By Guillaume Aymé
Jan 22, 2021Kafka to Splunk data integration flows for Security & IT
How to create data flows from Kafka to Splunk with Kafka Connect in a data mesh architecture


Splunk is a technology that made processing huge volumes and complex datasets accessible to security and IT teams.
Despite its strengths for monitoring and investigation, Splunk is a bit of a one-way street. Once it's in Splunk, it's not that easy to stream the data elsewhere in great volume. And it doesn’t mean it’s the best technology for all IT and Security use cases. Or the cheapest.
As a former Splunk employee, customers increasingly told me they wanted to decouple the data collection from the data storage and analytics.
One argument is fear of vendor lock-in.
But financial services in particular were leading the way in augmenting their analytics in Splunk with more sophisticated threat detection and AIOps. They did this by developing their own stream processing applications with frameworks such as Spark or augmenting Splunk with other IT and Security vendor technologies. Maybe a SOC uses Splunk but the CIRT uses open-source tools.
This meant data needed to be routed differently. In some cases, very dynamically, potentially upon an incident.
High value data for IT and security monitoring and investigation piped into Splunk. Low value data that didn't need real-time monitoring or indexing perhaps to S3. Specific sources to train and feed ML models routed to Databricks.
Or, for example, during a breach in progress, network packet data pipeline deployed routing to a temporary stack for an incident response team to do forensics. When the incident is resolved, the stack and pipeline is destroyed.
Even if all data were to all go into Splunk, which Splunk? Having a single, large, centralized Splunk platform run an infrastructure team sounded great, but in reality it was very hard to apply the right governance to satisfy so many internal use cases and customers. A network security monitoring team and a CIRT have very different requirements and types of workloads to run but may intersect in the data sources they process.
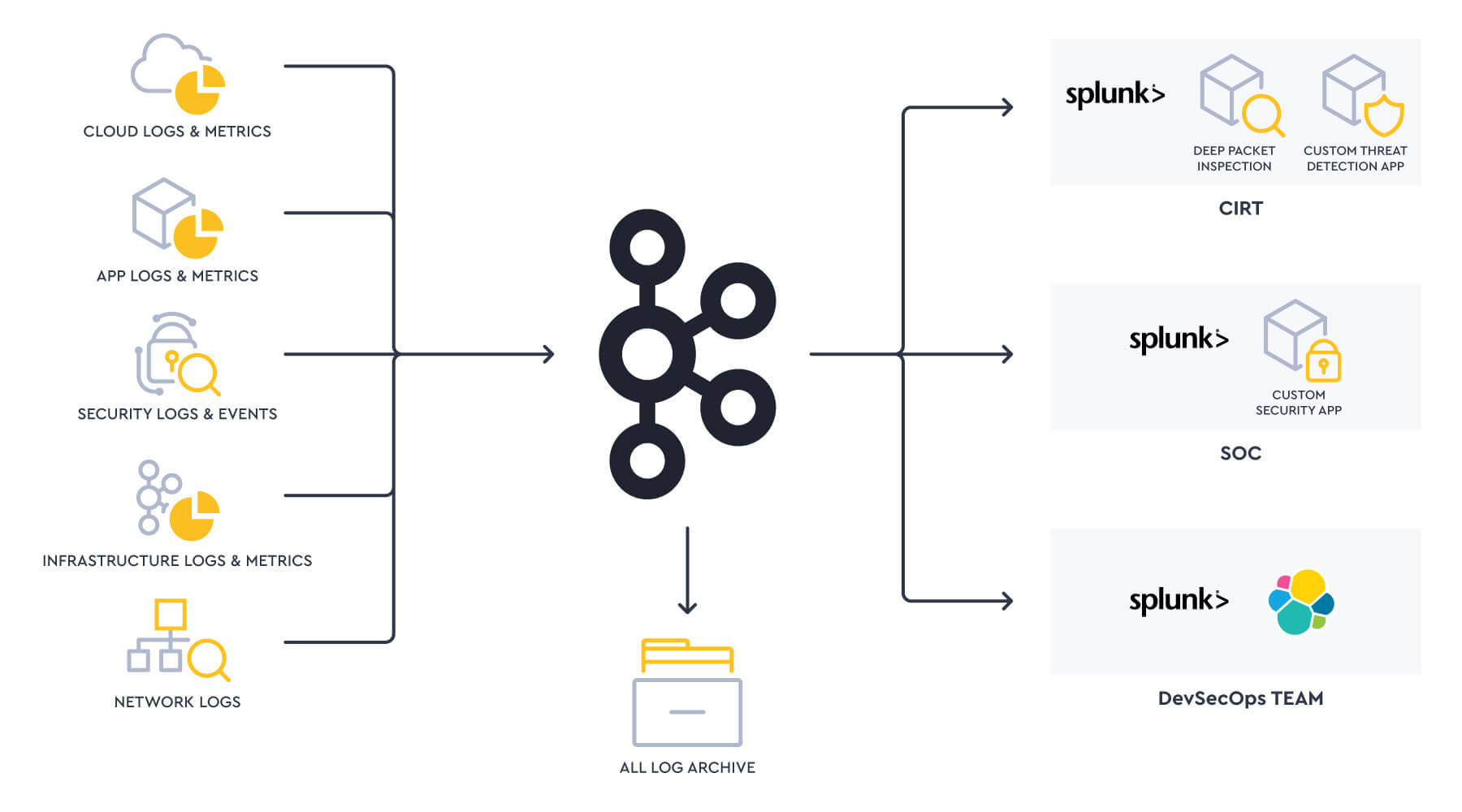
Instead, customers wanted to have a data mesh of Splunk and other data analytics technologies, run by different teams each with autonomy to use the technologies that best fitted their needs.
Of course, Splunk has a Data Stream Processor (DSP). This may be a good choice. But if your organization has already standardized on Kafka elsewhere in your organization, it may make sense to run your machine data and observability pipelines in Kafka.
Here's a video I made about stream processing data in Kafka and integrating into Splunk a while ago.
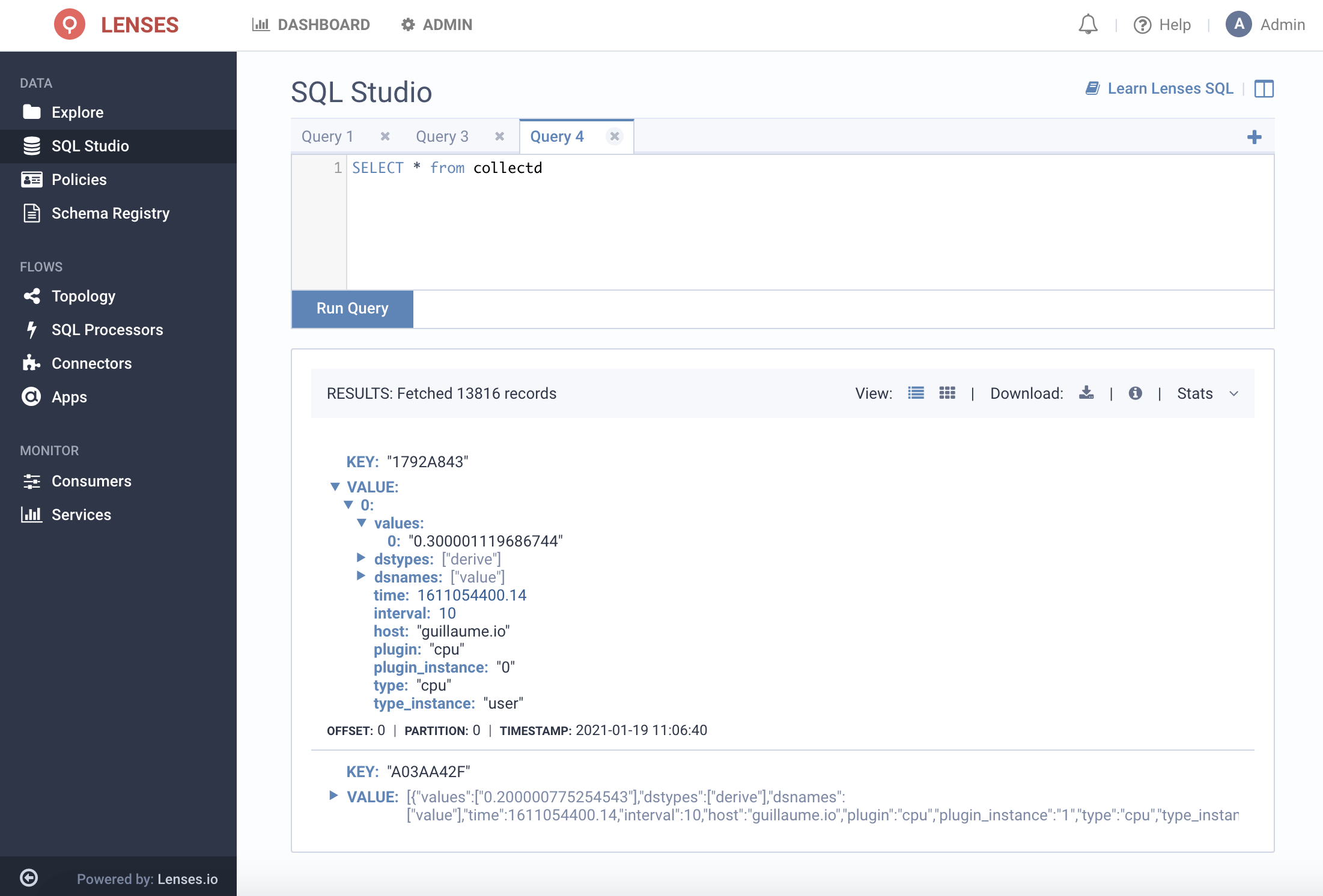
Let’s run through a scenario of collecting metrics from collectd agents into Kafka and building pipelines into the Splunk metrics store.
Lenses will be used as the means of managing the pipelines and data operations on Kafka.
Collectd can be configured by following this guide.
In my collectd.conf I configure the cpu and the write_kafka plugin, such as:
I'm sending data directly to Splunk from the agents as opposed to having an aggregation service such as Graphite.
If you need a localhost Lenses+Kafka environment, docker-run the the Lenses Box.
Remember to change the ADV_HOST
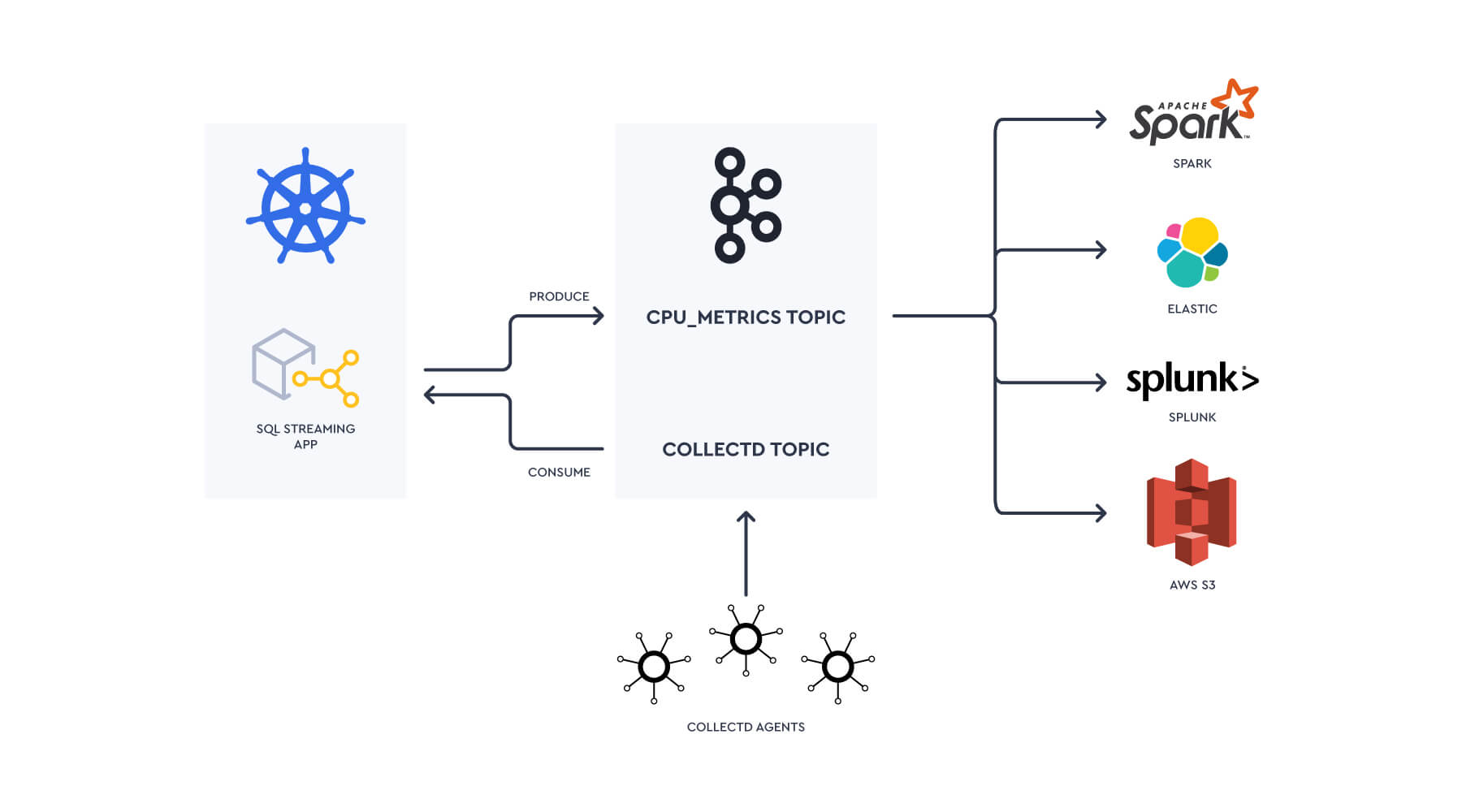
Now the data is in Kafka, building the pipelines into Splunk is where we start to hit some complexity:
Data will need to be pre-processed to reshape the data to be suitable for indexing in Splunk, potentially into the metrics store.
Need to deploy & manage a series of flows from Kafka to Splunk using the Splunk Kafka Connect connector.
Both of these come with operational data challenges that need to be addressed:
How to allow teams to deploy pipelines in self-service fashion
Adding governance to the process
Tracking data lineage
Where to run the workloads
Monitoring, alerting & troubleshooting the pipeline
Providing data access to troubleshoot where necessary
Maintaining many pipelines in a data mesh architecture would require DataOps tooling and practices.
This is where Lenses becomes particularly valuable: providing the governance and observability to operate these pipelines to Splunk.
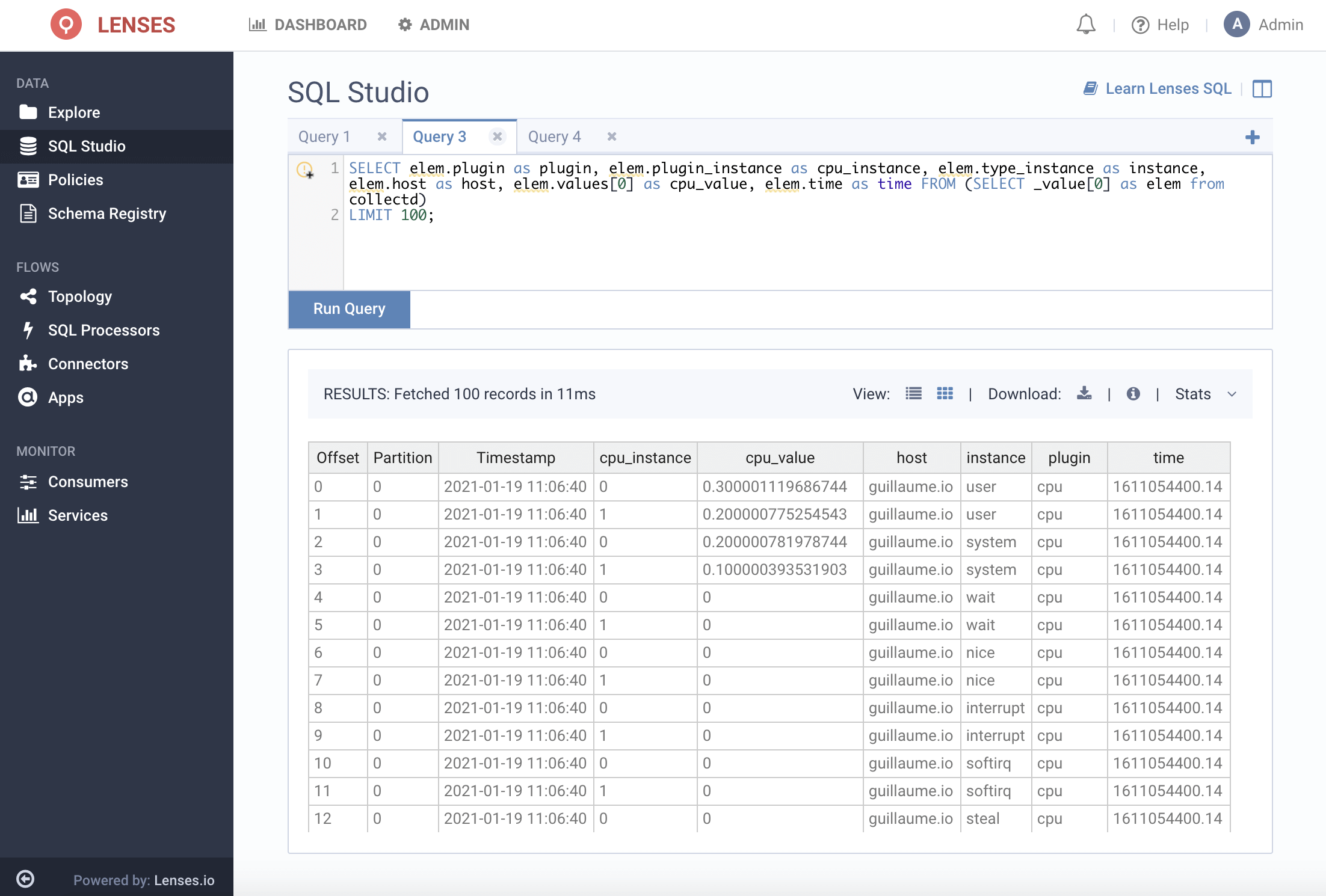
The data in the collectd topic will need to be flattened and reshaped.
The way data is structured by default, values are held as a JSON array at the root level which makes it slightly more tricky to structure.
This statement will flatten the array by taking the first index:
We can then extract the fields required from a subquery from the flattened array
The data in the previous step was queried in "Snapshot SQL" mode.
A Streaming SQL application can continuously process data into a separate topic named cpu_metrics.
In many cases you may wish to enrich the data by joining on a KTable. Checkout the Streaming SQL Cheatsheet for more advanced examples.
Lenses will build and deploy a KStreams application from this SQL. The workload can run on Kubernetes or your Kafka Connect cluster. If you're using Box, you can run it within the Lenses container.
Either way, Lenses will handle the deployment to your infrastructure, saving you the need to develop your own CI/CD pipelines.
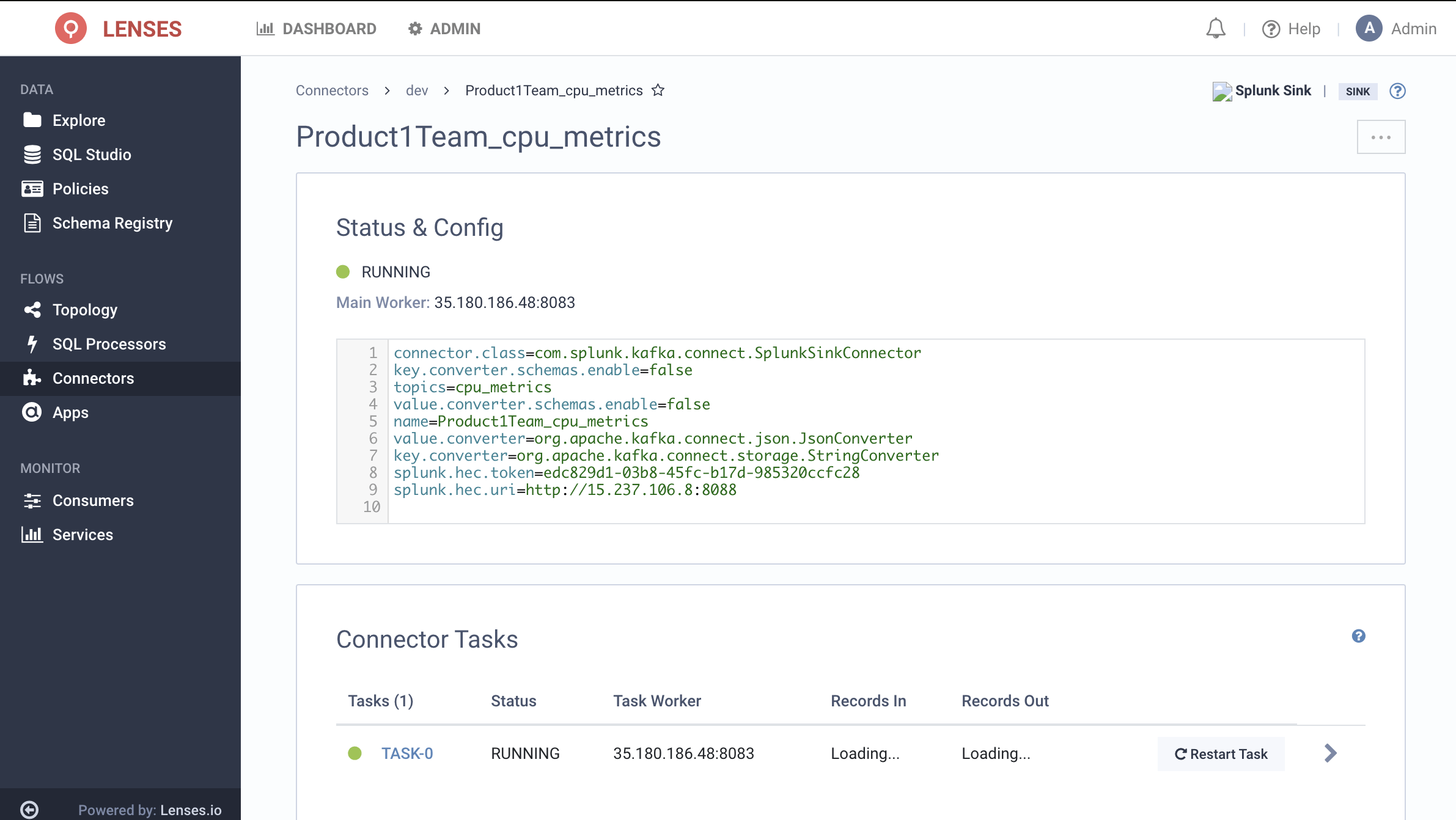
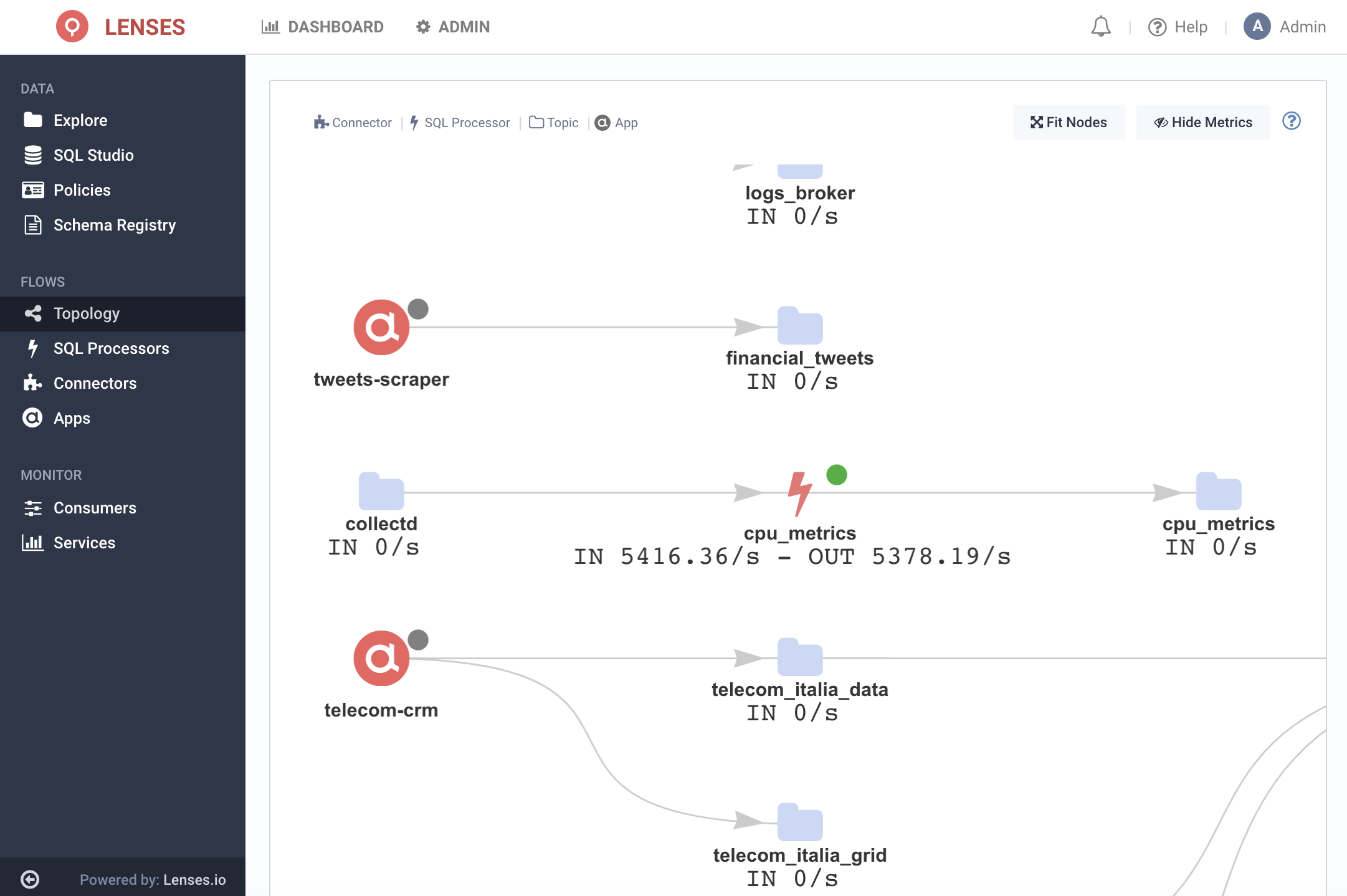
A view of the topology will confirm the pipeline:
The final step is to deploy Kafka Connect flows using the Kafka Connect Connector for Splunk.
If you're using your own Kafka Connect cluster, reference the connector in the plugin.path when running Connect. If you're using Box, the Connector is imported by default.
The Splunk Kafka Connector requires a HEC token to be created in Splunk.
This will be deployed on your existing Kafka Connect cluster.
What would be more effective would be to use the Lenses CLI client using a Service Account configured with RBAC (applying privileges to consume off certain topics). Or alternatively adopt GitOps practices to automate deployment through a Git repository.
This way, different product teams and feed their own instance of Splunk as they wish without dependence on a centralised team.
The CLI would be:
A quick check in Splunk to verify the data flow.
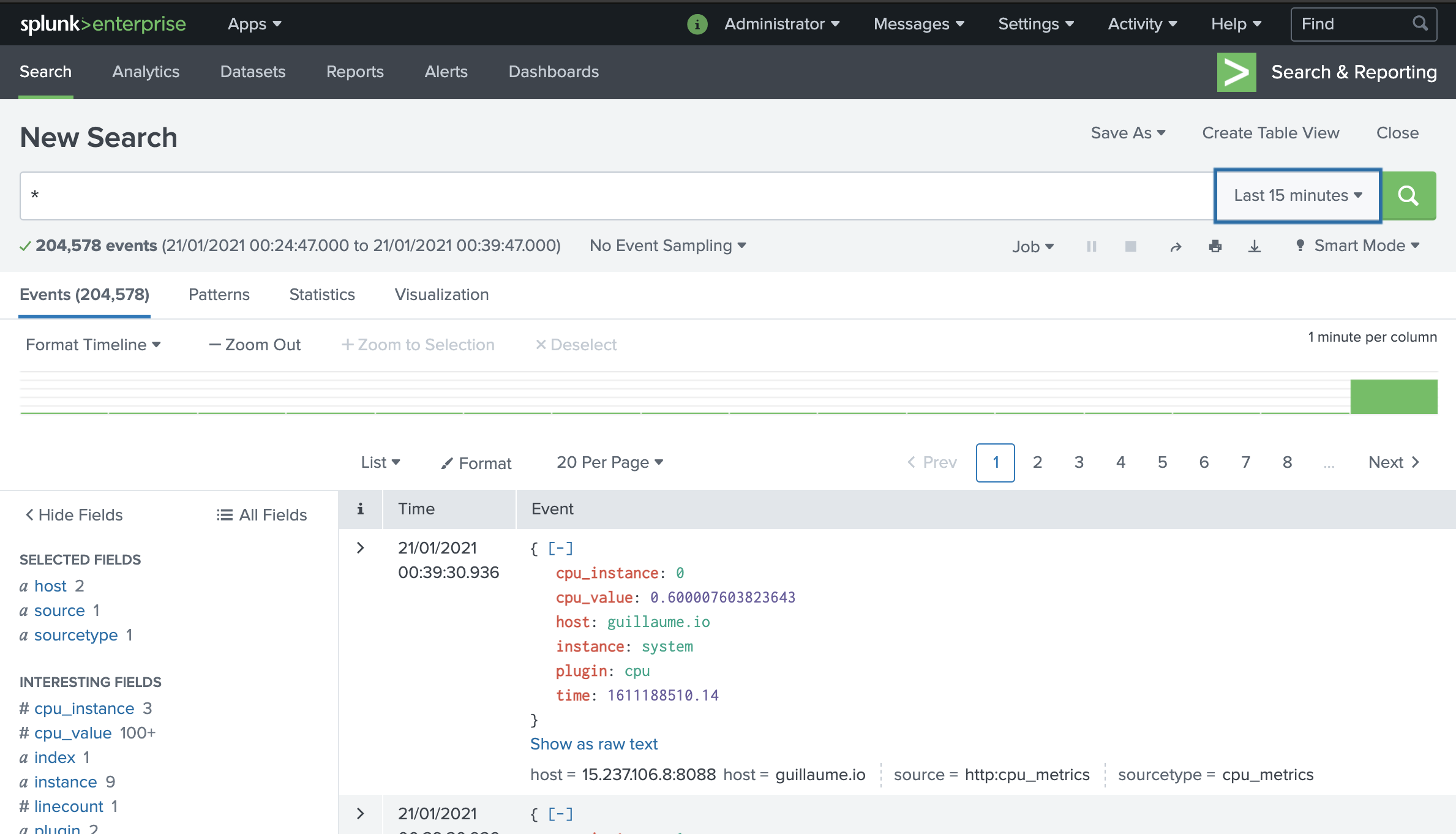
Ideally, in this case I would have configured the HEC token to push to the metrics store rather than the traditional index.
Building a Kafka to Splunk architecture? Reach out to our experts for advice and best practices.
Reasons and challenges for Kafka replication between clusters, includi...
Andrew Stevenson




