

MQTT stands for MQ Telemetry Transport. It is a lightweight messaging protocol,
designed for embedded hardware, low-power or limited-network applications and
micro controllers with limited RAM and/or CPU. It is a protocol that drives
the IoT expansion.
On the other hand, large numbers of small devices that produce frequent readings,
lead to big data and the need for analysis in both time and space domain (spatial-temporal
analysis). Kafka can be the highway that connects your IoT with your backend
analytics and persistence.
In this context, we are gonna see how Kafka Connect can be utilized to transfer MQTT
messages into Kafka using the Datamountaineer mqtt-connector; and what performance can be
achieved.
AIS is an automatic tracking system used for collision avoidance for water transport.
The ships around the world send real time status messages to AIS in order to allow other ships
to view marine traffic in their area and to be seen by that traffic. We pick this dataset for
our example because volumes are big and the messaging stream is continuous. This will help
us demonstrate a use case that fits the IoT paradigm as well as explore what
is happening in the oceans!
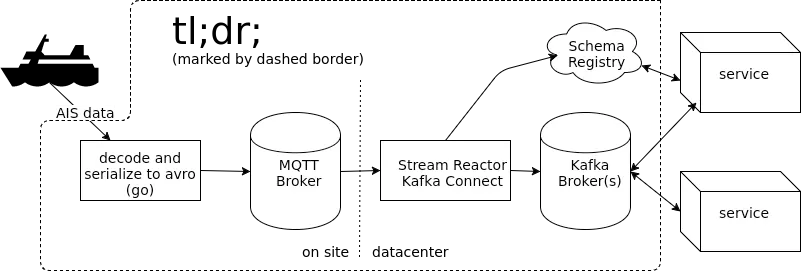
For the purpose of this post we wrote a small go program that encodes AIS position
data to Avro and sends them to an MQTT broker. Avro is the recommended message format
for kafka and relies on schemas to define the data contract, allows schema evolution
and provides efficient serialization of the data. In this example we use avro, but
the connector can also handle JSON. The code used for this article can be found at
our github
Let’s start by setting up an MQTT connector. We can either use a Kafka Connect
standalone worker, or use Kafka Connect in distributed mode which is the
recommended configuration for production. We will choose the latter but the
former is as simple.
If you don’t have a Kafka and/or MQTT installation, we have prepared
a docker image which includes
Kafka, Schema Registry, Connect Distributed and ActiveMQ as well as our
AIS decoder. If you are on macOS it is prudent to assign at least 4GB of RAM to docker
for this demo. You may run it as:
docker run -p 3030:3030 --rm --name=example-mqtt landoop/example-mqtt
It will expose a web interface at http://localhost:3030
If you have access to a Kafka cluster and are interested to run the example
there, the first step would be to add the Datamountaineer MQTT connector to the
classpath of your Connect workers. You can download the latest from
Stream Reactor’s release page.
Please note that you should choose an appropriate variant for your Connect
version.
To add it to the classpath of your connect, you may either export the
environment variable CLASSPATH
your Kafka installation directory, create a new directoryshare/java/kafka-connect-mqtt
there. Once you perform one of these actions, restart Connect. If your cluster
has many Connect workers, you need to make the connector available to all of
them.
Connect distributed provides a REST API where we can create new connectors,
destroy existing ones, pause them etc. If you prefer your API orchestrated by a
good UI, we have build
Kafka Connect UI to
let you manage your connectors from an intuitive web interface. For this
tutorial though, we will stick with the REST API of Connect.
The connector configuration for our docker container is below. If running on your
own infrastructure, you will have to adjust the MQTT server address and possibly
the location of the Avro schema. We have to provide the Avro schema as an external
file, since there isn’t a way to get the schema from MQTT or create it on the fly.
Should we chose to use JSON instead of Avro, there would be a performance expense as
JSON needs more bandwidth to transfer (it is text based and every entry contains the schema)
and the connector would have to verify the schema for each entry in case it changed
and convert the message to Avro.
```
{
"name": "mqtt-source",
"config": {
"connector.class": "com.datamountaineer.streamreactor.connect.mqtt.source.MqttSourceConnector",
"tasks.max": "1",
"topics": "position-reports",
"connect.mqtt.connection.clean": "true",
"connect.mqtt.connection.timeout": "1000",
"connect.mqtt.kcql": "INSERT INTO position-reports SELECT * FROM /ais WITHCONVERTER=`com.datamountaineer.streamreactor.connect.converters.source.AvroConverter`",
"connect.mqtt.connection.keep.alive": "1000",
"connect.source.converter.avro.schemas": "/ais=/classAPositionReportSchema.json",
"connect.mqtt.client.id": "ais-mqtt-connect-01",
"connect.mqtt.converter.throw.on.error": "true",
"connect.mqtt.hosts": "tcp://localhost:1883",
"connect.mqtt.service.quality": "1"
}}
```Most fields should be self explaining. At connect.mqtt.source.converters
set a converter class per MQTT topic to convert the MQTT messages to Kafka
messages. The AvroConverter validates the messages to the given schema (set byconnect.source.converter.avro.schemas
sends them as is to Kafka. Also it registers the schema to the Schema
Registry. There are 3 more converters, with the most interesting one being the
JSON converter. You can also write your own converters. You may learn more about
the MQTT connector at its documentation page
Of special interest is the connect.mqtt.source.kcql
Kafka Connect Query Language (KCQL)
was created to help with the difficult task of mapping topics
and fields to Connect’s sinks structures (databases, tables, field names, tags,
etc) and vice versa —complex mapping from sources to topics.
Returning to our example, we can post the connector at Connect’s REST API. We
include the configuration file in the docker image, so you may run:
```
docker exec example-mqtt \
curl -v \
-X POST \
-H "Content-Type: application/json" \
--data @/mqtt-source.json \
"http://localhost:8083/connectors"
```Also it would be prudent to create our test topic which we named position-reports:
```
docker exec example-mqtt \
kafka-topics \
--zookeeper localhost:2181 \
--topic position-reports \
--partition 1 \
--replication 1 \
--create
```You can visit the
Connect UI
that runs inside the container to check your connector status.
Now we are ready to write some messages to the MQTT broker (implemented by
ActiveMQ) and let the connector move them to the Kafka broker.
```
docker exec example-mqtt \
time -p /opt/go/bin/ais-mqtt
```You can use the Kafka Topics UI and visit the
kafka-topics-ui/#/cluster/fast-data-dev/topic/n/position-reports/tableUI
that runs on the container.
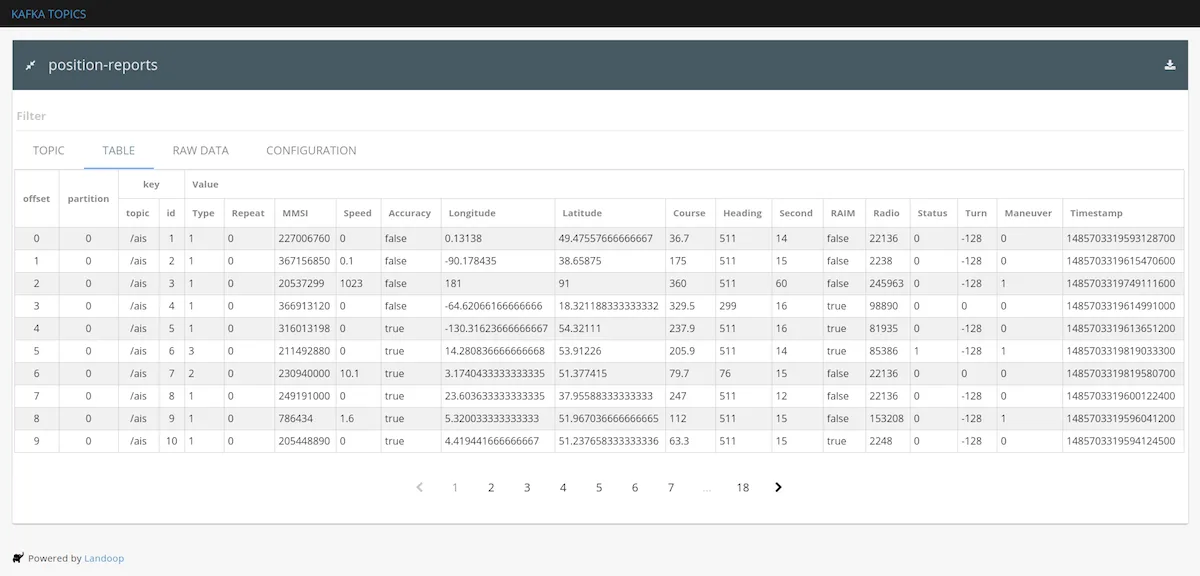
If you are on your own infrastructure, you could run the AIS message generator
by adjusting the MQTT server address.
```
docker run --rm -it \
--entrypoint /opt/go/bin/ais-mqtt \
landoop/example-mqtt \
-server <MQTT_BROKER_URL>:1883
```Other notable options are -messages
(default 100,000) and -workers
messages in parallel (default 64).
Another way to verify that messages are delivered correctly, is to use thekafka-avro-console-consumer
used the docker image for example, you could run:
```
docker exec example-mqtt \
kafka-avro-console-consumer \
--bootstrap-server localhost:9092 \
--topic position-reports \
--from-beginning \
--new-consumer \
--max-messages 10 \
--property schema.registry.url=http://localhost:8081
```Performance
When operating in scale, performance is important. Although the only
real world benchmark you can have is your real world performance, we will
mention some numbers from our setup to help you get an idea of what you
can reasonably expect.
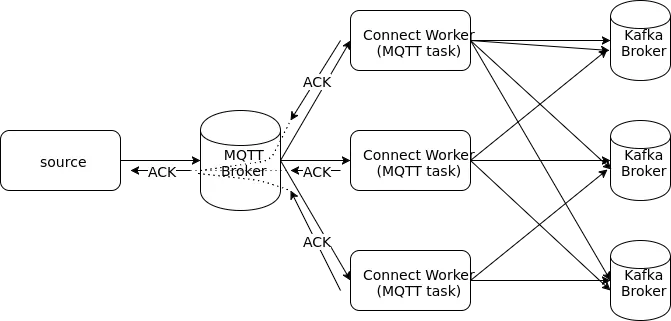
In order for the connector to work reliably, we have to set the QoS for MQTT
to 1. This translates to deliver exactly once. So our source sends a message
to MQTT, MQTT pushes the message to a Kafka Connect worker and once it confirms
delivery, sends back an ACK to the source so it can proceed with the next
message. The message pathway is shown in the figure below. All our numbers are
esentially for this whole pipeline.
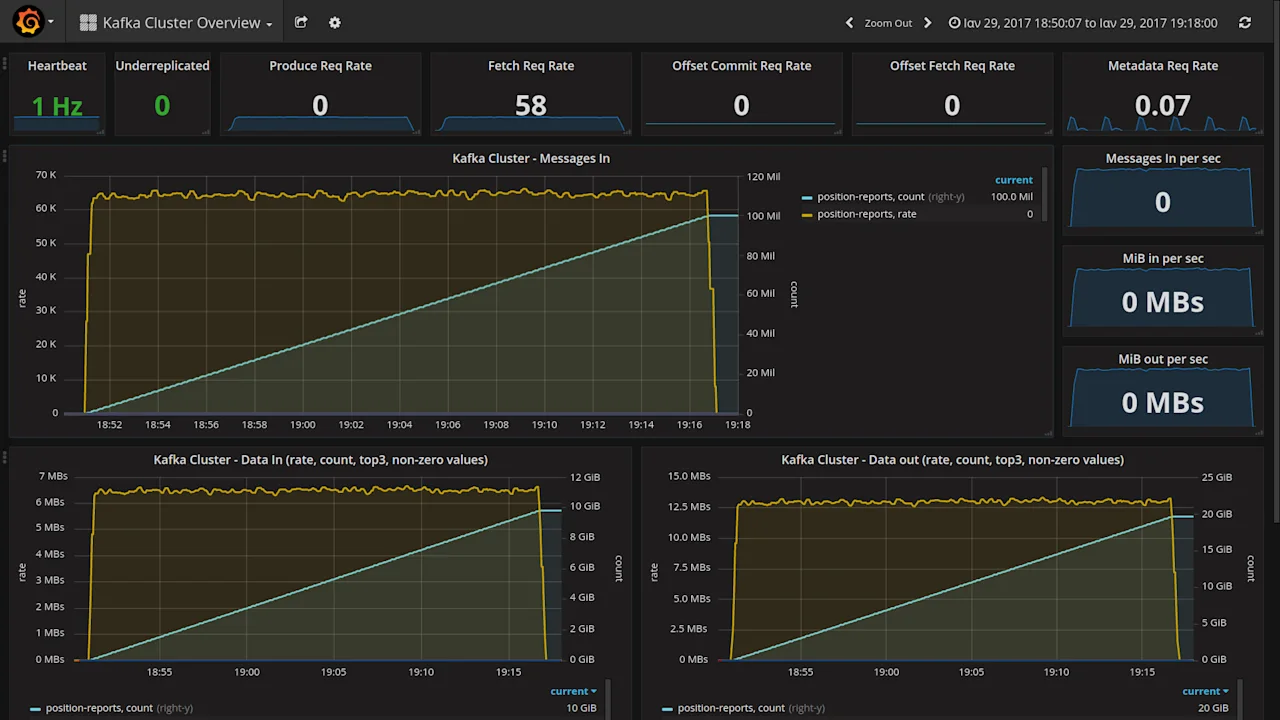
Running the demo on a laptop (Intel i7-3630QM, 16GB RAM), gives about 30,000
msg/sec. Running the demo on our Kafka Cluster which consists of 3 fairly large
nodes (128GB RAM, 2× Intel Xeon E5-2620) whilst keeping only one MQTT broker,
doesn’t give us much of an improvement, but can maintain an average rate of
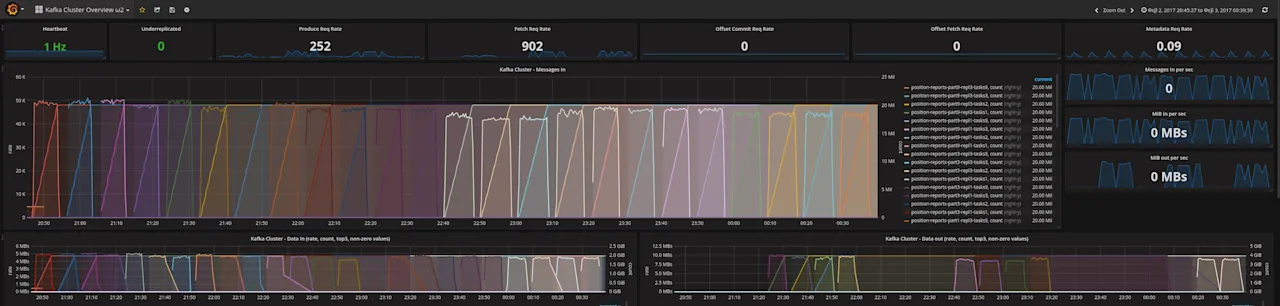
about 65,000 messages / second (about 6.55MiB / second) for a very long time, as
you can see in our Grafana screenshot below. Also in the cluster we do use 9
partitions and a replication factor of 3.
If we used the go program to write directly to the brokers, we would get an
order of magnitude more messages (about 600,000 / sec), so the delay isn’t
at message decoding and Avro serialization.
Another test we ran, was to test various setups (vary number of partitions, number
of connect tasks, replication). We didn’t see significant variation as shown below.
We didn’t perform any extensive profiling, but we believe that this is more of a
network programming issue. As stated we use a QoS of 1 for MQTT, which means
that our go code workers wait for delivery confirmation for each message before
sending the next. This is the most robust way to send messages as well as the
suggested one. So the go program waits for delivery confirmation from MQTT,
which waits for the connector to receive and acknowledge the messages. This
leads us to believe that the performance could scale almost linearly to at least
500,000 messages / sec just by adding more MQTT brokers that would work together
or independently. In the case of IoT this is a very probable scenario; multiple
MQTT gateways positioned at different parts of your infrastructure.
That is all for today. I hope you did find some interesting parts in this
article.
Marios.





