

Mike Barlotta, Agile Data Engineer at WalmartLabs introduces how Kafka Connect and
Stream Reactor can be leveraged to bring data from Cassandra into Apache Kafka.
In the first part of this series (see Getting started with the Kafka Connect Cassandra Source),
we looked at how to get Kafka Connect setup with the Cassandra Source connector
from Lenses.io. We also took a look at some design considerations for the Cassandra tables. In this post we will examine some of the options we have for tuning the Cassandra Source connector.
Configuring when to start looking for data
The Cassandra Source connector pulls data from a Cassandra table based on a date/time column. The first property
we want to configure will tell the connector when it should start looking for data in the Cassandra table. This is
set with the connect.cassandra.initial.offset
published to the Kafka topic.
If this property is not set then the connector will use the default value of Jan 1, 1900. This is not what you will
want as it will cause long delays in publishing data to the Kafka topic. This delay is the result of the connector
having to work its way through more than a century of time slices before reaching your data. How fast it does this
will be determined by how some of the other properties are configured.
“connect.cassandra.initial.offset”: “2018-01-22 00:00:00.0000000Z”,
Once the connector has picked up data from the table and successfully published messages to Kafka it will store the
date/time of the last published row as an offset in the Kafka topic connect-offsets
to the topic the connector will always use it over the value provided by initial-offset
Configuring how often to check for data in the table
The connector works by polling the table and looking for new rows that have been inserted since it last checked for
data. How often to poll for data is managed by the connect.cassandra.import.poll.interval
shown below will look for new data every ten seconds.
“connect.cassandra.import.poll.interval”: 10000,
If the connector is still processing rows from the result set in the prior polling cycle, it will not query the table
for more data. That polling cycle will be skipped, at least in regards to querying the Cassandra cluster. The polling
cycle is still important as this also determines how often data is published to the Kafka topic.
How much data to handle on each polling cycle
One of the problems we initially had with the Cassandra Source connector was how much data it tried to process during
one polling cycle. In the original versions (0.2.5 and 0.2.6) the connector would retrieve all of the data that was inserted since the last polling cycle. For systems ingesting large amounts of data this can pose a challenge.
Our logs showed that it took 6 hours to retrieve and publish 6.8 million rows of data.
```
2017-06-05 15:51:36,891 … Processing results for blog.pack_events
…
2017-06-05 21:57:52,480 … Processed 6818008 rows for table blog.pack_events
```
The problem (or one of them) with this slow rate of ingestion was that the table was continuing to have new data
inserted into it while the connector was processing the data it had retrieved. With data being added to the table
faster than it was being published the connector was getting behind. Worse there was no opportunity for it to ever
catch up, until there was a lull in receiving new data.
To solve this problem, newer versions of the connector (0.4.0 and beyond) require the amount of data that is retrieved
to be limited to a defined slice of time. Rather than pull all of the data available since the last polling cycle,
the WHERE
the time range is configured using the slice.duration
that the time slice will span.
“connect.cassandra.slice.duration”: 120000,
The starting value for the time slice is the offset, which is the date/time of the last row in the table that was published. The ending value of the time slice is the starting value increased by the number of milliseconds specified in the slice.duration
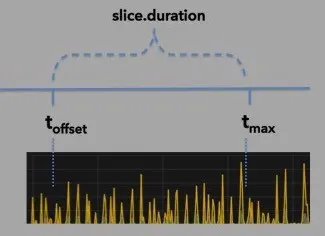
illustration 1: limiting data to a defined range of time
Even if more data is available in the table, only those rows that fall within the time slice will be retrieved and
published.
What if there is no data available within a polling cycle
Depending on how often data is inserted into the table, it is possible for an interesting situation to arise. There might not be any new data available when the connector executes the query during the next polling cycle. This is depicted in the illustration below.
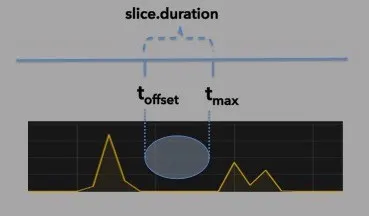
illustration 2: no data available
This can cause a problem. Since no new rows of data were published to Kafka, the offset, which determines the starting point of the time slice, did not change. This would result in the connector querying the same time range every polling cycle.
To get around this problem, the connector will increase the time slice when no rows are returned during the current polling cycle. To control how this is done, the connector will increase the maximum value in the time slice by the number of milliseconds specified in the connect.cassandra.import.poll.interval
until it retrieves and publishes data to the Kafka topic.
The illustration captures the next polling cycle that would occur, after the one depicted in illustration #2. Notice that the range of time in which the query attempts to retrieve data has increased.
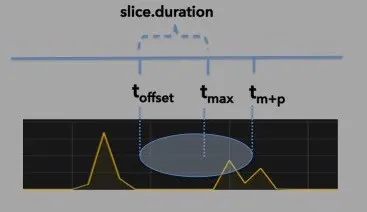
illustration 3: a larger time slice allows the connector to avoid looping over the same time range
Once the connector has retrieved data, the value in the offset is updated. Illustration #4 represents the polling cycle that occurs after the one depicted in illustration #3. Notice that there is a new offset (represented by t offset 2). This allows the time slice to revert to the normal range of time specified by the slice.duration
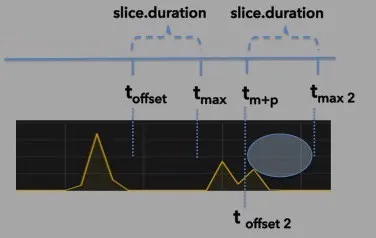
illustration 4: resetting the time slice
After running the polling cycle represented in illustration #4, we have a scenario in which we did not have data running through to the end of the time slice. This is depicted in illustration #5. Notice that the offset (t offset 3
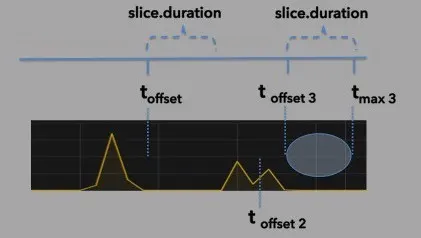
illustration 5: the stating time is always based on the value in the offset
Managing the internal buffer
The connector uses a LinkedBlockingQueue
SourceRecord
connect.cassandra.task.buffer.size
Each polling cycle, the connector will consume data from the internal queue and publish these messages to the Kafka topic. The maximum number of SourceRecords
connect.cassandra.batch.size
One of the other problems we initially encountered was having these values poorly configured. The connector was constantly filling the queue, but only a small amount of data was ever consumed during a polling cycle (see this issue for more details).
```
“connect.cassandra.task.buffer.size”: 10000,
“connect.cassandra.batch.size”: 5000,
```
Using the configuration settings above, a result set containing 200,000 rows would take 40 polling cycles to publish all of the data to Kafka. If the connect.cassandra.import.poll.interval
Making sure all of the data within a time slice is published
There is one more important property that can impact how well the connector runs. It is theconnect.cassandra.slice.delay.ms
the time range is allowed to get to the current date/time.
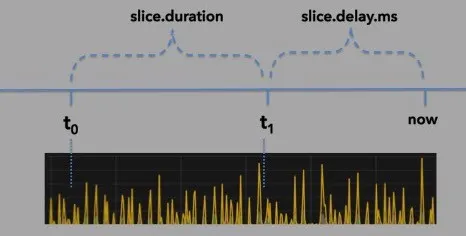
illustration 6: creating a delay between the current date/time and the end of the time range
The example below would make sure that there was always a 30 second gap between the current date/time and the maximum value of the time slice.
"connect.cassandra.slice.delay.ms": 30000,
This property is important because without a delay, or having the delay set too low, resulted in data persisted in Cassandra table not being published to the Kafka topic. For consumers relying on the events being published to the Kafka topic, they would complain about “lost” data. There are a couple causes for this behavior. The applications that
are responsible for inserting the data into the table are all running on different servers. These servers and the server running Kafka Connect may not be perfectly synchronized. If these are off then some of the servers could be inserting data into a time slice that Kafka Connect had already queried.
There may be some delay in Cassandra propagating the data through the cluster, which was running in two data centers. This could also result in the Kafka Connect query being run without access to all of the available data.
However, by providing a space of time between the end of the time slice and the current time we were able to run numerous load tests where all of the data in the table was published to Kafka.
Tuning and Testing
There are numerous configuration settings that can be used to tune the connector to perform well. Getting these right is important since the current approach limits the flow of data from Cassandra to a Kafka topic to one thread per table. Hopefully, this post has provided some insight into how they are used and how they affect each other. However, only through numerous functional and load tests will one be able to determine the settings that work best for their application and business needs.
Happy Tuning!
Part 1 of this set of articles is here
References
- Stream-Reactor GitHub project
- Kafka Connector documentation for Cassandra Source
- Kafka Connector documentation for Cassandra Sink
- This originally appeared on TheAgileJedi blog here





