By
Jun 17, 2020Antonios Chalkiopoulos

Antonios Chalkiopoulos
Data Engineers are forever flying the flag for open-source technology. But now that we’re safely locked away in our homes - potentially for the rest of the year - a new danger looms: That we get distracted by our new data tools and lose touch with delivering value to the business.
Today most Data Engineers around the world are working from home, and at first glance it may seem like this works. After all, a solid internet connection is all we need to carry on doing what we were doing... having the low-latency technologies at our fingertips to power all that distributed data.
Right?
Except that it’s not enough. The principles of Data Operations mean making data available to more than just a handful of the technical elite. So let’s consider the bigger picture:
Does your data platform check boxes for compliance and security across teams and technologies?
Can you identify repeatable and scalable best practices throughout the organization?
Does this approach enable cataloging, sharing and collaboration across teams and lines of business (even from the comfort of your living room)?
These three questions are fundamental in building a strategic data streaming landscape.
Although Platform teams are fighting the good fight whilst tending to the infrastructure, data democratization doesn’t come that easily. When holed up at home, it’s easy to forget that the important potential of technologies such as Kafka, Elasticsearch, etc. need to reach the front-line defences - and fast.
Are Data Platform teams losing touch with who we are - or should be - delivering to?
Data Operations is mainly communication… and communication requires both sender and source. It requires an in-depth understanding of the data - checking, then re-checking. Now, more than ever, we need to offer data consumers these things:
Observability over their apps and data
Operational capabilities that increase productivity
A solid path to production whilst meeting business requirements.
Our goal is to collaborate with domain experts in order to drive business outcomes; and doing this from a command-line and into a formless cyberspace just won’t cut it.
Take Babylon Health as a case in point. They’re excelling at seeing the bigger picture, understanding the role of their data mesh, and bringing the right clusters to the surface instantly; at a time when delivering healthcare data to medical professionals and patients can mean a matter of life or death. The ongoing crisis has changed the corporate landscape significantly - and not only for health-tech unicorns. Customers are behaving differently. The way companies operate has changed in lockstep. Working from home makes meetings less dynamic and it is harder to run into someone at the coffee machine (except perhaps those you live with).
At the office you’d have countless chance encounters and, as such, serendipities with different departments. They’d serve as more than social pleasantries - these encounters would give us a view into what is happening elsewhere and allow us to see potential overlaps between projects. Synergies if you must.
Now is the time to overcompensate with DataOps, asking ourselves and our data consumer colleagues the following questions: As a [Data Engineer | Data Scientist | Data Analyst | Software Engineer | Product Manager ] in the [Mortgages Team | Mobile Team | Data Team | Marketing Team etc..], how easily can I…
Discover available datasets, apps and insights?
Search metadata about a dataset or an app?
Explore raw or fairly unprocessed data?
Generate new datasets from existing data?
Create and share refined data and insights?
Ingest new data sources?
Deploy and monitor application logic?
Where democratizing data means making it more accessible and comprehensible to the data consumers in terms of its value, the next step is data socialization. Socializing data and apps is about offering total transparency, irrespective of positions or skills.
A data platform provides an opportunity to bring data and engineering AND business people together to create applications. For example:
A [ Business Manager | Analyst | Executive ] may not need to deeply understand [ Apache Kafka | Kubernetes | Microservices | ETL etc..], a high level of clarity will help them drive better business outcomes.
A look at a data initiative for a large retail bank in Europe shows some interesting results in socializing data technology.
They provided complete transparency over all data and apps in a real-time data platform for more than 1M customers whilst adhering to data ethics regulations such as the GDPR.
Although they were using Apache Kafka, OpenShift and spring-boot microservices, data socialization meant applying DataOps principles across people with high-and low-technology skill levels.
A set of simple and easy-to-remember data policies emerged that continuously monitored and masked sensitive data. Their ten different product and engineering teams started collaborating with increased efficiencies, identifying re-usable datasets and application logic. A data-mesh topology and common language were established to reveal how consumer networks operated - resulting in fewer outages, engaged business users and enhanced data quality.
Similar to the “three amigos” agile software method, DataOps brings the platform, business and development teams together to collaborate and deliver unprecedented outcomes:
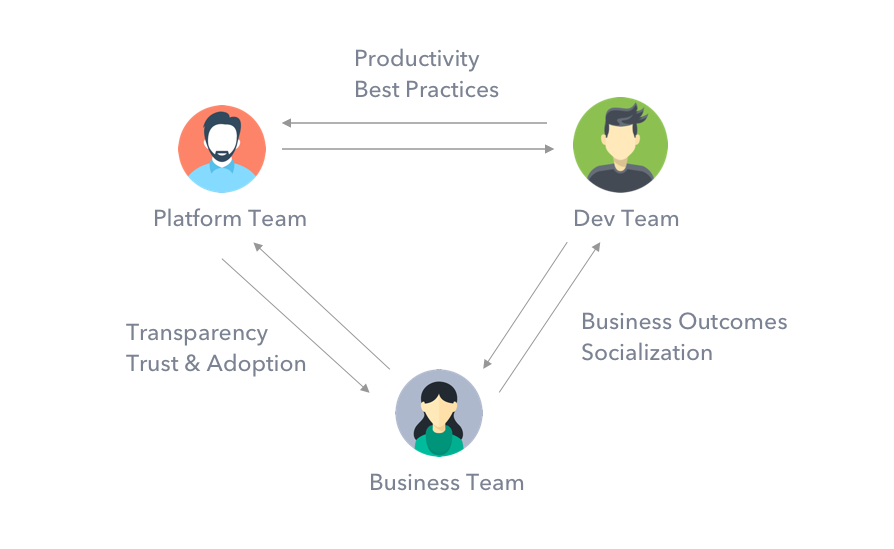
This social, open data and apps platform serves as a lighthouse model for one of the most highly data-ethical companies.
If you’re building or have built a data platform initiative using technologies like Apache Kafka or Kubernetes, you may have experienced some of the pains described above. When platform teams are socially distanced from the business, these pains can grow manifold - resulting in mismatched expectations, reduced application performance and stressed engineers. It can even mean fumbling in the dark for answers you need fast during a security breach, or an inability to appropriately socialize critical health records. These problems only become greater with distance. So yes, use open-source technologies, but alongside the mindset and collaborative experience needed to get your entire company onboard.
Having the ability to archive Kafka topic data is now essential. In th...
Mateus Henrique Cândido de Oliveira
The rise of hyperconnected data products....
Guillaume Aymé
Dec 20, 2024
How to write Protobuf-based Kafka producer & consumer microservices wi...
Eleftherios Davros
Mar 01, 2022






