By
Nov 20, 2017Antonios Chalkiopoulos

Antonios Chalkiopoulos
In this post we are going to see how you can leverage Lenses and SQL (Lenses SQL - our own SQL layer solution for Apache Kafka called Lenses SQL) to create, execute and monitor Kafka Streams application defined with SQL.
If you’ve worked with data before, a lot of time is allocated to extracting and
massagingthe data from various sources, and enhancing them into the required format.
Lenses SQL Engine for Apache Kafka makes your ETL challenges a quick and integrated experience. Lenses SQL covers the full capabilities of Kafka Streams API while providing enhanced and unique functionality not yet available on other implementations: topology view, full Avro support from day one, joins on key as well as joins on multiple value fields and more.
Before we look into performance, we will first cover a few scenarios encountered while working with data on Apache Kafka:
Consider a Kafka topic receiving sensor data. This is a common use case for Internet Of Things(IoT).
A requirement we came across at one of our clients is identifying hot sensors and push those records to a different topic while cherry picking some of the fields.
We take this scenario a bit further and while we pick the temp field we convert the value from Celsius to Fahrenheit.
A SQL processor can be provisioned via Lenses UI where you also get to visualize the Kafka Stream flow topology.
The processor above is executed with 1 runner (more on this later on), auto-creates the target topic (if it does not exist), and associates the result of this query with an Avro schema, and executes this unbounded data query.
Both sensors and hot_sensors topics contain the entire history of the time-series. What if an application is only
interested in the latest state of the world without having to read all the records ?
This time, we are creating the target topic explicitly while specifying the partition, replication-factor and cleanup.policy. Lenses SQL allows you to configure any of the settings available for a Kafka Streams application including consumers, producers and rocksdb specific parameters.
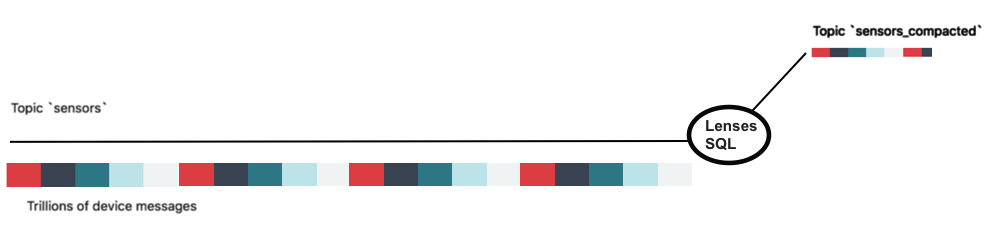
The source topic might have Billions / Trillions of metrics, but the target topic is compacted and contains the latest message from each sensor as long as the record key is set to the sensor identifier.
Counting data on a stream is a typical scenario in stream processing and Lenses SQL makes it easy to achieve it. You can filter, group and count messages over a time window. This first example counts all the messages on a 1-minute interval:
There might be cases where you want to apply a filter and then do the counting. Consider the scenario where you want to count the number messages received where the temperature is above 25 degrees Celsius. Such logic can be describe in Lenses SQL like this:
Another use case could be highlighting those sensors for which at least X messages have been sent to the sensor topic within a time window of 1 minute.
The Lenses SQL code below groups all the messages received within a 1-minute time window by the sensor identifier (the stream record key is the sensor unique identifier) and
counts the number of messages received from that source but only pushes the results to the output topic if the computed value is at least 5.
You can find more about Lenses SQL including its join capabilities and data browsing by navigating to https://docs.lenses.io
Where is Lenses SQL executed and how does Lenses SQL perform ?
By default Lenses runs the Kafka Streams applications resulted from Lenses SQL inside its own process. This is what the developer version (which is free!) comes with. However we support two additional modes targeting enterprise customers where scalability is important: KUBERNETES and CONNECT.
A single runner runners=1 (in the UI) means that a single instance of the resulting Kafka Streams application will be run.
The above code running on one of our 3-brokers Kafka cluster handles 100-135 K msg / second. But we can do better by tweaking a few knobs. Executing the same query with runners=2 the throughput reaches 200-270 K msg / sec.
However there is still room for more improvements. Performance can be boosted further by considering the output topic partition count. By default the partition count is 1 but you can easily set it to a different value like in the code below:
Having 5 runners and higher partition count, on the same cluster the SQL processor managed to handle 500 - 570 K msg / sec.
We run the same processor on a larger kafka-cluster with the output topic having 30 partitions and executing the SQL with 10 runners Lenses SQL has reached the 1 M msg / sec rate.
Running one instance of Lenses (maybe with HA enabled) could be enough for some projects, but what happens when fault tolerance, performance and processing guarantees are important?
For that we would need to scale our Kafka cluster, as well as scale the processing. Lenses integrates with your Kubernetes cluster or your Kafka Connect cluster and allows you to scale and orchestrate your stream processing engines.
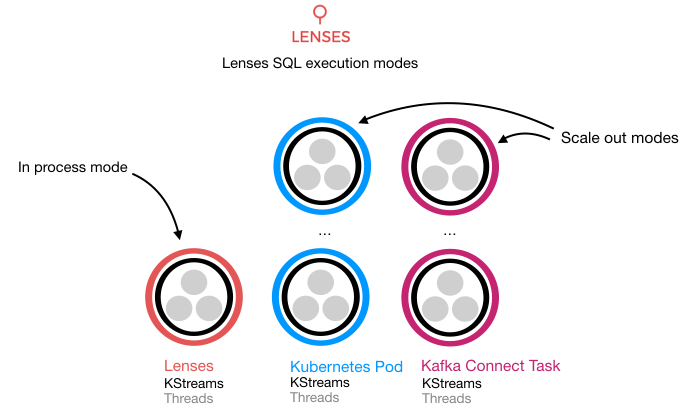
Lenses SQL is packaged in ‘containers’ ready for your Kubernetes cluster. Lenses is fully integrated with Kubernetes, and allows you to architect your streaming ETL.
Lenses SQL is also provided as a connector for Kafka Connect; this option is more suitable for a VM based infrastructure, rather than container based. Once the connector is installed in the classpath of your Kafka-Connect distributed workers, Lenses will automatically integrate with it.
Lenses SQL draws from the experience of working over many years with distributed execution engines, from Map/Reduce to Spark and Flink, and applies the same practices and principles to KStreams. It first builds the physical topology and then prepares and optimizes the execution plan.
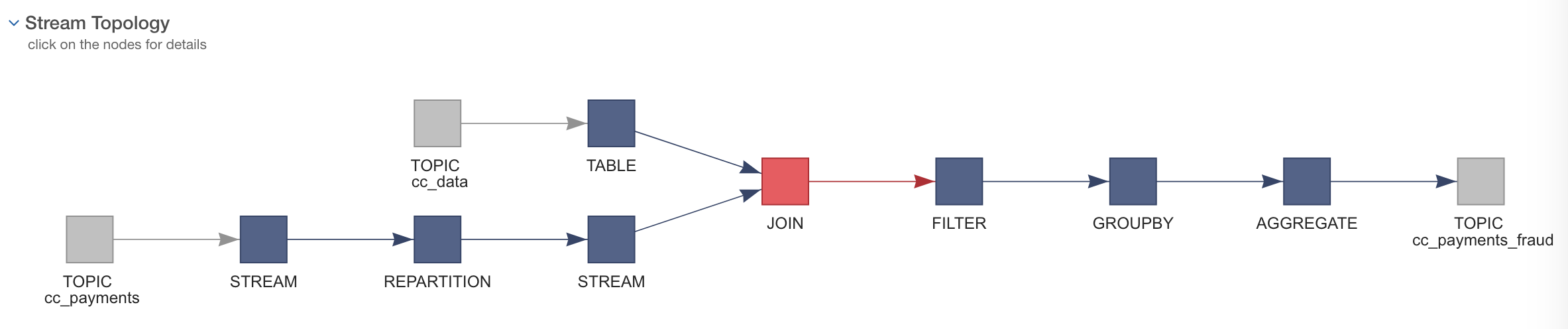
You might have noticed in the above topology, Lenses SQL even handles re-partition of topics - a mandatory step required by Kafka Streams API in order for the join to happen when the topics involved do not share the same partition count number. With monitoring and alerting also provided as part of Lenses, you end up with a complete and enterprise-ready SQL solution for Apache Kafka.
When dealing with Avro payloads, Lenses SQL is able to perform static validation leveraging the existing Avro schema(-s) involved. Therefore when the field selection is not in sync with the schema the validation will raise an error which will be displayed in the UI thus making for a better environment to write SQL on Kafka.
Lenses makes streaming analytics accessible to everyone. It empowers users, both technical and non-technical, to run comprehensive, production-quality streaming analytics using Structured Query Language (SQL). Getting started with processing streaming data with Kafka Streams requires heavy development and infrastructure work to be done. With Lenses we are getting all the hassle of setting up your applications as well as scale them out in a containerized or VM environment. The Lenses SQL engine capabilities are complemented by an easy to use web interface, that visualizes the topology of the processor, but also a rest endpoint to register processors as part of your CI or further integration.
Blog: How to explore data in Kafka topics with Lenses - part1
Blog: Describe and execute Kafka stream topologies with Lenses SQL
Blog: Apache Kafka Streaming, count on Lenses SQL
Lenses for Kafka Development The easiest way to start with Lenses for Apache Kafka is to get the Development Environment, a docker that contains Lenses, Kafka, Zookeeper, Schema Registry, Kafka Connect, and a collection of 25+ Kafka Connectors and example streaming data.
Reasons and challenges for Kafka replication between clusters, includi...
Andrew Stevenson






