By
Oct 16, 2025Andrew Stevenson

Andrew Stevenson
Apache Kafka and its many flavours (Confluent Cloud, Redpanda, Aiven, etc.) give decoupled systems the ability to instantly respond to real-time events. (PS: Too often, the industry has reduced Kafka to just an analytics or stream-processing tool. Its real-time operational potential is easily forgotten.)
Imagine an airline system monitoring traffic around an airport. If it detects a major delay, countless systems may need to react instantly:
Mobile apps to warn passengers to leave earlier.
Scheduling tools to consider delaying flights.
Crew systems to reallocate staff.
Check-in teams to add capacity.
Ground operations to adjust flows. Some of these systems will still connect via API, traditional MQ or iPaaS technologies, but the data’s volume and urgency and the ease of decoupling apps make architecting with Kafka the better fit. The natural question is: should all these applications & systems connect to the same Kafka cluster? And should all clusters come from the same vendor?
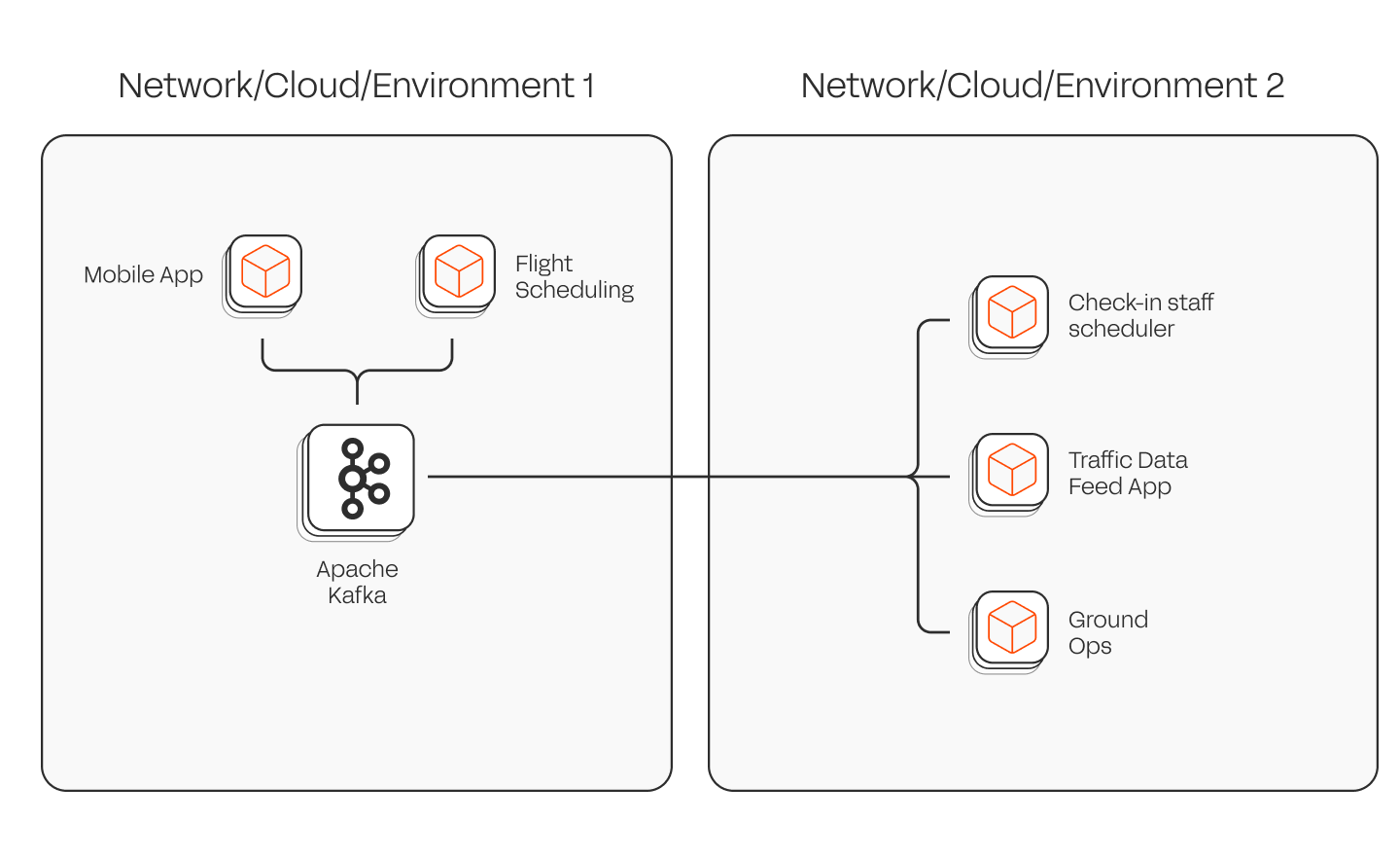
The reality: the more applications you connect, the harder governance gets. A single set of policies rarely fits all workloads or regulatory needs. Troubleshooting and isolating issues (“noisy neighbours”) also become complex. Maintenance windows require more coordination. In large enterprises with multiple IT teams, it’s impossible to avoid having multiple clusters. In some cases, having a single cluster may cost more in network bandwidth if there are multiple applications consuming from the same topic but live in different networks (as shown in diagram below). In short: a single, central Kafka platform becomes brittle at scale. And in my opinion, has never worked. The alternative is a multi-Kafka strategy: to isolate applications onto different Kafka clusters, depending on their profile, who owns them or their governance requirements.
With a set of clusters, data fragments. For developers, this is frustrating: they just want a unified way to discover and work with streaming data. This is especially the case if the set is a mix of different flavours (Confluent Cloud, Confluent Platform, MSK, opensource, …).
If Flight Scheduling App needs data from the Traffic Data Feed App but they live in different clusters, replication will be required. Network costs could be impacted, but within the same DC/AZ/Geo that’s not usually an issue. And depending on the number of applications and where those applications are running, network costs could actually be lower.
Multiple clusters may appear more expensive than one. But being able to scale up/down clusters based workload often balances costs. The trade-off isn’t simple, too many clusters add operational overhead, too few creates bottlenecks and may require oversizing infrastructure.
Lenses, with its AI capabilities, addresses the challenges when adopting a multi-Kafka strategy.
Lenses delivers a *native multi-Kafka developer experience*. Developers get a single, unified way to find, govern, process, and integrate data across fleets of clusters (up to thousands in some customer environments). No cluster drill-down required. This includes support for different cluster flavours: non-critical apps on open-source Kafka, critical workloads on Confluent Cloud, for example.
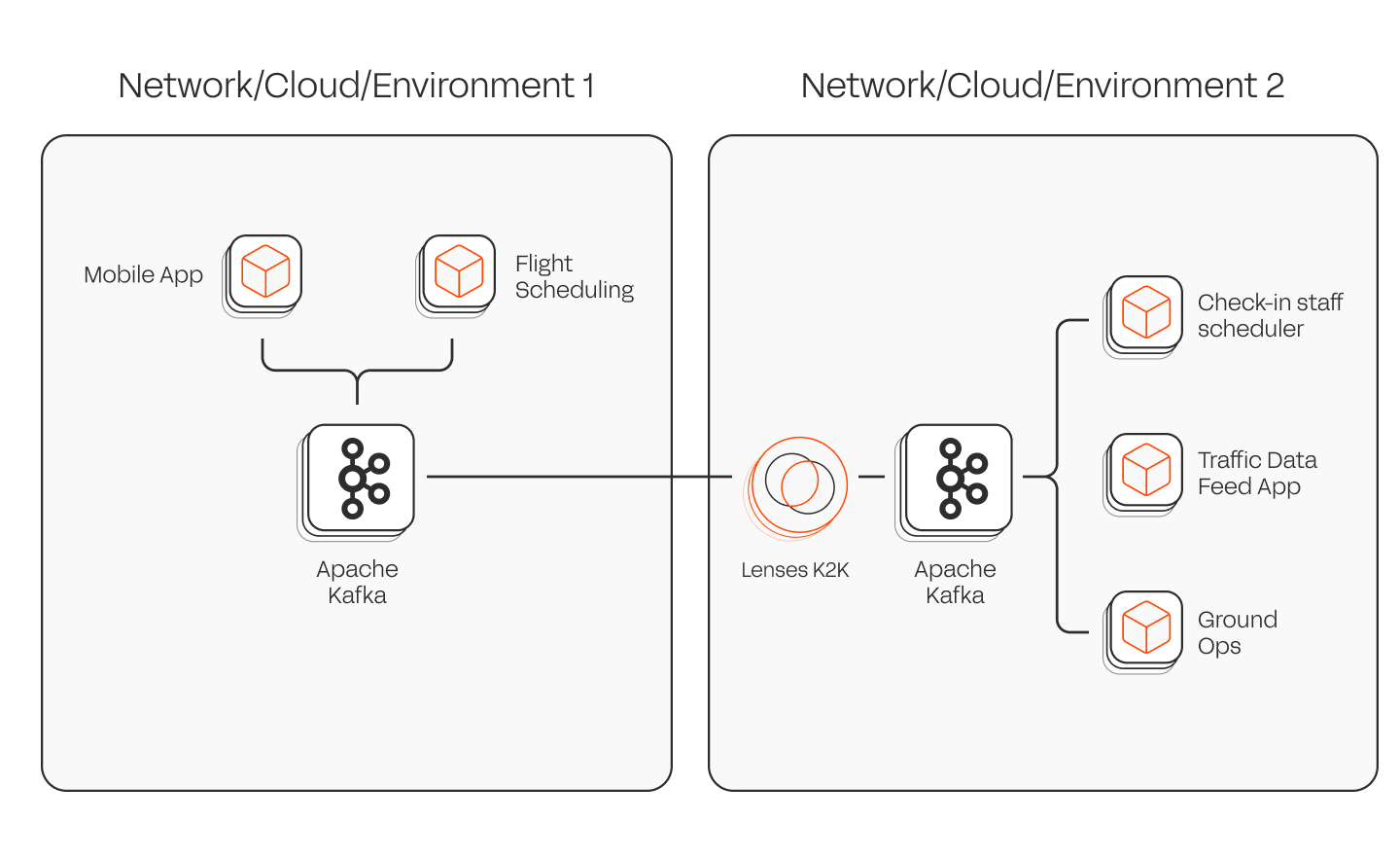
Lenses 6.1 introduces **K2K**, vendor-neutral Kafka replicator. It can run independently of Lenses and integrate into your CI/CD pipeline. The benefits: freedom for engineers to replicate data across different clusters instantly. This means data can easily be shared across different applications, even if they live in different clusters.
A multi-Kafka native view with Agentic AI capabilities makes governance and hygiene effortless. Allow an human or AI Agent to find empty topics, duplicates, test data, unused datasets, all easily surfaced and eliminated. The result: lower costs, especially in high-priced environments like Confluent Cloud. That’s why hundreds of businesses rely on Lenses for their multi-Kafka strategy.
Offsets: Replication vs Translation...
Drew Oetzel
Common Gotchas from the Field...
Drew Oetzel





