

Updated by Drew Oetzel: 26th May 2025
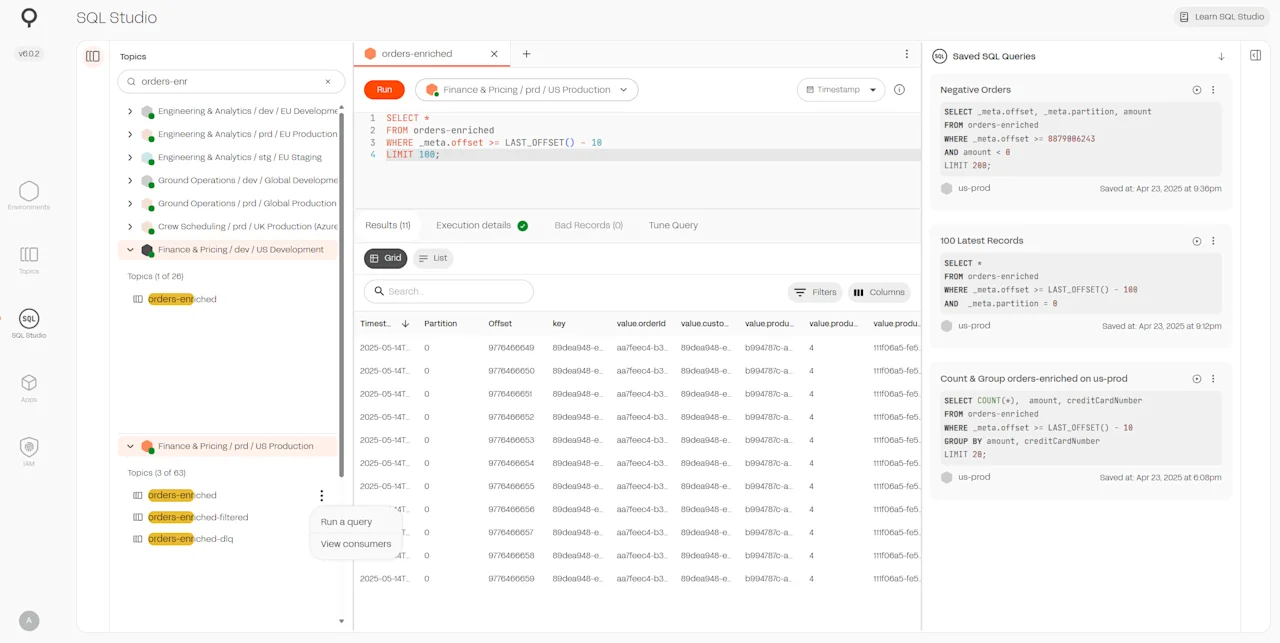
Do you need a unified experience to discover and manage topics, schemas, or a connector with a SQL interface? Whichever Kafka registry you’re using, Lenses provides one of the most complete Kafka UI tools available.
A Kafka schema registry is like a library of rules for how data should be structured when flowing through an Apache Kafka streaming architecture. Kafka schema registries store and manage schema versions, including formats like Protobuf, allowing consumers and producers to safely publish and consume data to Kafka.
Lenses and Kafka Schema
Lenses supports any Confluent API compatible schema registry, including AWS Glue and Apicurio. This means you can integrate your existing Kafka registry directly with the Lenses developer experience. Essentially, it’s a fully featured experience for your underlying schema registry that allows visualization and exploration of registered schemas.
But that’s not all. Lenses also provides:
- The option to explore and search Kafka schemas
- Avro evolution compatibility checks
- New schema registration
- Avro + Table schema views
- A visual change log of schema changes over time
If a Kafka Schema Registry is not in use, Lenses will automatically construct an internal schema registry. Lenses does this by inferring the structure and format of the data within your Kafka clusters. This includes formats such as JSON or XML. (Note: using XML with Kafka is not recommended.)
Lenses SQL uses this information to discover and visualize your data.
How to download Lenses
Follow the instructions to run Lenses.io Community Edition.
The value Schema Registry brings
A few words about Kafka and the Schemas, and the value it adds to your streaming platform.
Overall, Kafka is not picky about what data you post to a particular topic. You can send into the same topic both JSON and XML and BINARY data. Usually, users simply send a byte array created by the default serializer.
However, multiple downstream applications consume data from Kafka topics. If by mistake some unexpected data is sent into a Kafka topic, these downstream applications will start to fail. This can happen quite easily. And because Kafka does not allow message deletion, this could result in serious failures, poison pills, and more.
Following engineering best practices, such as sending Avro messages, can help avoid this by allowing schemas to evolve. This can also provide a central point for your organization to explore and manage data:

The goal should always be to use Avro messages, the Kafka Avro serializer and the schema registry. This introduces a gatekeeper. That gatekeeper, in turn, registers all data structures flowing through your streaming platform. At the same time, it rejects any malformed data and provides storage efficiency.
Schema registries have now gained wide adoption, with several providers offering them. For more examples, read ‘Schema Registry for Confluent Platform’ and ‘A dog ate my schema’.
The tool also comes with built-in schema registry authentication and schema registry security. This ensures only authorized users can view, register, or evolve schemas across environments. Lenses respects your Kafka Schema Registry authentication setup, providing visibility without compromising security.

Discover Lenses
For a unified experience across all your clusters, use Lenses.
Lenses can assist with topic data. But that's not all. It also offers benefits when it comes to schemas, connectors, processors, consumers, and Lenses SQL engine support.
These are all governed with centralized cross-cluster IAM, and can assist you in:
- Tackling your enterprise data management challenges
- Maintaining resilient streaming pipelines
- Allowing safe schema evolution
- Providing easy data discovery
Discover Lenses for Apache Kafka® FREE for Developers.





