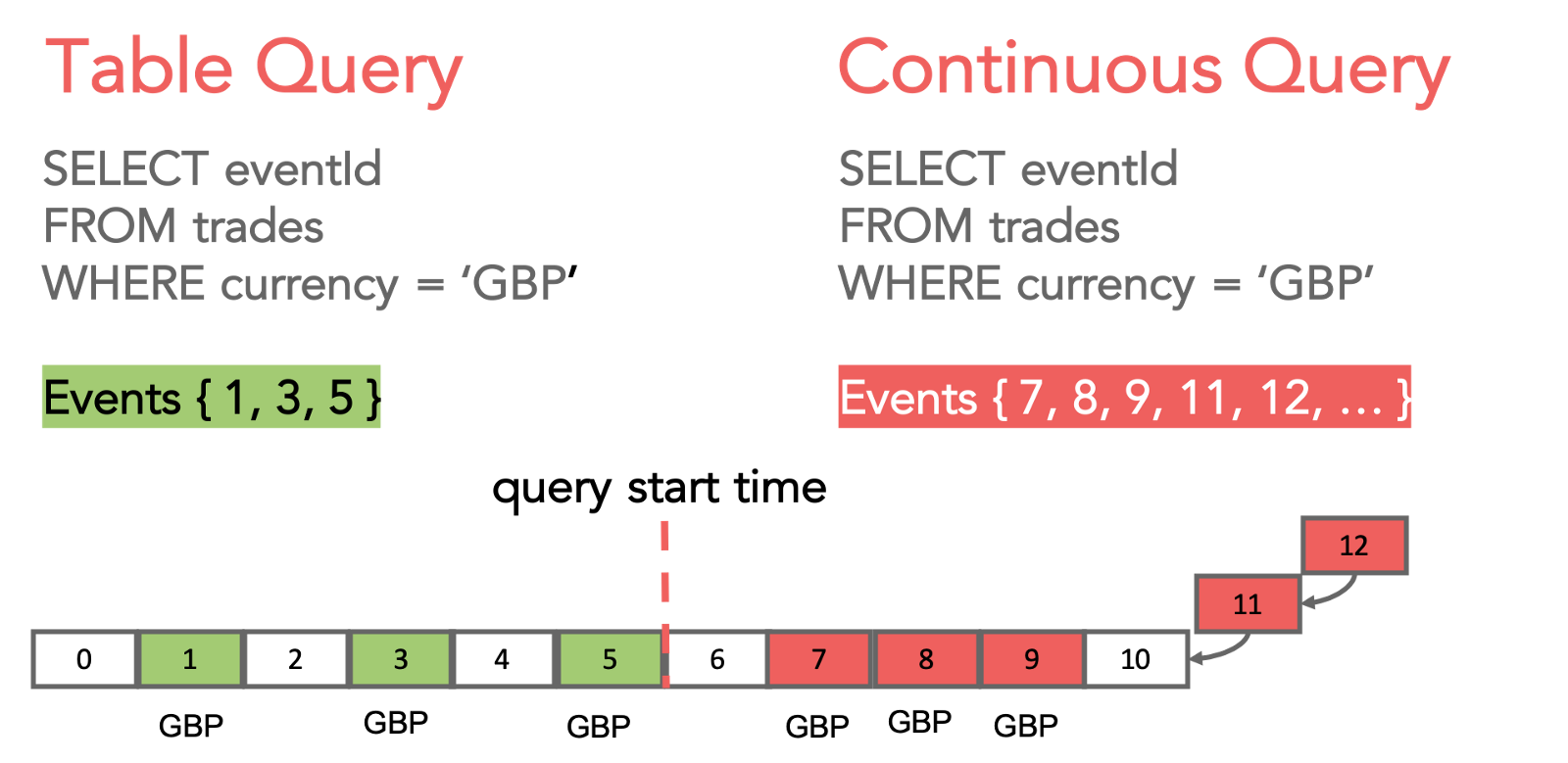
Lenses SQL Engine supports SQL browsing of topics. Users can run queries in “table browsing” and “continuous” mode.
Table queries allow users to gain insight into the data moving through the topics bound by a range. You can, if you want, retrieve all the data in the topic up to the point the query was issued. However, Lenses SQL allows you to do more than just that. You can apply where clauses, filter by message timestamp, join, aggregate and access the value and key fields. Naturally, you have access to typical scalar functions like anonymizing data, string functions, etc. Lenses supports UDFs in Java, upload your jar and it is made immediately available, with intellisense.
You can even control the underlying Java consumer settings. We support all the standard data formats even - Protobuf - for those of you using it for low latency. For a more technical view of the features please check out the docs.
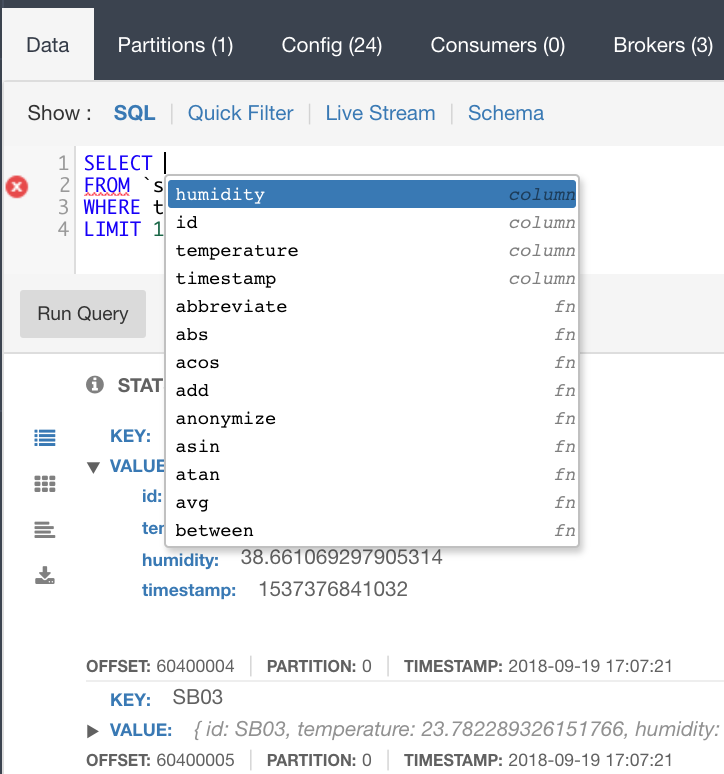
Lenses gives a 360 data operations view. You can query specific topics and view other information about the topic from an operations perspective but also from the SQL editor page. This gives a familiar SQL editor feel to users who are data literate. It also includes the most advanced context-aware intellisense of any SQL streaming editors currently available. Check out the geospatial functions - they are very cool. Below is a screenshot showing the querying of sensor data, in Protobuf format. Pretty straightforward. Type your query with intellisense, switch to a live stream and even inspect the topics, consumer, brokers and schema configurations. Export the results to the mighty Excel if you wish!
The UI offers other goodies as well, such as changing the presentation layout from raw, tree to a grid format,quick filters on partitions and offsets as well as inserting messages or even deletion, which can be handy for testing event-driven applications. You even get query stats.
Continuous queries offer the same functionality as the table based engine, but you get new messages arriving in the topic that match the query pushed to you - it is a live stream of events. Build an application and subscribe to streaming data with SQL. Easy.
Allowing all users to view a stream of data in Apache Kafka is great but to build useful pipelines you often need to transform and enrich these systems. This is familiar ground to those with experience in data warehousing or any form of data integration. Filtering, transforming, lookups, and aggregations are the bread and butter of these workloads. Lenses SQL Engine allows you to do all these as well. We can take a simple or complex transformation, express it as SQL and deploy and manage it for you.
Let’s look at an example of a trader in a trading firm. She subscribes to several streams of data - maybe trade and event information from her trading platform plus a feed of stock product data from Bloomberg. She might be doing this from R Studio, from where she can deploy an instance of our Bloomberg connector to stream live Bloomberg data into a topic and use SQL browsing to discover and visualize the data. Once she is happy, she decides she needs to join the data and do some transformations. With Lenses, she can deploy long-running microservices called SQL Processors. They will continuously process incoming data and write it back as a new stream to a new topic for others to subscribe to. He can do this all from the Lenses UI, R Studio, Jupyter or the command line.
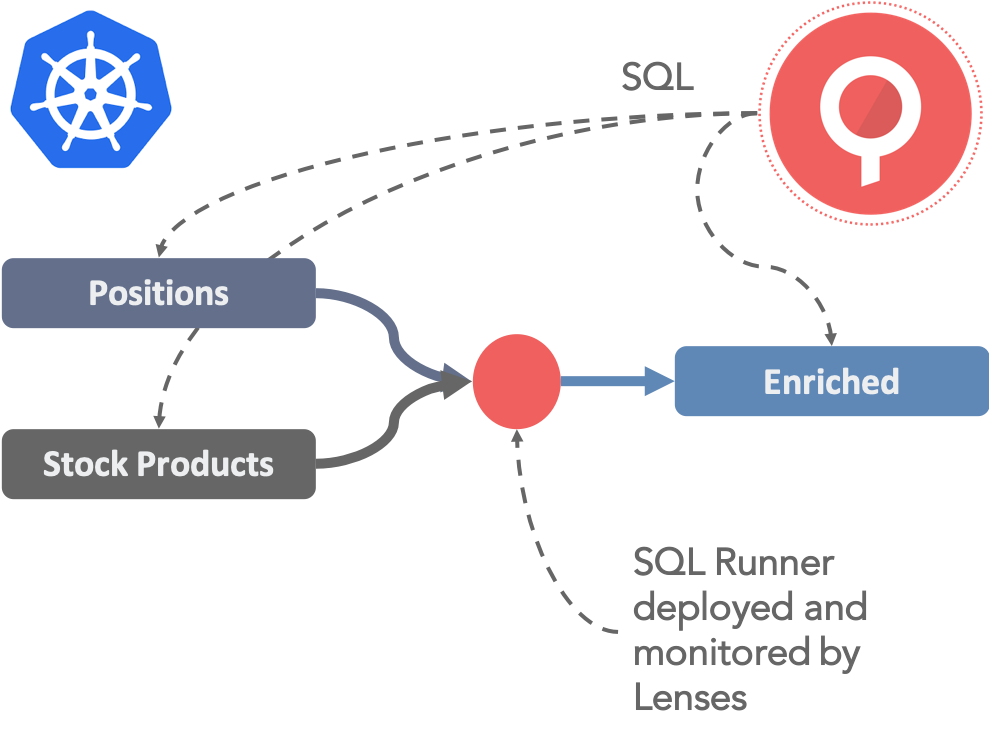
We can submit SQL Processors to Lenses, via the UI, the Rest endpoints or any of the Lenses clients. Lenses will either run it locally or push out the deployment to Kafka Connect or Kubernetes. The deployment details are abstracted from the user. The workflow is the same. Browse and explore your data with Browsing or Continuous SQL, deploy SQL processors to transform and aggregate data, subscribe to the output with SQL and maybe deploy one of the many connectors we have to sink the data somewhere like Elasticsearch.
Below is a simple query to perform a typical enrichment task joining a stream of trades against a stream of products for product lookup. You get the point.
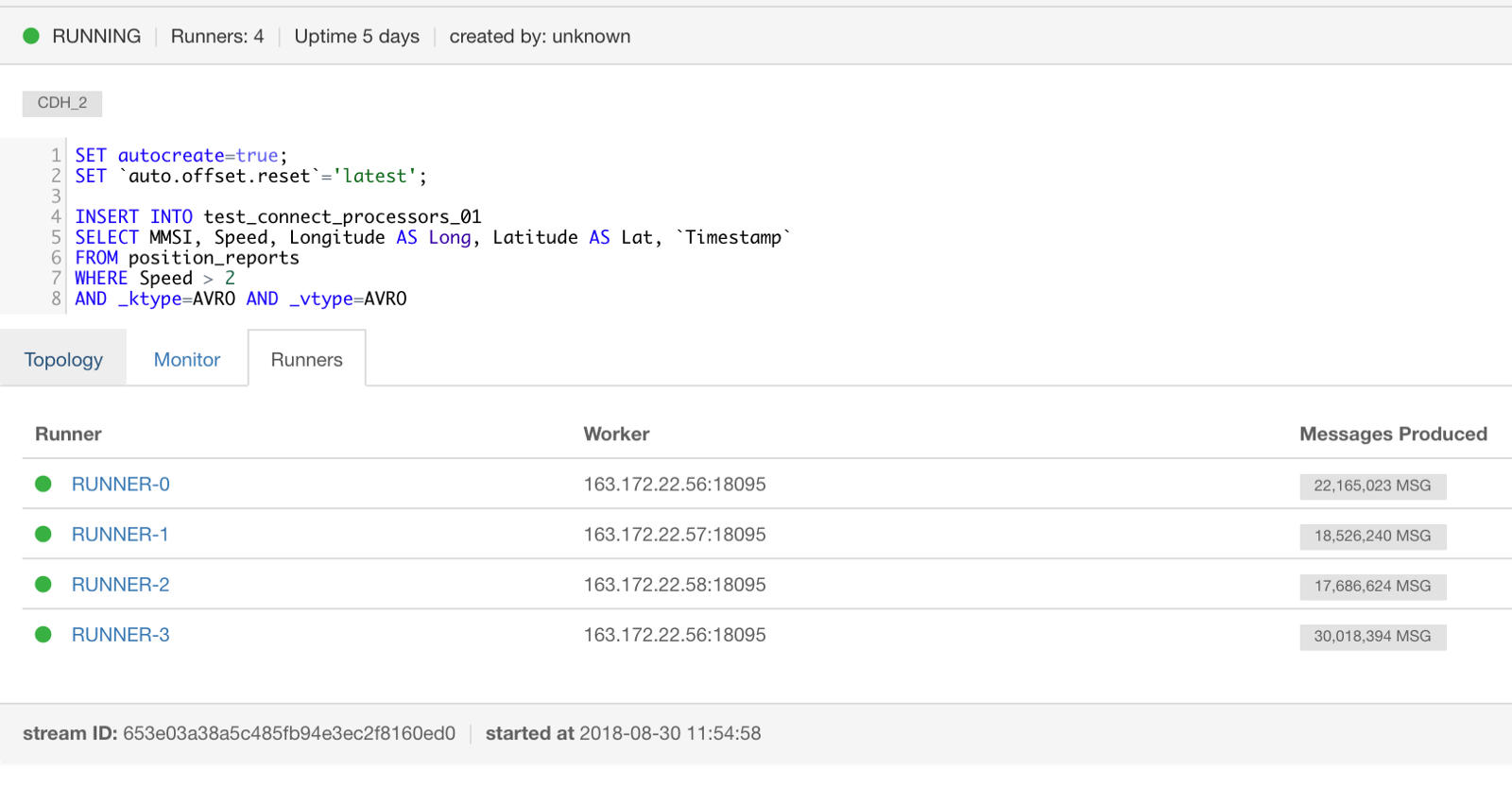
Using Lenses we can deploy, monitor and scale SQL processors. No code. Awesome. Those with a keen eye will notice we have three different execution modes, in-process (local to Lenses), Kafka Connect and Kubernetes. Data pipelines must be resilient to failure and we must be able to scale.
In process is the development mode. SQL Processors run as threads inside Lenses. You can stop, start, scale and create as many as you want, resources permitting.
Kafka Connect, part of the Apache Kafka® distribution, is a way for Lenses to distribute and scale processing if you aren’t using a container orchestration. We don’t require you to install yet more services to scale. You can scale out with vanilla Apache Kafka®.
If you are interested in Connect and its primary design purpose, moving data in and out of Apache Kafka®, have a look at our Stream Reactor open source project. It also contains SQL, the first SQL layer introduced into the Apache Kafka® ecosystem. Read about how Centrica (British Gas) used our Elasticsearch connector, with SQL to great effect.
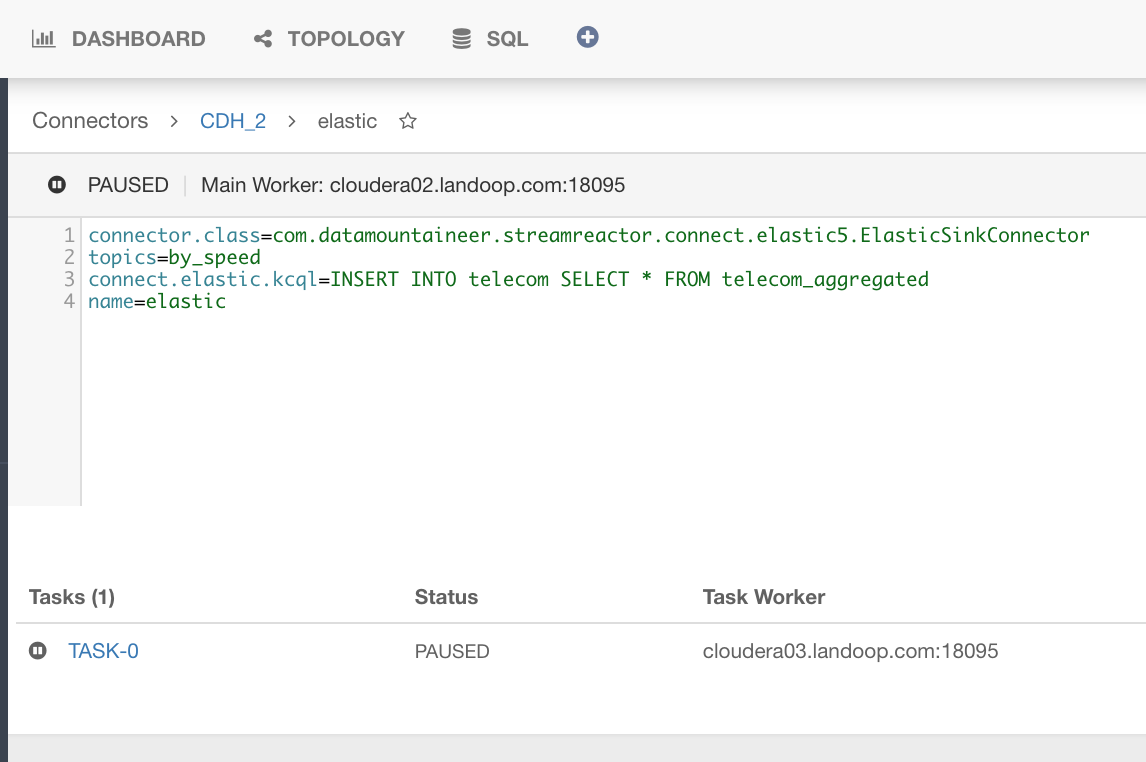
Container orchestrators are a cooler and better way to scale and distribute workloads - Kubernetes has won the container wars and naturally, Lenses integrates with it. Not only can Lenses itself be deployed into Kubernetes with Helm but we can also deploy the SQL processors inside it. You can stop/start and scale the processors. For increased visibility, you can also view the logs of the pods.
The Lenses UI will also give you details about the metrics and consumer lags for each runner in your processor and how it is performing.

There’s also more swag - we show you the internal topology of the processor. So for example, you can see if your topics are not partitioned correctly and are causing the processor to repartition for you, which impacts performance. Below are some of the metrics from the Application topology view. More on how and why Lenses gives you an interactive view of your application landscape in the follow-up blog posts.
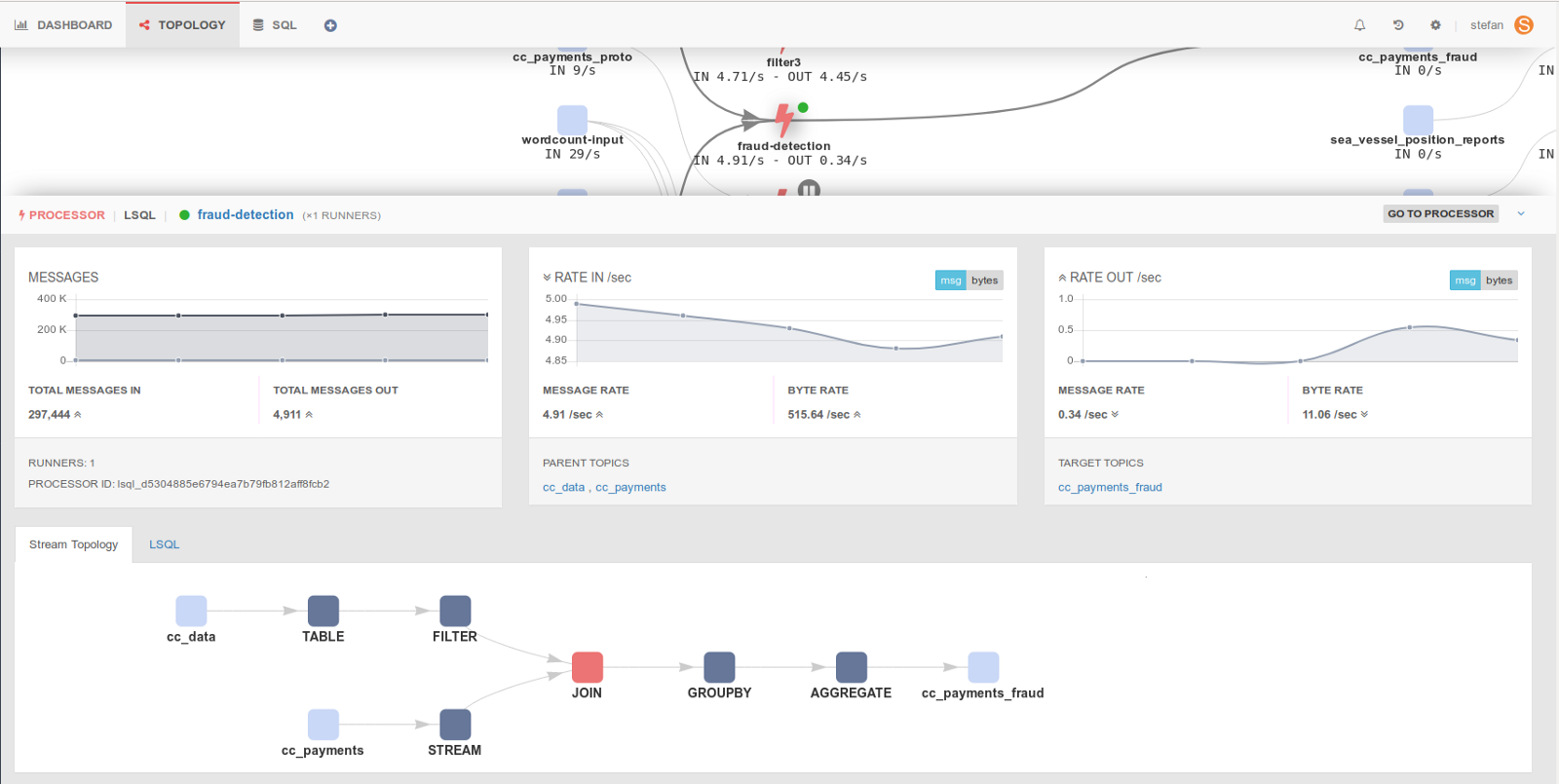
We don’t show every metric that Kafka has to offer, you’re better off doing that with Prometheus and Grafana for lower level DataOps granularity. There’s more to your streaming platform than Apache Kafka® and you should be monitoring this anyway.
For the security and data governance conscious people amongst us, Lenses supports role-based security with topic black and whitelisting so you only see what you are allowed to. We even audit the queries so you can answer “who queried what and when?” and you can also do that with SQL if you want. In addition, the Data Policies features let you define redaction policies on sensitive data and explore where they appear in your application landscape.
Being able to explore data as it flows via SQL allows every person to contribute to building data-driven organizations. Users are able to validate and analyze data in motion without the need for specialist training or relying on developers all the time. Business analysts and data scientists can get to the data quickly without waiting for it to come out of the pipes and land in a persistent storage layer. With Lenses SQL processors you don’t need expensive and hard to find experts - your existing data experts can build production grade pipelines in minutes, like they used to, while Lenses takes care of the deployment and monitoring.
You can do all this from Jupyter or Zeppelin notebooks with the Python client. Or with the Javascript client and don’t forget the Lenses CLI and Go client. If you prefer you can do it via the UI and take advantage of our leading intellisense editor.
SQL is configuration. All Lenses components are configuration. Configuration is code. We can build automated, auditable, repeatable and scalable pipelines, promoting them through environments to production. We’ll also discuss this point further in a future post as we tackle DataOps and GitOps.
Not every application can be written using SQL, that’s true, but a large percentage can, especially for data integration. If you are using KStreams, Akka or Spark, Lenses can still see your applications. If you use our topology clients, they will be visible in the Lenses topology.
Lenses opens SQL browsing and access to all. It deploys, scales and monitors all aspects of your flows to help you build enterprise-ready data pipelines quickly, whatever your setup. Lenses deploys on-premise, or Kubernetes and alongside all the major cloud providers such as Azure HDInsight, AWS, Google Cloud, but also managed services like Aiven.
We also do all this securely and with audits so you don’t have to. Get started with the Lenses Development Box.
Having the ability to archive Kafka topic data is now essential. In th...
Mateus Henrique Cândido de Oliveira





